什么是机器学习?
机器学习起源于数据的统计和数学建模。 机器学习的基本理念是使用过去观测到的数据来预测未知的结果或值。 例如:
- 冰淇淋店的老板可能会使用某个应用,结合历史销售和天气记录,根据天气预报来预测他们在某一天可能会售出多少个冰淇淋。
- 医生可能会使用以往患者的临床数据来运行自动测试,以根据体重、血糖水平和其他测量值等因素来预测新患者是否有患糖尿病的风险。
- 南极研究人员可能会利用过去的观测值,根据鸟类脚蹼、喙和其他物理属性的测量,自动识别不同的企鹅物种(例如阿德利企鹅、白眉企鹅或帽带企鹅)。
机器学习作为一种函数
由于机器学习基于数学和统计学,因此通常会使用数学术语来思考机器学习模型。 从根本上讲,机器学习模型是一种软件应用程序,它封装一个函数用于根据一个或多个输入值计算输出值。 定义该函数的过程称为训练。 定义函数后,可以使用它在称为“推理”的过程中预测新值。
让我们探讨一下训练和推理所涉及的步骤。
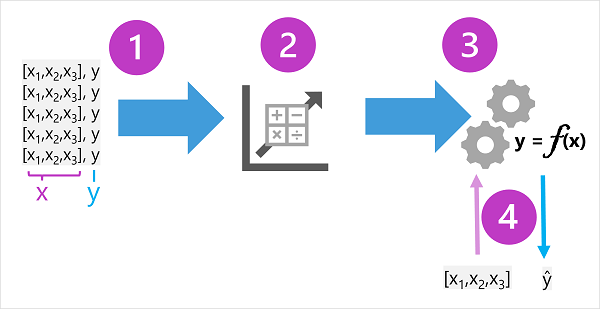
训练数据由过去的观测值组成。 在大多数情况下,观测值包括观测到的事物的属性或特征,以及要训练模型来预测的事物的已知值(称为标签)。
在数学术语中,你经常会看到使用速记变量名称 x 引用的特征,以及使用 y 引用的标签。 通常,观测值由多个特征值组成,因此 x 实际上是一个向量(包含多个值的数组),如下所示:[x1,x2,x3,...]。
为了澄清这一点,让我们分析前面所述的示例:
- 在冰淇淋销售场景中,我们的目标是训练一个可以根据天气预测冰淇淋销售数量的模型。 当天的天气测量值(温度、降雨量、风速等)是特征 (x),每日售出的冰淇淋数量是标签 (y)。
- 在医疗场景中,目标是根据患者的临床测量值预测患者是否有患糖尿病的风险。 患者的测量值(体重、血糖水平等)是特征 (x),患糖尿病的可能性(例如,1 表示有风险,0 表示没有风险)是标签 (y)。
- 在南极研究场景中,我们希望根据企鹅的物理属性来预测其物种。 企鹅的关键测量值(脚蹼的长度、喙的宽度等)是特征 (x),物种(例如,0 表示阿德利企鹅,1 表示白眉企鹅,2 表示帽带企鹅)是标签 (y)。
将对数据应用某种算法,以尝试确定特征与标签之间的关系,然后泛化这种关系,以便针对 x 执行计算来计算 y。 使用的具体算法取决于要解决的预测问题的类型(稍后会详细介绍),但基本原则是尝试将一个函数拟合到数据,其中的特征值可用于计算标签。
算法的结果是一个模型,该模型将算法派生的计算封装为函数 - 我们称之为 f。 采用数学表示法:
y = f(x)
完成训练阶段后,训练的模型可用于推理。 模型本质上是一个软件程序,可以封装训练过程生成的函数。 你可以输入一组特征值,并接收相应标签的预测结果作为输出。 由于模型的输出是函数计算的预测值而不是观测值,因此你经常会看到函数的输出显示为 ŷ(戏称为“y-hat”)。