描述规范化
数据库规范化是一种设计过程,用于将一组给定的数据组织到数据库中的表和列中。 每个表都应包含与特定“事物”相关的数据,并且仅具有支持该表中包含的相同“事物”的数据。 此过程的目标是减少数据库中包含的重复数据,从而减少数据库插入和更新时的性能下降。 例如,如果客户地址的唯一存储位置位于 Customers 表中,则更容易实现客户地址更改。 最常见的规范化形式是第一、第二和第三范式,如下所述。
第一范式
第一范式具有以下规范:
- 为每组相关数据创建一个单独的表
- 消除单个表中的重复组
- 使用主键标识每组相关数据
在此模型中,不应在单个表中使用多个列来存储相似的数据。 例如,如果产品可以有多种颜色,则一行中不应具有包含不同颜色值的多个列。 下方第一个表 (ProductColors) 不是第一范式,因为存在重复的颜色值。 对于仅一种颜色的产品,会浪费空间。 如果产品的颜色超过三种,该怎么办? 不必设置最大颜色数,而是可以重新创建表,如第二个表 ProductColor 所示。 对第一范式还有一个要求,即表必须有一个唯一键,该键是一个(或多个)列,其值唯一地标识该行。 第二个表中的两个列都不是唯一的,但是合在一起,ProductID 和 Color 的组合是唯一的。 当需要多个列时,我们称其为组合键。
| ProductID | Color1 | Color2 | Color3 |
|---|---|---|---|
| 1 | 红色 | 绿色 | 黄色 |
| 2 | 黄色 | ||
| 3 | 蓝色 | Red | |
| 4 | 蓝色 | ||
| 5 | Red |
| ProductID | 颜色 |
|---|---|
| 1 | Red |
| 1 | 绿色 |
| 1 | 黄色 |
| 2 | 黄色 |
| 3 | 蓝色 |
| 3 | Red |
| 4 | 蓝色 |
| 5 | Red |
第三个表 ProductInfo 采用第一范式,因为每一行都表示一个特定的产品,没有重复的组,并且有 ProductID 列用作主键。
| ProductID | ProductName | Price | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | 小组件 | 15.95 | 美国 | US |
| 2 | Foop | 41.95 | 英国 | 英国 |
| 3 | Glombit | 49.95 | 英国 | 英国 |
| 4 | Sorfin | 99.99 | 菲律宾共和国 | RepPhil |
| 5 | Stem Bolt | 29.95 | 美国 | US |
第二范式
除了第一范式所要求的规范外,第二范式还具有以下规范:
- 如果表具有组合键,则所有属性都必须依赖于完整的键,而不仅仅依赖于键的一部分。
第二范式仅与具有组合键的表相关,例如上面的第二张表 ProductColor 表。 考虑一下 ProductColor 表还包含产品价格的情况。 该表具有 ProductID 和 Color 的组合键,因为只有同时使用这两个列值,才能唯一地标识一行。 如果产品的价格未随颜色变化,则可能会看到如下表所示的数据:
| ProductID | 颜色 | Price |
|---|---|---|
| 1 | Red | 15.95 |
| 1 | 绿色 | 15.95 |
| 1 | 黄色 | 15.95 |
| 2 | 黄色 | 41.95 |
| 3 | 蓝色 | 49.95 |
| 3 | Red | 49.95 |
| 4 | 蓝色 | 99.95 |
| 5 | Red | 29.95 |
上表不是第二范式。 价格值依赖于 ProductID,而不依赖于颜色。 ProductID 1 有三行,因此该产品的价格重复了三次。 违反第二范式的问题在于,如果必须更新价格,则必须确保在所有地方都进行更新。 如果更新第一行中的价格,但不更新第二行或第三行中的价格,则会出现称为“更新异常”的内容。 更新之后,将无法确定 ProductID 1 的实际价格是多少。 解决方法是将 Price 列移动到将 ProductID 作为单个列键的表,因为该列是 Price 唯一依赖的列。 例如,可以使用 Table 3 来存储 Price。
如果产品的价格因颜色而异,则第四张表将采用第二范式,因为价格同时依赖于键的两个部分:ProductID 和 Color。
第三范式
第三范式通常是大多数 OLTP 数据库的目标。 除了第二范式所要求的规范外,第三范式还具有以下规范:
- 非键列对主键不存在传递性依赖。
传递关系意味着表中的一列通过第二列与其他列相关。 依赖项意味着列可以从另一个列派生其值,这是依赖项的结果。 例如,可以从出生日期确定年龄,从而使年龄依赖于出生日期。 返回到第三张表 ProductInfo。 该表为第二范式,但不是第三范式。 ShortLocation 列依赖于 ProductionCountry 列,后者不是键。 与第二范式一样,违反第三范式也会导致更新异常。 如果在一行中更新了 ShortLocation,但没在出现该位置的所有行中对其进行更新,那么最终将导致数据不一致。 为避免出现这种情况,可以创建一个单独的表来存储国家/地区名称及其缩写形式。
非规范化
尽管从理论上讲第三范式是理想的,但并非所有数据都适用。 此外,规范化的数据库并不能始终提供最佳性能。 通常,规范化的数据需要多次联接操作才能获取在单个查询中返回的所有必需数据。 当返回查询结果所需的联接数具有较高的 CPU 使用率时,在规范化数据与具有较少联接和较少 CPU 需求的去规范化数据之间存在折衷,但这会增加更新异常的可能性。
注意
去规范化数据不同于非规范化数据。 对于非规范化,我们从设计规范化的表开始。 然后,可以向某些表中添加其他列,以减少所需的联接数,但是这样做,我们知道可能存在更新异常。 然后,确保具有触发器或其他类型的处理程序,以确保执行更新时,还会更新所有重复数据。
去规范化数据可以更高效地进行查询,尤其是对于读取繁重的工作负载(例如数据仓库)而言。 在那些情况下,具有额外列可能会提供更好的查询模式和/或更简单的查询。
星型架构
尽管大多数规范化都是针对 OLTP 工作负载的,但数据仓库具有其自己的建模结构,通常是去规范化模型。 此设计使用事实数据表,该表记录特定事件(例如销售)的度量值或指标,并将它们联接到维度表,维度表的行数较少,但可能具有大量列来描述事实数据。 一些示例维度将包括库存、时间和/或地理位置。 此设计模式用于使数据库更易于查询,并提高读取工作负载的性能。
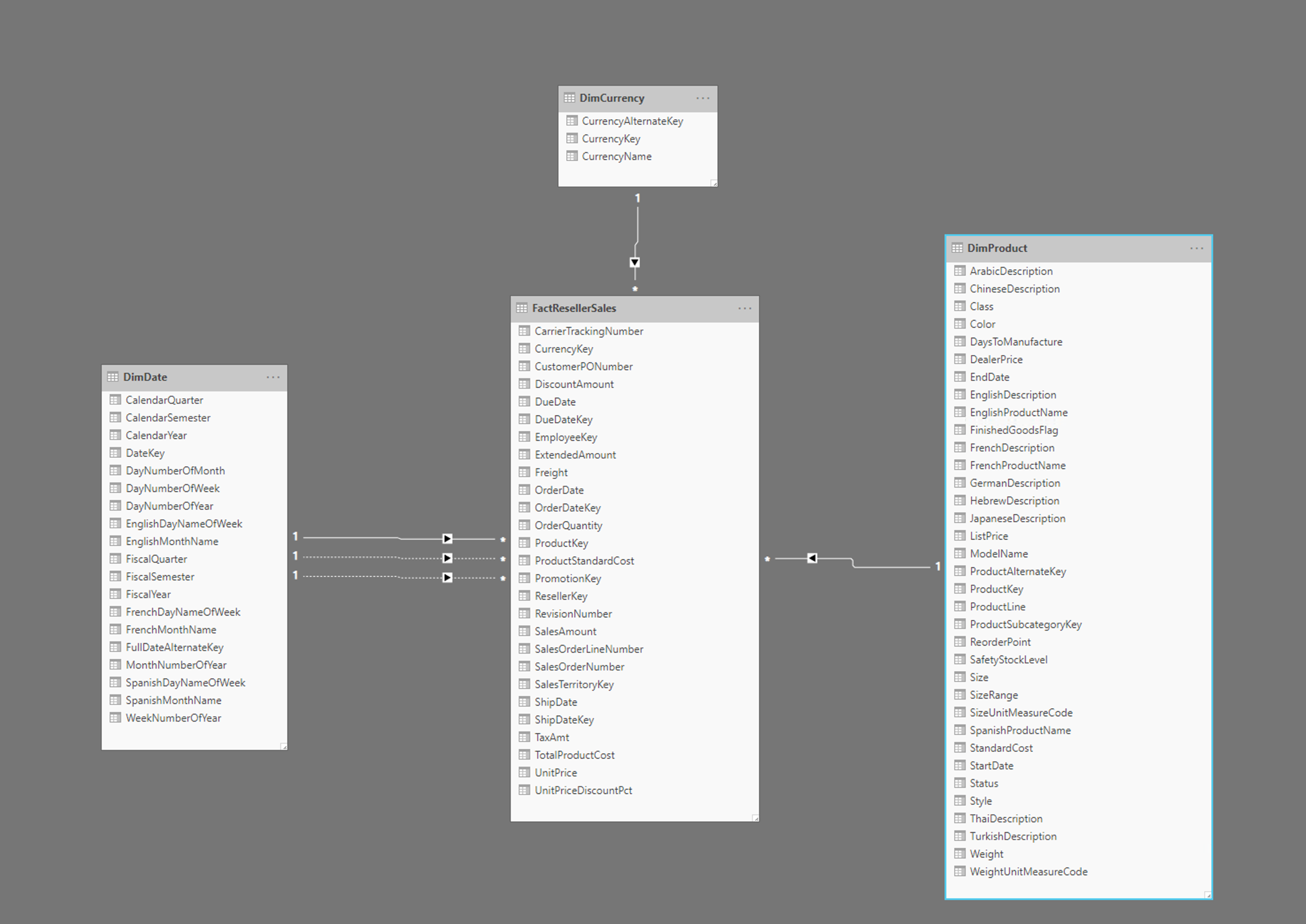
上图显示了星型架构的示例,其中包括 FactResellerSales 事实数据表以及日期、货币和产品的维度。 事实数据表包含与销售事务相关的数据,而维度仅包含与销售数据的特定元素相关的数据。 例如,FactResellerSales 表仅包含一个 ProductKey 来指示出售了哪种产品。 有关每种产品的所有详细信息都存储在 DimProduct 表中,并通过 ProductKey 列与事实数据表相关联。
与星型架构设计相关的是雪花型架构,该架构对单个业务实体使用一组更规范化的表。 下图显示了雪花型架构的单个维度的示例。 Products 维度已规范化并存储在三个表中,分别称为 DimProductCategory、DimProductSubcategory 和 DimProduct。
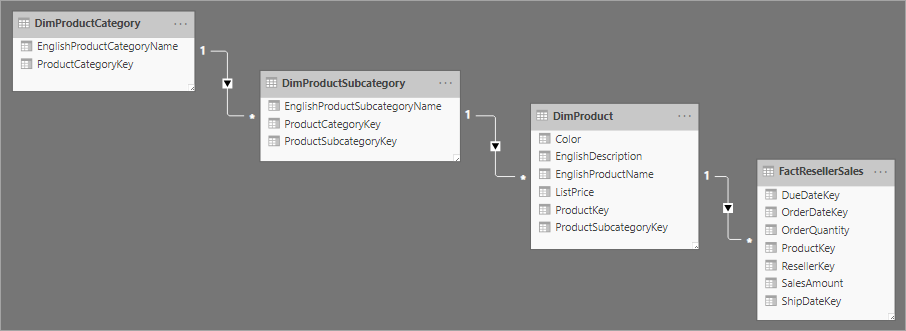
星型架构和雪花型架构之间的主要区别在于,雪花型架构中的维度已规范化以减少冗余,从而节省了存储空间。 缺点是查询需要更多的联接,这会增加复杂性并降低性能。