识别 Azure Cosmos DB API
Azure Cosmos DB 是 Microsoft 的完全托管和无服务器分布式数据库,适用于任何大小或规模的应用程序,同时支持关系工作负载和非关系工作负载。 开发人员可以使用首选开放源代码数据库引擎(包括 PostgreSQL、MongoDB 和 Apache Cassandra)快速生成和迁移应用程序。 预配新的 Cosmos DB 实例时,请选择想要使用的数据库引擎。 引擎的选择取决于许多因素,包括要存储的数据类型、支持现有应用程序的需求,以及处理数据存储的开发人员的技能。
Azure Cosmos DB for NoSQL
Azure Cosmos DB for NoSQL 是 Microsoft 的本机非关系服务,用于处理文档数据模型。 它以 JSON 文档格式管理数据,尽管是 NoSQL 数据存储解决方案,但使用 SQL 语法处理数据。
包含客户数据的 Azure Cosmos DB 数据库的 SQL 查询可能类似于:
SELECT *
FROM customers c
WHERE c.id = "joe@litware.com"
此查询的结果由一个或多个 JSON 文档组成,如下所示:
{
"id": "joe@litware.com",
"name": "Joe Jones",
"address": {
"street": "1 Main St.",
"city": "Seattle"
}
}
Azure Cosmos DB for MongoDB
MongoDB 是一种流行的开源数据库,其中数据存储为二进制 JSON (BSON) 格式。 借助 Azure Cosmos DB for MongoDB,开发人员可以使用 MongoDB 客户端库和代码来处理 Azure Cosmos DB 中的数据。
MongoDB 查询语言 (MQL) 使用面向对象的精简语法,开发人员可以使用“对象”来调用方法。 例如,以下查询使用“find”方法查询“db”对象中的“products”集合:
db.products.find({id: 123})
此查询的结果由 JSON 文档组成,类似于:
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
Azure Cosmos DB for PostgreSQL
Azure Cosmos DB for PostgreSQL 是 Azure 中的分布式 PostgreSQL 选项。 Azure Cosmos DB for PostgreSQL 是一个本机 PostgreSQL 全局分布式关系数据库,可自动分片数据,以帮助生成高度可缩放的应用。 可在单节点服务器组中开始构建应用,就像在其他任何地方使用 PostgreSQL 一样。 随着应用的可伸缩性和性能需求的增长,可通过透明地分发表,无缝缩放到多个节点。 PostgreSQL 是一种关系数据库管理系统 (RDBMS),在其中定义关系数据表,例如,可以定义如下所示的产品表:
| ProductID | ProductName | 价格 |
|---|---|---|
| 123 | Hammer | 2.99 |
| 162 | Screwdriver | 3.49 |
然后,可以查询此表,以使用 SQL 检索特定产品的名称和价格,如下所示:
SELECT ProductName, Price
FROM Products
WHERE ProductID = 123;
此查询的结果将包含产品 123 的行,如下所示:
| ProductName | 价格 |
|---|---|
| Hammer | 2.99 |
Azure Cosmos DB for Table
Azure Cosmos DB for Table 用于处理键值表中的数据,类似于 Azure 表存储。 它提供比 Azure 表存储更大的可伸缩性和性能。 例如,可以定义一个名为“Customers”的表,如下所示:
| PartitionKey | RowKey | 名称 | 电子邮件 |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoy | samir@northwind.com |
然后,你可以通过特定于语言的 SDK 之一使用表 API,以调用服务终结点从表中检索数据。 例如,以下请求会返回包含上表中“Samir Nadoy”的记录行:
https://endpoint/Customers(PartitionKey='1',RowKey='124')
Azure Cosmos DB for Apache Cassandra
Azure Cosmos DB for Apache Cassandra 与 Apache Cassandra 兼容,Apache Cassandra 是一种使用列族存储结构的常用开源数据库。 列族是表,类似于关系数据库中的表,但不强制要求每一行都有相同的列。
例如,可以创建“Employees”表,如下所示:
| ID | 名称 | 管理员 |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra 支持基于 SQL 的语法,因此客户端应用程序可以检索“Ben Chan”的记录,如下所示:
SELECT * FROM Employees WHERE ID = 2
Azure Cosmos DB for Apache Gremlin
Azure Cosmos DB for Apache Gremlin 与图形结构中的数据一起使用;其中实体定义为在连接的图中形成节点的顶点。 节点由表示关系的“边缘”连接,如下所示:
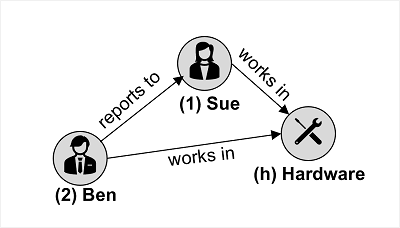
图像中的示例显示了两种类型的顶点(员工和部门)和连接它们的边缘(员工“Ben”向员工“Sue”报告,并且这两个员工在“Hardware”部门工作)。
Gremlin 语法包括对顶点和边缘进行操作的函数,使你能够在图中插入、更新、删除和查询数据。 例如,可以使用以下代码添加名为“Alice”的新员工,该员工向 ID 为“1”的员工 (Sue) 报告
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
以下查询按 ID 顺序返回所有“员工”顶点。
g.V().hasLabel('employee').order().by('id')