探索持续运维
持续运维是 DevOps 分类中的 8 项功能中的一种。
了解需要持续运维的原因
复杂的系统会失败,可能导致代价高昂的中断和干扰。 让我们探讨一些示例。
| 公司 | 活动 |
|---|---|
Delta Air Lines |
在 2016 年 8 月,达美航空被迫取消了 2,300 趟航班,原因是一台出现故障的设备导致它位于亚特兰大的运营中心出现断电情况。 据报告,该公司损失达到了 1 亿 5000 万美元。 |
FedEx 和英国国家卫生服务 |
在 2017 年 5 月,WannaCry 勒索软件导致 FedEx 运营中断。 一家 FedEx 子公司报告称损失达到 2 亿美元。 英国国家卫生署是该勒索软件的另外一名受害者,它阻止访问卫生署的计算机、将关键医疗设备困在外面,还使某些医院被迫将救护车转移到其他地方。 |
Amazon S3 |
在 2017 年 2 月,操作员错误导致 Amazon 核心存储服务出现 4 小时的中断,这对 Alexa、IFTTT、Quora 和 Trello 等重要网站造成了诸多影响。 |
| 领英遇到过长达 2 个月阻碍 DEV 工作完成的问题。 | |
Equifax |
Equifax 在 2017 年遭到了一次漏洞攻击,导致超过 1 亿 6000 万名消费者的个人信息遭到泄露。 我们在持续安全中对此进行了更详细的讨论。 |
漏洞攻击带来的业务影响和损失
漏洞攻击造成的损失常常远远超过销售损失和公司的信誉。 这些损失可能包含:
- 响应和通知
- 根据法律要求,需向受影响的各方发送通知,这会带来运营和服务成本。 这些成本通常还包含呼叫中心、公共关系支持和信用监控服务的额外成本。
- 员工工作效率和营业额的下降
- 雅虎的法律总顾问辞职了,CEO 没获得 2016 年的年终分红。
- 诉讼与和解
- 受攻击的目标向美国 47 个州支付 1850 万美元。
- 法规罚款和回应
- 随着自 2018 年起新的数据保护策略在欧盟生效,罚款规定为年收取的 4% 或者 2000 万欧元(以较大者为准)。
- 品牌恢复成本
- 矿业科技公司 Codan 一年的收入从 4500 万美元下滑到了 920 万美元。
- 其他责任
- Verizon 在两次大规模黑客后,为雅虎支付了 3 亿 5000 万美元的费用。
可能还必须遵守其他安全和审核要求。
持续运维中的可用性和恢复能力
Gartner 调查显示,企业和 IT 负责人预计到 2020 年,生产应用程序中有大约 47% 会在公共云位置运行。
当一行代码就能毁掉整个数据中心,I&O 领导者们需要改变他们在生产环境的可用性和恢复能力方面的关注点。 新的部署模式正在改变我们确保应用程序和基础结构可用性及恢复能力的方式。
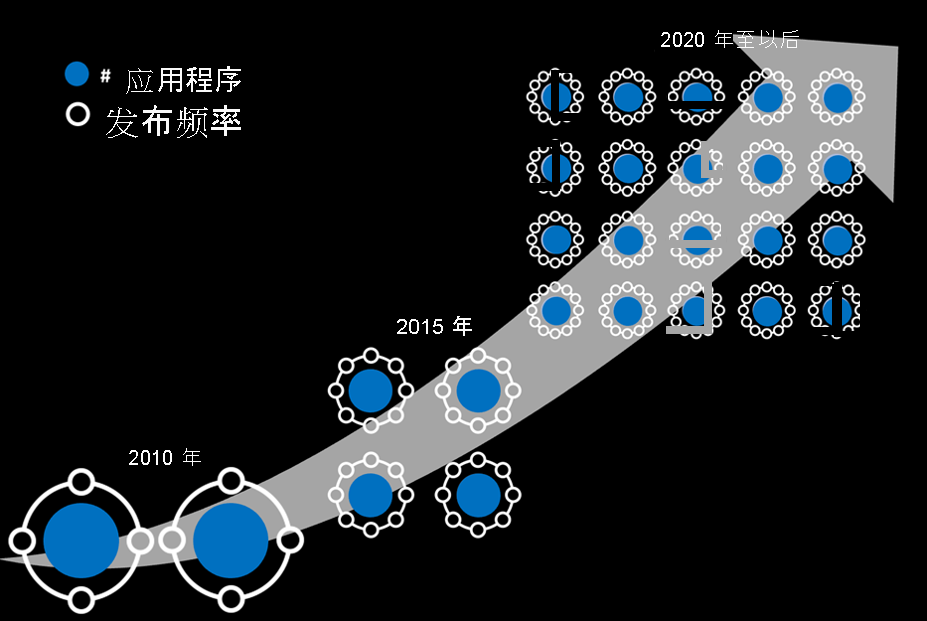
增加生产中应用和发布的数量
软件交付性能的关键性能指标是:
- 更改所需的提前期
- 部署频率
- 平均还原时间
- 更改失败率
如果团队努力提高速度,但在将质量构建到流程方面投资不够,那么这些团队将遭遇更大的失败,需要更多的时间来还原服务。 在流程中保证质量的团队会同时收获速度和稳定性。
Web 和移动应用程序的数量,还有应用程序发布频率都得到了极大的增加。 代码也变得越来越复杂。
注意
DevOps 价值的一个重要部分通常是关于在创新(速度)和业务持续性(控制)之间找到适当的平衡。
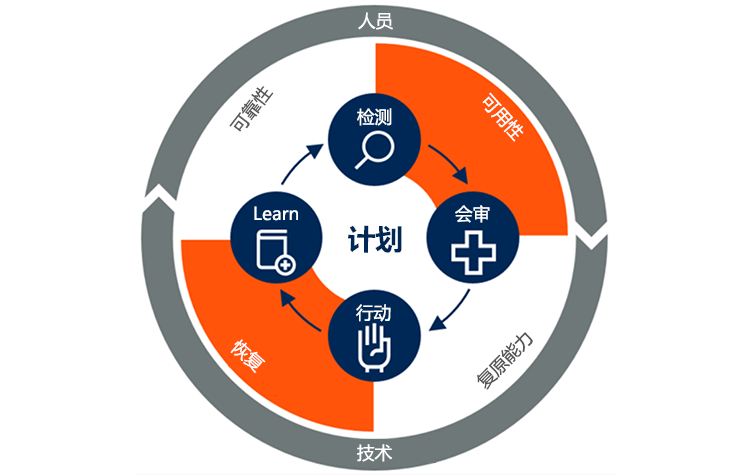
什么是持续运维?
重要
持续运维可减少或消除计划性故障时间或中断,例如计划性维护。 如果可能,应将基础结构、应用程序和服务的持续监视与自动化修正相关联。 用户应该永远不会知道何时发生更新或增量发布。
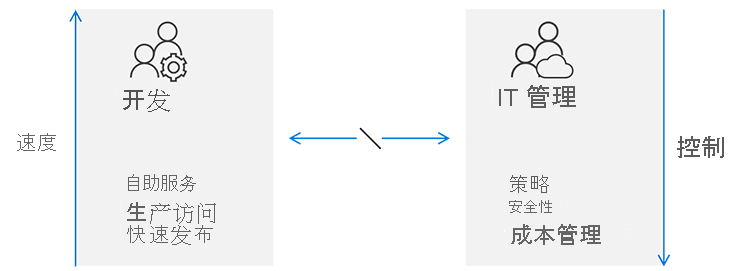
比较传统做法和持续运维做法
在传统企业模型中,IT 强制执行发布的内容,并通过严格的过程和流程控制每一个人。
此方法会造成开发团队和 IT 管理之间不相符。 开发团队大多数是敏捷的,侧重于速度,期待尽可能频繁地进行发布。 对他们来说,IT 管理似乎是一个瓶颈,它与如今业务需求的预期上市时间目标不相符。
重要
适当实现后,DevOps 可同时提供创新(速度)和业务持续性(控制)。
在传统的开发生命周期中:
- 测试是在快要上线之前完成的。
- 监视通常会进行移交。
- 测试阶段常会参考安全措施。
- 在移交过程中,必须检查代码和所有服务管理控制措施的安全性。
- 移交时通常不考虑合规性,它是在服务运行状态期间出现的内容。
- 恢复力/持续性规划是在设计阶段完成的,但通常仅在操作或测试阶段对相关方案进行实际测试,这可能会导致配置更改、返工和白费精力。
- 操作、安全性和合规性以及开发人员之间的协作通常是通过事件管理和问题管理流程被动进行的。
- 直到最终阶段才实施自动化会导致只剩少量资源来完成此操作。
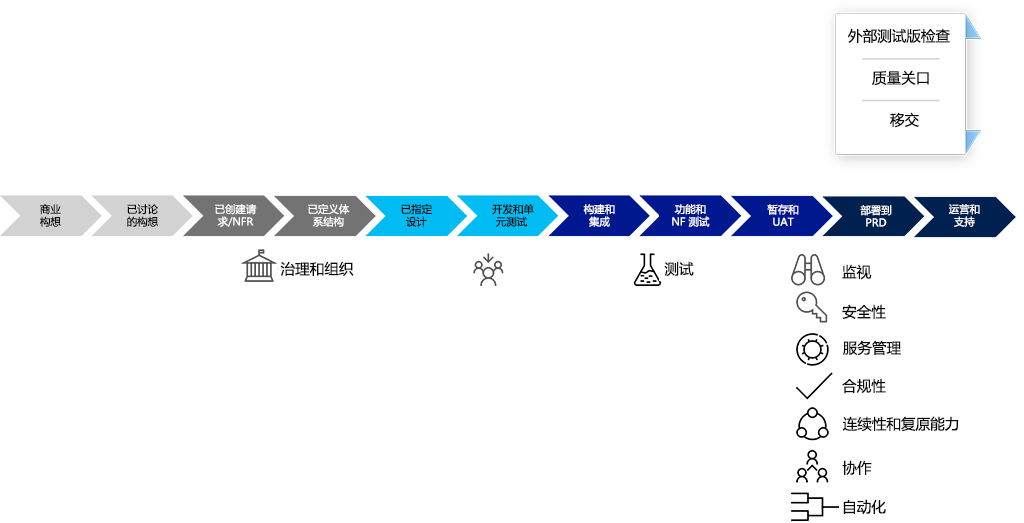
新的方法、技术和工作方式需要一种新的方法来实现持续运维。 下面是已出现的 8 种主要的持续运维实践,它们不断在发展:
- 源于设计的安全性和合规性确认在针对高度自动的云环境进行设计时,必须考虑某些标准、法规和业务需求(例如可追溯性和可审核性)。
- 持续性和恢复力要求与组织紧密协作来确保在设计和实施中反映出业务需求。
- 遥测和监视可用于发现客户使用模式、可能的新需求,以及关于用户在何处遇到错误的详细信息。 这些工具还有助于确保传递价值。
- 在 DevOps 文化中,服务管理是另一种考量:
- 转变成你拥有的方式。 由你构建、由你运行,在中断时,由你来修复。
- 专注于所需的内容。
- 帮助加强管理。
- 促进提高透明度。
- 文化和协作对持续运维来说至关重要。 组织通常需要改变自身工作的方式来促进向 DevOps 团队的转变。 在针对安全性和恢复力进行设计时,协作也是必不可少的。
- 自动化和 AI/ML 操作是使 DevOps(和云)与传统运营团队不同的重要方面。 重点必须放在要自动化的整个系统上(系统自动化),但不单单是一个方面。
- 持续部署使用新式发布管道让开发团队能够快速安全地部署新的功能,从而可持续提供客户价值,缩短解决问题的时间。
- 右移测试采用深色启动 (dark launching)、功能标志、监视和 A/B 测试等实践。 然后,团队能够继续测试来确保应用程序在实时使用期间满足行为、性能和可用性要求。
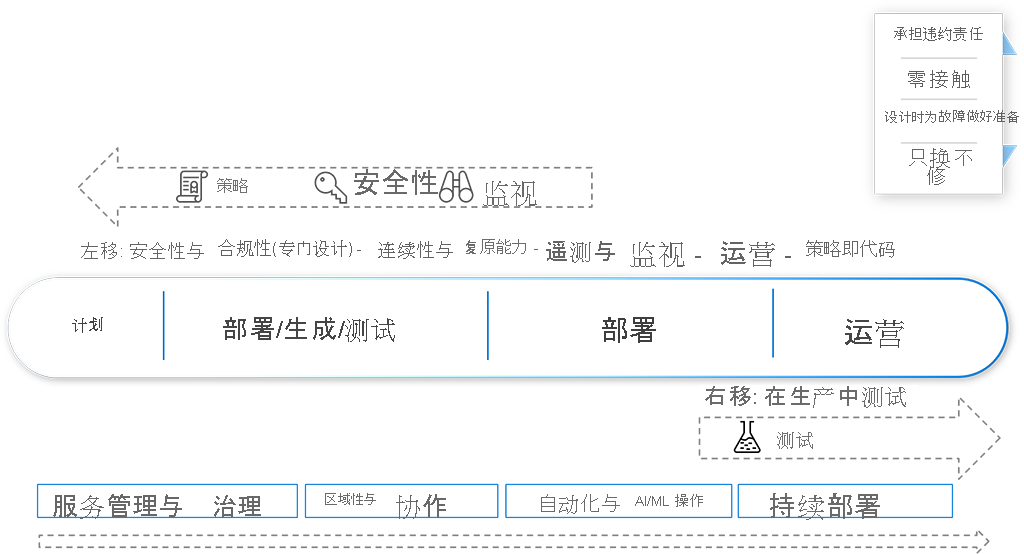
要发展成 DevOps 方法,文化中需要出现重大的范式转变,来使用现代 IT 方法提供业务价值。
| 传统 IT | 现代 IT | |
|---|---|---|
| DNA | 调解 | 不在调解 |
| 服务交付 | 分批次 | 基于连续迭代 |
| 服务稳定性 | 保成功设计(HA/冗余) | 防失败设计(可复原) |
| 委派级别 | IT 分散孤立 | 端到端服务 |
| 进程 | 记入文档,经过优化,经过重新设计 | 自助服务,认可,摩擦小,自动化 |
| 自动化 | 独立,手动启动 | 系统化,被触发,自动化 |
| 监视 | 元数,侧重于故障 | 服务,侧重于端到端功能 |
| 支持 | 服务台/联系中心 | 客户服务/自助服务 |
| 生命周期 | N-1 或更低版本 | N,N+1 |
| 配置/资产管理 | 已发现/手动配置 | 根据规定,声明性,自动化 |
这些变化会带来更简单的自动化流程、一致的结果激励、更低的风险,以及以客户为中心的方法。