探索数据中心
利用数据中心,你可以与源数据以及链接服务进行交互和探索,如以下步骤中所示。
在 Azure Synapse Studio 的左侧,单击“数据”中心。
在此中心,你可以访问工作区中预配的 SQL 池数据库和 SQL 无服务器数据库以及外部数据源(例如存储帐户和其他链接服务)。
在“数据中心”(1) 的“工作区”(2) 选项卡下,展开“数据库”下的“SQLPool01”(3) SQL 池。
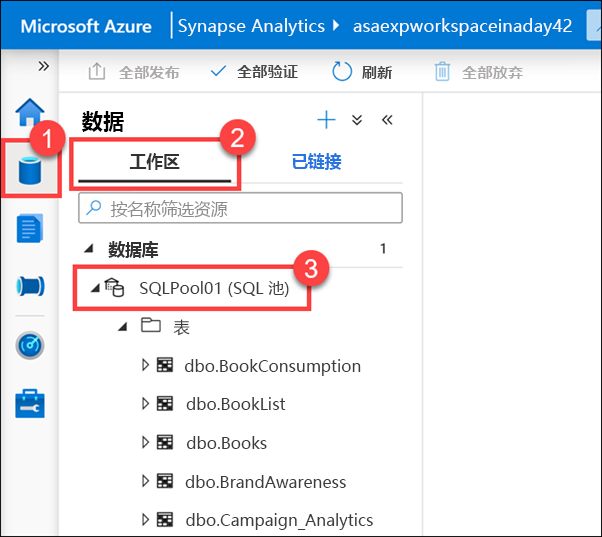
展开“表”和“可编程性/存储过程”。
SQL 池下列出的表存储来自多个源的数据,例如 SAP Hana、X、Azure SQL 数据库以及从业务流程管道复制的外部文件。 通过 Synapse Analytics,我们可以将这些数据源组合在一个位置进行分析和报告。
你还将看到熟悉的数据库组件,例如“存储过程”。 你可以使用 T-SQL 脚本执行存储过程,也可以将它们作为业务流程管道的一部分执行。
选择“链接”选项卡,展开“Azure Data Lake Storage Gen2”组,然后展开工作区的“主存储”。
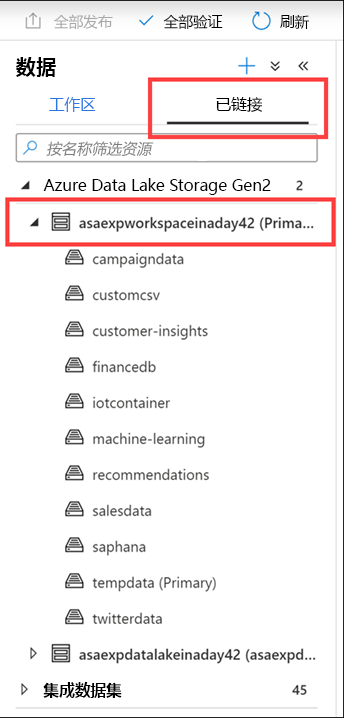
每个 Synapse 工作区都具有与之关联的主 ADLS Gen2 帐户。 它充当数据湖,是存储平面文件的绝佳位置,例如从本地数据存储复制的文件、导出的数据或直接从外部服务和应用程序复制的数据、遥测数据等。一切内容都集中在一个位置。
在我们的示例中,我们有几个容纳文件和文件夹的容器,我们可以从工作区中浏览和使用这些文件和文件夹。 你可以在此处看到市场活动数据、CSV 文件、从外部数据库导入的财务信息、机器学习资产、IoT 设备遥测、SAP Hana 数据和推文等等。
现在全部这些数据都在同一个位置了,我们可以即刻开始预览其中的一些。
让我们看看市场活动数据。
选择 customcsv 存储容器。
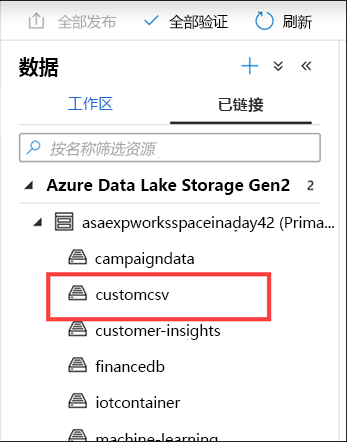
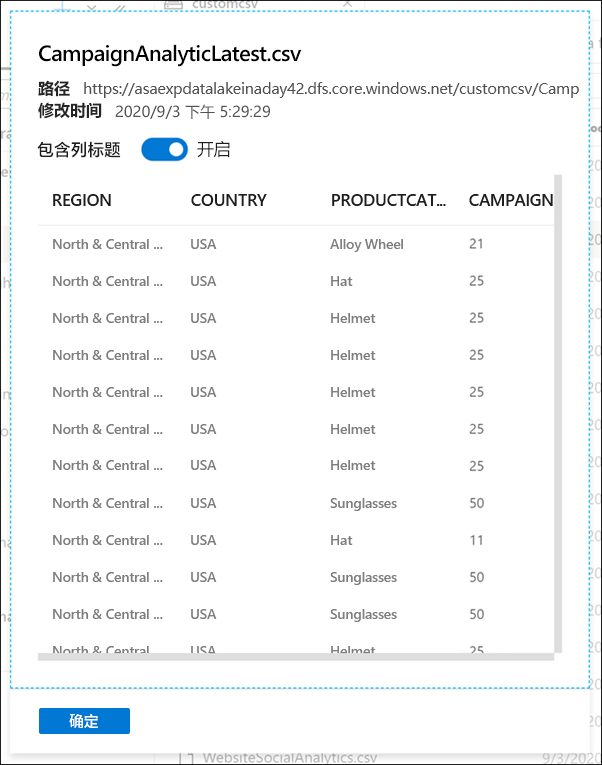
让我们预览市场活动数据,以了解新的市场活动名称。
右键单击 CampaignAnalyticsLatest.csv 文件 (1),然后选择“预览”(2)。
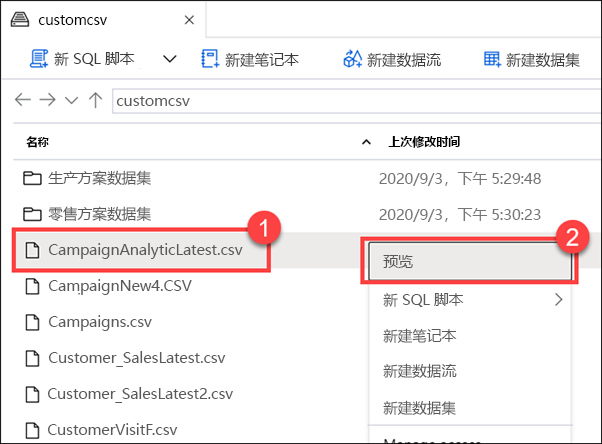
使用文件资源管理器功能,可以快速查找文件并对其执行操作,例如预览文件内容,生成新的 SQL 脚本或笔记本以访问该文件,创建新的数据流或数据集以及管理该文件。