描述数据仓库体系结构
大规模数据分析体系结构可能各不相同,用于实现它们的特定技术也有所不同,但一般情况下会包括以下元素:
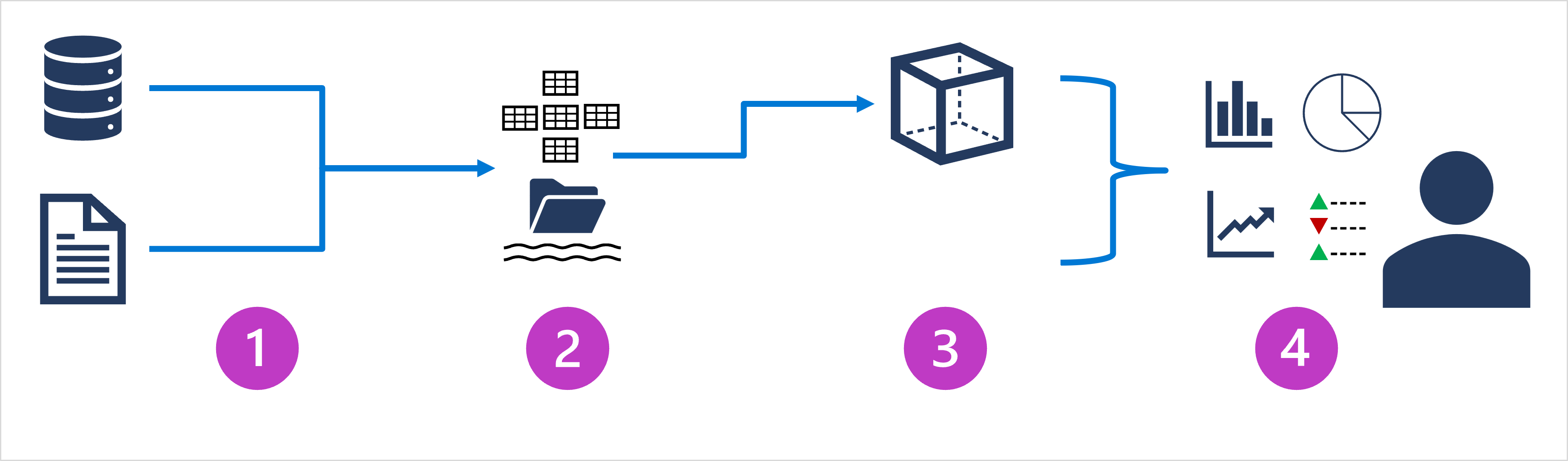
- 数据引入和处理 – 将一个或多个事务数据存储、文件、实时流或其他源中的数据加载到数据湖或关系数据仓库。 加载操作通常涉及以下操作:提取、转换和加载 (ETL) 或提取、加载和转换 (ELT) 过程,在其中将清除、筛选和重构数据以进行分析。 在 ETL 过程中,在加载数据到分析存储区之前转换数据,而在 ELT 过程中,将复制数据到存储区,然后再转换。 无论采用哪种方式,都将优化生成的数据结构以进行分析查询。 数据处理通常由分布式系统执行,这些系统可以使用多节点群集并行处理大量数据。 数据引入包括静态数据的批处理和流式处理数据的实时处理。
- 分析数据存储 – 用于大规模分析的数据存储包括关系“数据仓库”、基于文件系统的“数据湖”,以及合并数据仓库和数据湖功能的混合体系结构(有时称为“数据湖仓库”或“湖数据库”)。 稍后我们将更深入地讨论这些内容。
- 分析数据模型 – 虽然数据分析人员和数据科学家可以直接在分析数据存储中使用数据,但通常会创建一个或多个数据模型,以便对数据进行预先聚合,以便更容易地生成报表、仪表板和交互式可视化效果。 通常,这些数据模型被描述为“多维数据集”,其中,数字数据值在一个或多个维度上聚合(例如,按产品和区域确定销售总额)。 该模型封装了数据值与维度实体之间的关系,以支持“向上/向下钻取”分析。
- 数据可视化 – 数据分析师使用分析模型中的数据,直接从分析存储中创建报表、仪表板和其他可视化对象。 此外,组织中的用户(可能不是技术专业人员)可能会执行自助服务数据分析和报告。 数据的可视化效果可为企业或其他组织显示趋势、比较和关键绩效指标 (kpi),并可采用打印报表、文档中的图形和图表、PowerPoint 的演示文稿、基于 web 的仪表板和交互式环境的形式,从而用户可在其中直观地浏览数据。