评估生成式 AI 应用的性能
当你想要创建生成式 AI 应用时,可以使用提示流来开发聊天应用程序。 可以通过在运行流后评估响应来评估应用的性能。
使用单个提示测试流
在活动的开发期间,可以在计算会话运行时使用“聊天”功能测试要创建的“聊天流”:

在聊天窗口中使用单个提示测试流时,流使用你提供的输入运行。 它成功运行后,聊天窗口中会显示响应。 你还可以浏览流的每个节点的输出,以了解最终响应的构造方式:

使用评估流自动测试流
若要批量评估聊天流,可以运行“自动评估”。 可以使用内置的自动评估,也可以通过创建自己的评估流来定义“自定义”评估。
使用 Microsoft 特选指标进行评估
内置或“Microsoft 特选指标”包括以下指标:
性能和质量:
- 连贯性:测量生成式 AI 应用程序在生成流畅的输出、自然地阅读和仿照类人类语言方面的表现。
- 流畅性:测量生成式 AI 应用程序的预测答案的语言熟练程度。
- GPT 相似性:测量源数据(基本事实)句子与生成式 AI 应用程序生成的响应之间的相似性。
- F1 分数:测量生成式 AI 应用程序预测与源数据(基本事实)之间的字数比率。
- 根基性:测量生成式 AI 应用程序的生成回答与输入源中的信息的一致程度。
- 相关性:测量生成式 AI 应用程序的生成响应与给定问题相关且直接关联的程度。
风险和安全:
- 自我伤害相关的内容:测量生成式 AI 应用程序对生成自我伤害相关内容的倾向。
- 仇恨和不公平的内容:测量生成式 AI 应用程序对生成仇恨和不公平内容的倾向。
- 暴力内容:测量生成式 AI 应用程序生成暴力内容的倾向。
- 性内容:测量生成式 AI 应用程序生成性内容的倾向。

若要使用内置的自动评估功能评估聊天流,你需要:
- 创建测试数据集。
- 在 Azure AI Foundry 门户中创建新的自动评估。
- 选择包含模型生成的输出的流或数据集。
- 选择要评估的指标。
- 运行评估流。
- 查看结果。

提示
详细了解评估和监视指标
创建自定义评估指标
或者,可以创建你自己的自定义评估流,在其中定义聊天流输出的评估方式。 例如,可以使用 Python 代码或使用大型语言模型 (LLM) 节点来评估输出,以创建 AI 辅助指标。 让我们通过一个简单的示例来探讨一下评估流的工作原理。
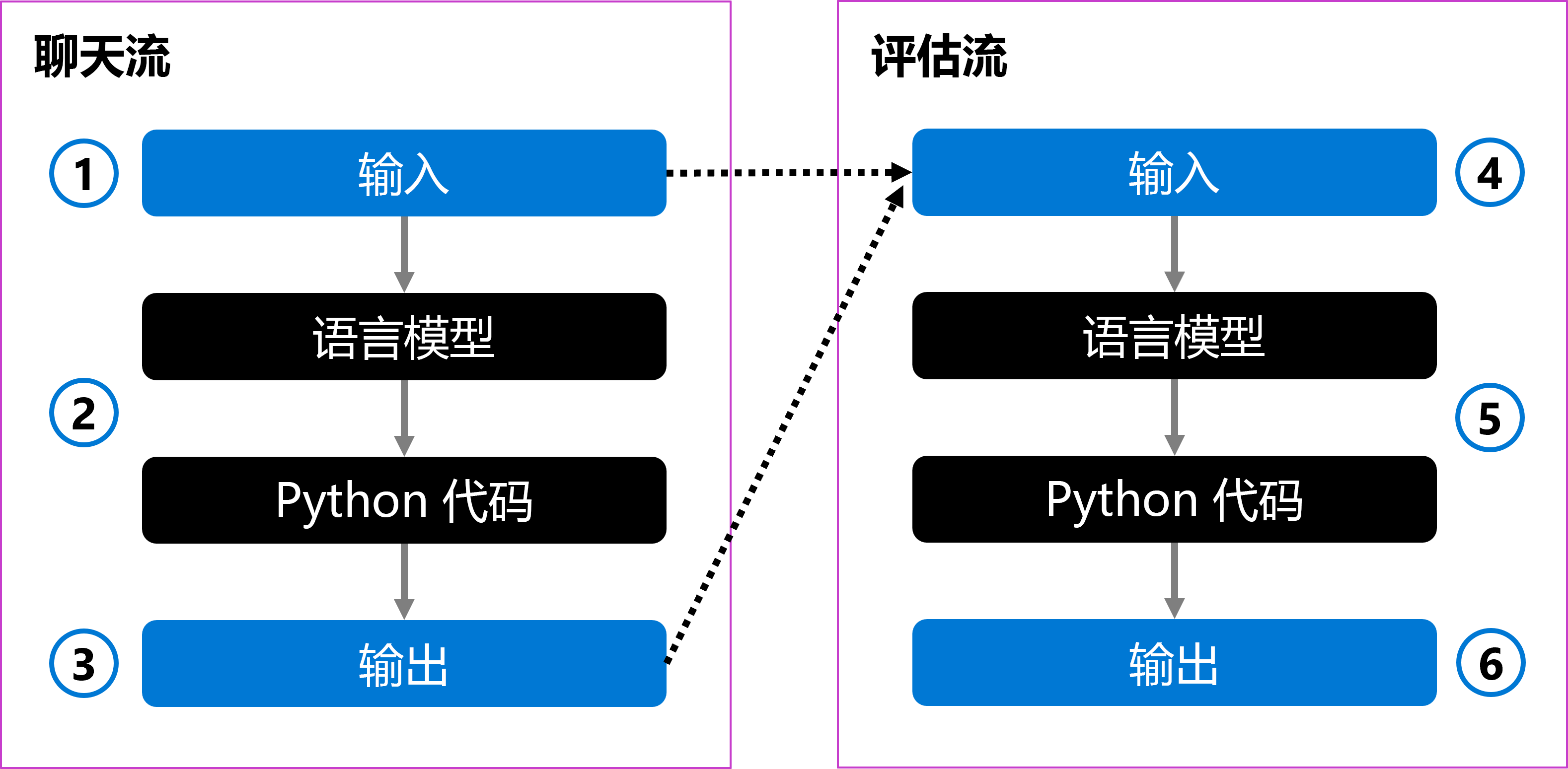
你可以有一个将用户的问题作为输入的聊天流 (1)。 该流使用语言模型处理输入,并使用 Python 代码设置回答的格式 (2)。 最后,它将响应作为输出返回 (3)。
若要评估聊天流,可以创建评估流。 评估流将原始用户问题和生成的输出作为输入 (4)。 该流使用语言模型对其进行评估,并使用 Python 代码定义评估指标 (5),然后将其返回为输出 (6)。
创建评估流时,可以选择如何评估聊天流。 可以使用语言模型创建你自己的自定义 AI 辅助指标。 在提示符中,可以定义要测量的指标,以及语言模型应使用的评分尺度。 例如,评估提示可以是:
# Instructions
You are provided with the input and response of a language model that you need to evaluate on user satisfaction.
User satisfaction is defined as whether the response meets the user’s question and needs, and provides a comprehensive and appropriate answer to the question.
Assign each response a score of 1 to 5 for user satisfaction, with 5 being the highest score.
创建评估流后,可以通过提供测试数据集并运行评估流来评估聊天流。

在评估流中使用语言模型时,可以在输出跟踪中查看结果:

此外,还可以在评估流中添加 Python 节点,以聚合测试数据集中所有提示的结果并返回总体指标。
提示