评估模型性能
评估模型在不同阶段的性能对于确保其有效性和可靠性至关重要。 在探索评估模型的各种选项之前,我们先来了解一下可以评估应用程序的哪些方面。
在开发生成式 AI 应用时,使用聊天应用程序中的语言模型来生成回复。 为了帮助确定要集成到应用程序中的模型,可以评估单个语言模型的性能:
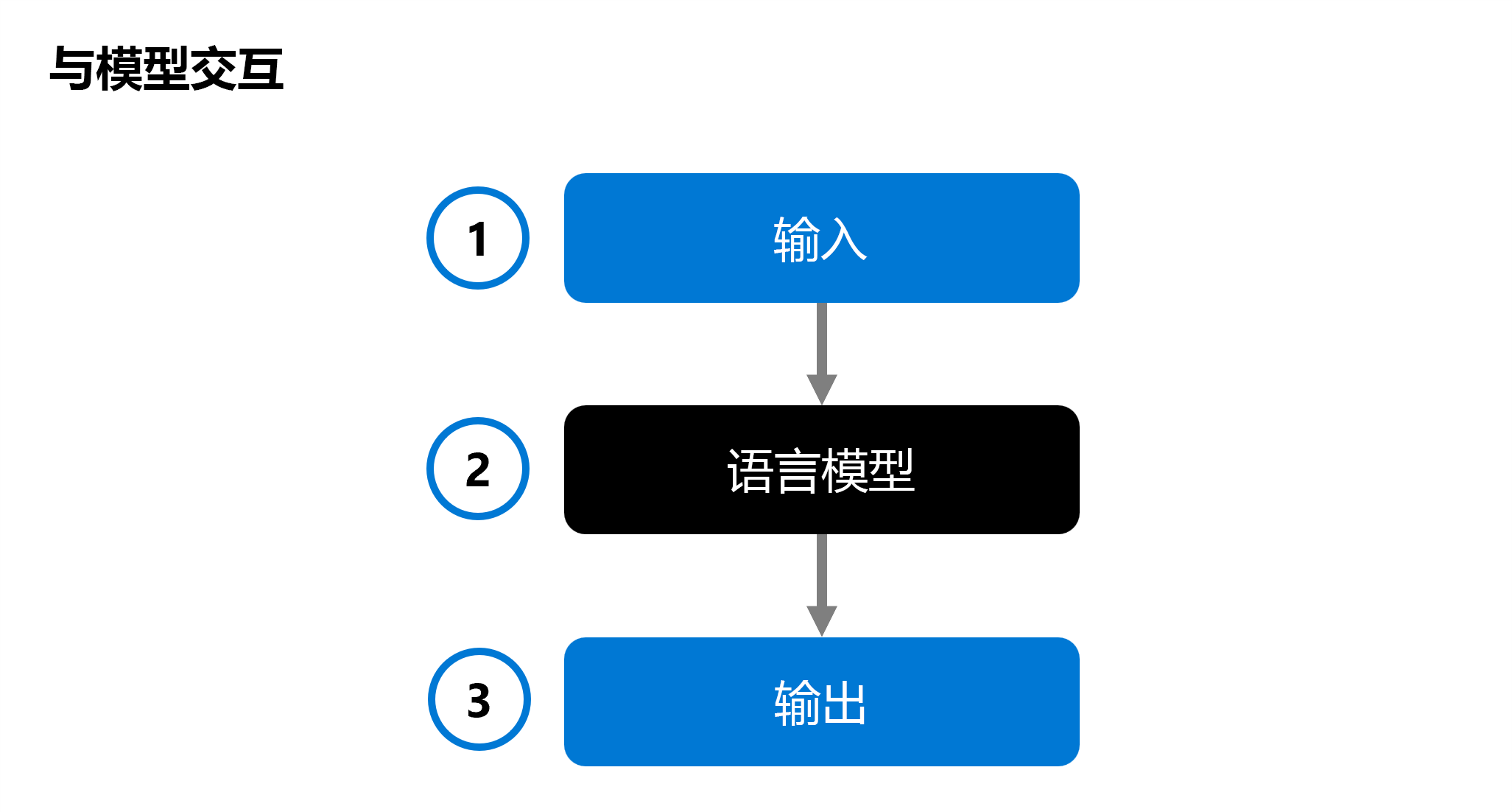
向语言模型 (2) 提供输入 (1),并生成响应作为输出 (3)。 然后,通过分析输入和输出,并将其与预定义的预期输出进行比较(可选),对模型进行评估。
在开发生成式 AI 应用时,将语言模型集成到聊天流中:
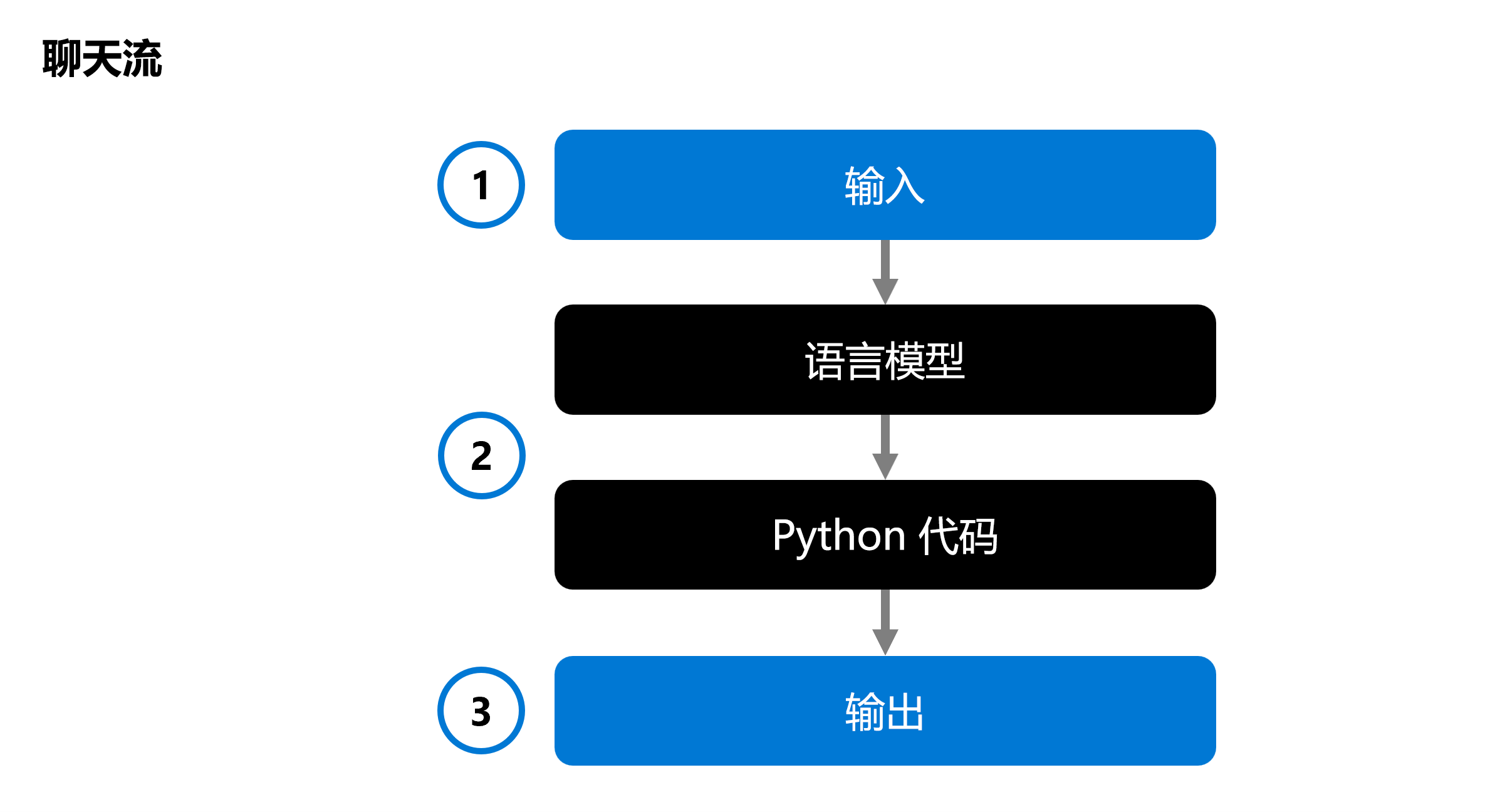
使用聊天流可协调可执行流,这些流可以结合多种语言模型和 Python 代码。 该流需要输入 (1),通过执行各个节点 (2) 对其进行处理,并生成输出 (3)。 可以评估完整的聊天流及其各个组件。
评估解决方案时,可以从测试单个模型开始,并最终测试完整的聊天流,以验证生成式 AI 应用是否按预期工作。
让我们来探索几种评估模型和聊天流或生成式 AI 应用的方法。
模型基准
模型基准是跨模型和数据集的公开可用的指标。 这些基准可帮助了解你的模型相对于其他模型的性能。 一些常用的基准包括:
- 准确性:根据数据集将模型生成的文本与正确答案进行比较。 如果生成的文本与答案完全匹配,则结果为 1,否则为 0。
- 连贯性:度量模型输出是否流畅、读起来是否自然、是否与类人语言相似
- 流畅性:评估生成的文本在多大程度上符合语法规则、语法结构以及词汇的适当用法,从而做出语言正确且听起来自然的响应。
- GPT 相似性:量化基础真实句子(或文档)与 AI 模型生成的预测句子之间的语义相似性。
在 Azure AI Foundry 门户中,可以在部署模型之前,浏览所有可用模型的模型基准:

手动评估
人工评估涉及由人工评分员对模型的响应质量进行评估。 通过这种方法可以深入了解自动指标可能忽略的方面,如上下文相关性和用户满意度。 人工评估人员可以根据相关性、信息量和参与度等标准对响应进行评分。
传统机器学习指标
传统机器学习指标对评估模型性能也很有价值。 其中一个指标是 F1 分数,用于衡量生成的答案和基础真实答案之间的共享单词数量的比率。 F1 分数适用于文本分类和信息检索等任务,在这些任务中,精准率和召回率非常重要。
AI 辅助指标
AI 辅助指标使用高级技术来评估模型性能。 这些指标可能包含:
- 风险和安全指标:这些指标评估与模型输出相关的潜在风险和安全问题。 它们有助于确保模型不会生成有害或有偏见的内容。
- 生成质量指标:这些指标评估生成的文本的整体质量,考虑的因素包括创造性、连贯性以及是否符合所需的风格或语气。