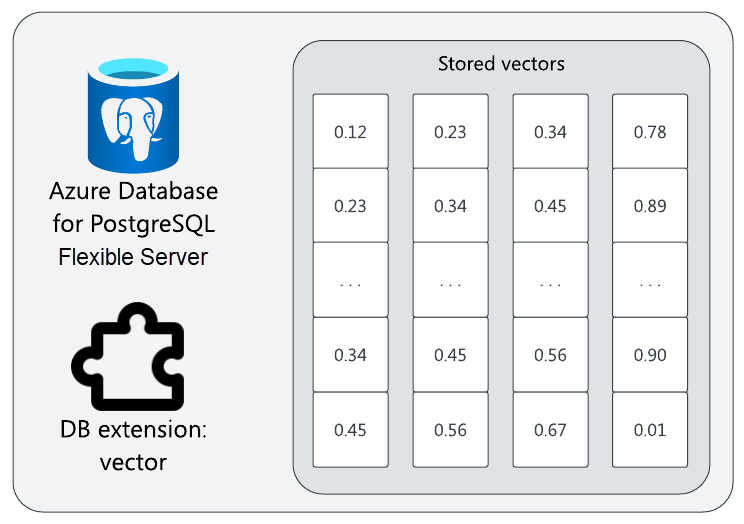
在 Azure Database for PostgreSQL 中存储矢量
回想一下,你需要嵌入存储在矢量数据库中的矢量来运行语义搜索。 Azure Database for PostgreSQL 灵活服务器可通过 vector 扩展用作矢量数据库。
vector 简介
开放源代码 vector 扩展为 PostgreSQL 提供矢量存储、相似度查询和其他矢量操作。 启用后,可以创建 vector 列来存储嵌入(或其他矢量)以及其他列。
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
可以将矢量列添加到现有表:
ALTER TABLE documents ADD COLUMN embedding vector(3);
获得一些矢量数据后,可以将它们和普通表数据一起查看:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
vector 扩展支持多种语言,例如 .NET、Python、Java 和其他许多语言。 有关详细信息,请参阅其 GitHub 存储库。
要在 C# 中使用 Npgsql 插入包含矢量 [1, 2, 3] 的文档,请运行如下所示的代码:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
插入和更新矢量
表具有矢量列后,可以使用矢量值添加行,如前所述。
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
还可以使用 COPY 语句批量加载矢量(请参阅使用 Python 的完整示例):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
可以像标准列一样更新矢量列:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
执行余弦距离搜索
vector 扩展提供了 v1 <=> v2 运算符来计算矢量 v1 和 v2 之间的余弦距离。 结果是介于 0 和 2 之间的数字,其中 0 表示“语义上完全相同”(无距离),2 表示“语义上相反”(最大距离)。
可以看到术语余弦距离和相似度。 回想一下,余弦相似度介于 -1 和 1 之间,其中 -1 表示“语义上相反”,1 表示“语义上相同”。请注意 similarity = 1 - distance。
结果是按距离升序排序的查询首先返回距离最近(最相似)的结果,而按相似度降序排序的查询首先返回最相似(距离最近)的结果。
下面是用于说明概念的一些矢量及其距离和相似度。 可以通过运行如下所示的内容自行计算此计算:
SELECT '[1,1]' <=> '[-1,-1]';
请考虑以下矢量:
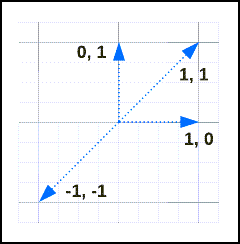
它们的相似度和距离如下:
| v1 | V2 | distance | 相似性 |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
要按与矢量 [2, 3, 4] 接近程度的顺序获取文档,请运行以下查询:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
结果:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
包含 id=3 的文档与查询最相似,然后是 id=1,最后则是 id=2。
将 LIMIT N 子句添加到 SELECT 查询以返回最相似的前 N 个文档。 例如,要获取最相似的文档:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
结果:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535