了解深度学习的概念
大脑中有一种名为神经元的神经细胞,这些细胞通过神经延伸互相连接,通过神经网络传递电化学信号。

当网络中的第一个神经元受到刺激时,它会处理输入信号,如果信号超过特定的阈值,则会激活神经元,并将信号传递到连接到的神经元。 这些神经元会被激活,并通过网络的其余部分传递信号。 随着时间的推移,当你学习如何有效地做出反应时,神经元之间的联系会因为频繁的使用而加强。 例如,如果你看到一张企鹅图片,你的神经元连接让你能够处理图片中的信息,你对企业特征的了解让你能够将其识别为企鹅。 随着时间的推移,如果你看到多张有各种动物的图片,根据动物特征识别动物所涉及的神经元网络会变得更强。 换句话说,你可以更好地准确识别不同的动物。
深度学习使用处理数值输入(而不是电化学刺激)的人工神经网络来模拟这一生物过程。
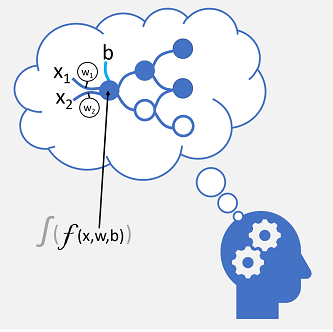
传入的神经连接通常由标识为 x 的数值输入所取代。 如果有多个输入值,x 将被视为具有名为 x1、x2(依此类推)的元素的向量。
与每个 x 值相关联的是权重 (w),它用于增强或削弱 x 值的效果来模拟学习。 此外,还添加了一个偏差 (b) 输入,以启用对网络的精细控制。 在训练过程中,会调整 w 和 b 值来优化网络,使其“学习”生成正确的输出。
神经元本身封装一个了函数,该函数计算 x、w 和 b 的加权总和。 此函数反过来又包含在一个激活函数中,该函数限制结果(通常是 0 到 1 之间的值)来确定神经元是否将输出传递到网络中的下一层神经元。
训练深度学习模型
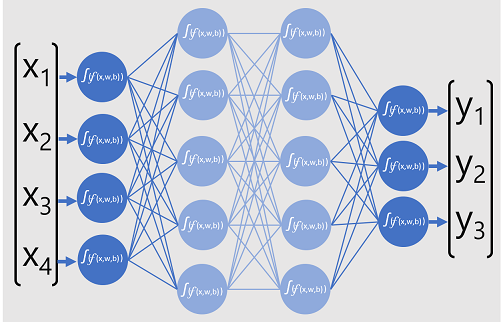
深度学习模型是由多个人工神经元层组成的神经网络。 每一层表示一组函数,使用关联的 w 权重和 b 偏差对 x 值执行这些函数,最后一层作用于模型预测的 y 标签的输出。 对于分类模型(它预测对输入数据来说最可能的类别或类),输出是一个向量,其中包含出现每个可能的类的概率。
下图表示一个深度学习模型,该模型根据 4 个特征(x 值)预测数据实体的类。 模型的输出(y 值)是三个可能的类标签中的每一个的出现概率。
为了训练模型,深度学习框架会馈送多批输入数据(其实际标签值已知),在所有网络层中应用函数,并测量训练数据的输出概率与实际已知类标签之间的差异。 预测输出与实际标签之间的聚合差异称为损失。
在计算了所有数据批次的聚合损失后,深度学习框架使用优化器来确定应如何调整模型中的权重和偏差来减少总体损失。 然后,这些调整将反向传播到神经网络模型中的层,接着再次通过网络传递数据,并重新计算损失。 此过程将重复多次(每次迭代称为一个 epoch),直到损失最小化,并且模型已“学习”正确的权重和偏差,能够准确预测为止。
在每个 epoch 期间,会调整权重和偏差来最大程度地减少损失。 调整程度受你向优化器指定的学习率控制。 如果学习率太低,训练过程可能需要很长时间才能确定最佳值;但如果学习率太高,优化器可能永远找不到最佳值。