了解 Azure 数据工厂活动组件
一个 Azure 订阅可能具有一个或多个 Azure 数据工厂实例。 Azure 数据工厂由四个核心组件组成。 这些组件组合起来提供一个平台,供你在上面编写数据驱动型工作流(其中包含用来移动和转换数据的步骤)。
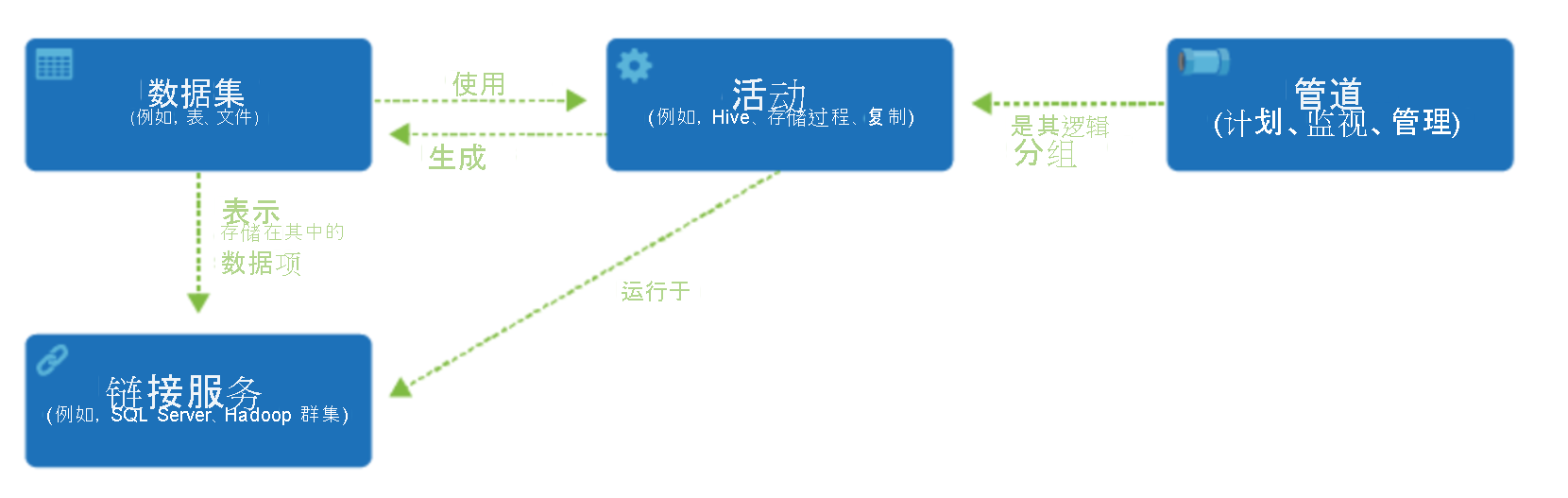
数据工厂支持各种数据源,可以通过创建被称为“链接服务”的对象来连接到这些数据源,从而能从某个数据源引入数据,以便为转换和/或分析准备数据。 此外,链接服务可以按需启动计算服务。 例如,你可能需要启动按需 HDInsight 群集,目的是通过 Hive 查询来处理数据。 使用链接服务,可以定义引入或准备数据所需的数据源或计算资源。
定义链接服务后,Azure 数据工厂可以通过创建数据集对象来了解应该使用的数据集。 数据集表示链接服务对象引用的数据存储中的数据结构。 数据集也可由被称为“活动”的 ADF 对象使用。
“活动”通常包含 Azure 数据工厂工作的转换逻辑或分析命令。 活动包括可用于从各种数据源引入数据的复制活动。 它还可以包含用于执行无代码数据转换的映射数据流。 它还可以包含用于转换数据的存储过程、Hive 查询或 Pig 脚本的执行。 你可以将数据推送到机器学习模型中以执行分析。 发生多个活动的情况并不少见,其中可能包括使用 SQL 存储过程转换数据,然后使用 Databricks 进行分析。 在这种情况下,可以使用名为“管道”的对象按逻辑对多个活动进行分组,可为其制定执行计划,或者定义触发器来决定何时需要启动管道执行。 不同类型的事件有不同类型的触发器类型。
控制流是管道活动的业务流程,包括将活动按顺序链接起来、设置分支。可以在管道级别定义参数,在按需或者通过触发器调用管道时传递自变量。 它还包括自定义状态传递和循环容器,以及 For-each 迭代器。
参数是只读配置的键值对。 参数是在管道中定义的。 所定义的参数的自变量是在执行期间通过由触发器创建的运行上下文传递的或通过手动执行的管道传递的。 管道中的活动使用参数值。
Azure 数据工厂具有集成运行时,集成运行时使管道能在活动和链接服务对象之间进行桥接。 它被链接服务引用,并提供运行或分派活动的计算环境。 这样就可以在最近的区域中执行活动。 Integration Runtime 有三种类型:Azure、自承载和 Azure-SSIS。
完成所有工作后,可以使用数据工厂将最终数据集发布到另一个链接服务,然后可供 Power BI 或机器学习这样的技术使用。