说明数据工厂流程
数据驱动的工厂流
Azure 数据工厂中的管道(数据驱动型工作流)通常执行以下四个步骤:
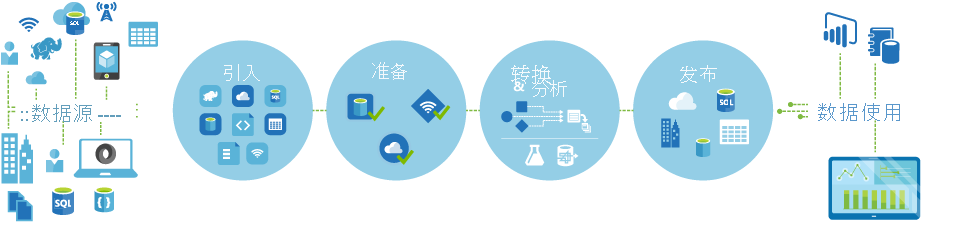
连接和收集
构建编排系统的第一步是定义所有必需的数据源并将其连接在一起,例如数据库、文件共享和 FTP Web 服务。 下一步是根据需要将数据引入提取到集中位置以进行后续处理。
转换和扩充
计算服务(如 Databricks 和机器学习)可用于按可维护和受控的计划准备或生成转换后的数据,以向生产环境提供经过清理和转换后的数据。 在某些情况下,甚至可以使用其他数据来扩充源数据,以帮助进行分析,或者通过规范化过程对其进行合并,以供在机器学习试验中使用。
发布
从转换和扩充阶段将原始数据优化为可用于业务的使用形式之后,可以将数据加载到 Azure 数据仓库、Azure SQL 数据库、Azure Cosmos DB 或业务用户可以从其商业智能工具中指向的任何分析引擎
监视器
Azure 数据工厂内置支持通过 Azure 门户上的 Azure Monitor、API、PowerShell、Azure Monitor 日志和运行状况面板进行管道监视,以监视计划的活动和管道的成功率和失败率。