了解和测试模型
我们已创建机器学习模型! 让我们测试一下,看看它的执行情况。
模型性能
自定义视觉在测试模型时显示三个指标。 这些指标是可帮助你了解模型执行情况的指示器。 这些指示器不会指示模型的真实性或准确性。 指示器只会告诉你模型在你所提供数据上的执行情况。 模型在已知数据上的执行情况可以让你了解模型在新数据上的执行情况。
为整个模型和每个类提供以下指标:
| 指标 | 说明 |
|---|---|
precision |
如果模型预测标记,则此指标表示预测正确标记的可能性有多大。 |
recall |
对于模型应正确预测的标记,此指标表示模型正确预测的标记的百分比。 |
average precision |
通过计算在不同阈值上的精准率和召回率来度量模型性能。 |
在测试自定义视觉模型时,将在迭代测试结果中看到每个指标的数值。
常见错误
在测试模型之前,先来看看一些“初学者错误”,以了解首次开始构建机器学习模型时要注意的事项。
使用不均衡数据
部署模型时,可能会看到此警告:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
该警告表明每类数据的样本数量不平均。 尽管在此方案中有多个选项,但解决不平衡数据的常见方法是使用“合成少数过度采样技术 (SMOTE)”。 SMOTE 会复制来自现有训练池的训练示例。
注意
在我们的模型中,你可能看不到此警告,尤其是在上传了数据集的一小部分时。 红尾鹰(深色变形)模型数据子集包含的照片少于 60 张,而其他模型包含的照片超过 100 张。 在任何机器学习模型中,使用不平衡的数据都是值得关注的。
过度拟合模型
如果没有足够的数据或数据不够多样化,则模型可能会过度拟合。 模型过度拟合,即模型非常了解提供给它的数据集,并过度贴合该数据中的模式。 在这种情况下,该模型在训练数据方面表现很好,但处理从未见过的新数据时表现很差。 为此,我们始终使用新数据来测试模型!
使用训练数据进行测试
与过度拟合一样,如果使用用于训练模型的相同数据来测试模型,则模型看似表现良好。 但在将模型部署到生产环境时,它很可能会表现得很差。
使用不良数据
另一种常见错误是使用不良数据来训练模型。 某些数据实际上可能会降低模型的准确性。 例如,使用“干扰”数据可能会降低模型的准确性。 在干扰性数据,数据集中有太多无用的信息,这会导致模型混淆。 只有当数据是可供模型使用的良好数据时,数据才越多越好。 可能需要清除不良数据或删除特性以提高模型准确性。
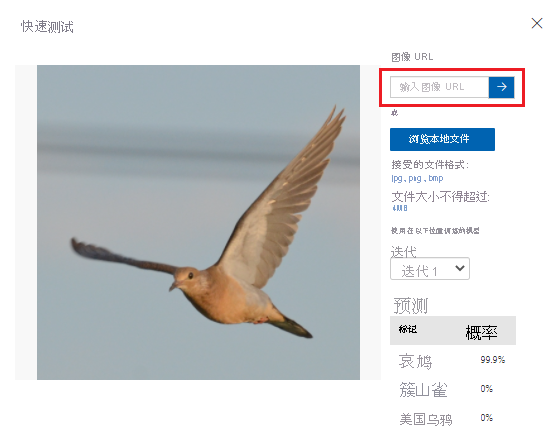
测试模型
根据自定义视觉提供的指标,我们的模型性能令人满意。 接下来测试模型,看看它处理未见过的数据时性能如何。 我们将使用来自 Internet 搜索的鸟类图像。
在 Web 浏览器中,搜索你训练该模型识别的其中一个鸟类物种的图像。 复制图像的 URL。
在自定义视觉门户中,选择“鸟类分类”项目。
在顶部菜单栏中,选择“快速测试”。
在“快速测试”中,将 URL 粘贴到“图像 URL”,然后按 Enter 测试模型的准确性。 预测将显示在窗口中。
自定义视觉分析图像以测试模型的准确性并显示结果:
下一步,我们将部署模型。 部署模型后,我们可以通过创建的终结点执行更多测试。