了解湖数据库概念
在传统的关系数据库中,数据库架构由表、视图和其他对象组成。 关系数据库中的表定义存储数据的实体,例如,零售数据库可能包括产品、客户和订单的表。 每个实体都包含一组属性,这些属性定义为表中的列,每个列都有一个名称和数据类型。 表的数据存储在数据库中,并紧密耦合到表定义;它会强制实施数据类型、可为 Null 性、键唯一性和相关键之间的引用完整性。 所有查询和数据操作都必须通过数据库系统执行。
在数据湖中,没有固定架构。 数据存储在文件中,这些文件可以是结构化的、半结构化的或非结构化的。 应用程序和数据分析师可以使用所选工具直接处理数据湖中的文件;不受关系数据库系统的约束。
湖数据库针对数据湖中的一个或多个文件提供关系元数据层。 可以创建包含表定义的湖数据库,其中包括列名和数据类型以及主键列和外键列之间的关系。 表引用数据湖中的文件,使你能够应用关系语义来处理数据以及使用 SQL 对其进行查询。 但是,数据文件的存储与数据库架构是分离的;因此其灵活性比关系数据库系统通常提供的灵活性更大。
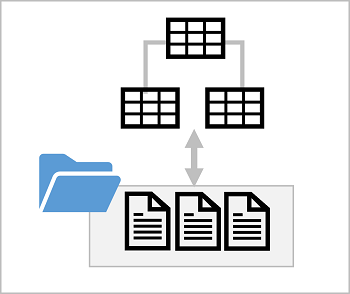
湖数据库架构
可以在 Azure Synapse Analytics 中创建湖数据库,并定义表示需要存储数据的实体的表。 可以应用经过验证的数据建模原则来创建表之间的关系,并为表、列和其他数据库对象使用适当的命名转换。
Azure Synapse Analytics 包括一个图形数据库设计界面,可使用适用于传统数据库的数据库设计的许多相同最佳做法,对复杂数据库架构进行建模。
湖数据库存储
湖数据库中表的数据以 Parquet 或 CSV 文件的形式存储在数据湖中。 这些文件可以独立于数据库表进行管理,从而更轻松地使用各种数据处理工具和技术管理数据引入和操作。
湖数据库计算
若要通过定义的表查询和操作数据,可以使用 Azure Synapse 无服务器 SQL 池来运行 SQL 查询,或者使用 Azure Synapse Apache Spark 池来通过 Spark SQL API 处理表。