缩放计算资源
云的重要优势之一是能够按需将资源缩放到系统中。 纵向扩展(预配更大的资源)或横向扩展(预配额外的资源)可通过增加容量或更广泛地分发工作负载来降低利用率,从而帮助减少系统的负载。
缩放可通过增加吞吐量来帮助提高响应度(以及用户感知的性能),因为现在可以处理大量请求。 由于减少了在单个资源的高峰负载期间排队的请求数量,这也有助于减少高峰负载期间的延迟。 此外,缩放可通过减少资源利用率并防止其接近临界点来提高系统的可靠性。
请务必注意,尽管云让我们能够轻松地预配更新或更好的资源,但成本始终是需要考虑的反面因素。 因此,即使纵向扩展或横向扩展有益,确定何时缩小或减少也很重要,以便节省成本。
水平缩放(缩小和横向扩展)
水平缩放指可随时间推移将其他资源添加到系统中或将多余资源从系统中删除的策略。 当系统上的负载以不一致或以不可预测的方式波动时,此类缩放可使服务器层受益。 波动负载的性质使得始终必须预配正确数量的资源来处理负载。
使此任务具有挑战性的一些注意事项包括
- 实例(例如,虚拟机)的启动时间
- 云服务提供商的定价模型
- 由于未及时横向扩展而使服务质量 (QoS) 降级所导致的潜在收入损失。
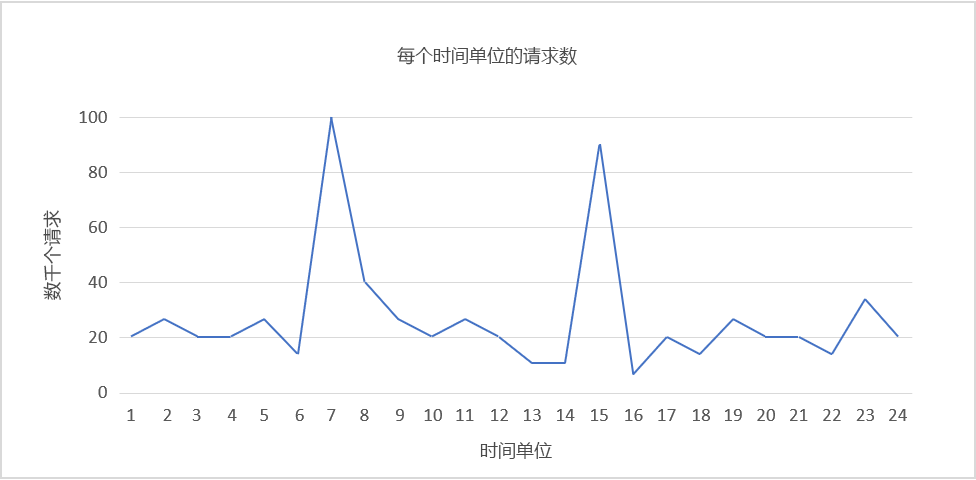
图 5:负载模式示例。
例如,考虑以上图 5 中的负载模式。
假设我们使用 Amazon Web Services,每个时间单位等效于 1 小时的实际时间,并且我们要求一台服务器处理 5,000 个请求。 时间单位 6 和 8 以及时间单位 14 和 16 之间出现需求高峰。 让我们以后者为例。 我们可以检测到在时间单位 16 附近出现需求下降,并开始减少分配的资源数量。 由于我们在 3 个小时内将大约 90,000 个请求减少到 10,000 个请求,我们可节省本来会在时间单位 15 联机的十几个或更多个实例的成本。
图 6 显示缩放模式,该模式可动态调整实例计数,从而与负载模式匹配,其中实例计数以红色显示。 在需求高峰期间,实例数分别扩展到 20 和 18,以提供处理流量所需的资源。 在其他时候,实例计数会减少(缩小),以保持资源利用率相对恒定。 如果我们假设每个实例每小时花费 20 美分,则保持 20 个实例运行 24 小时的成本为 96 美元。 如图所示缩放实例计数可将成本降低至约 42 美元,每年可节省超过 15,000 美元。 对于几乎所有 IT 预算来说,这都是一笔巨款。
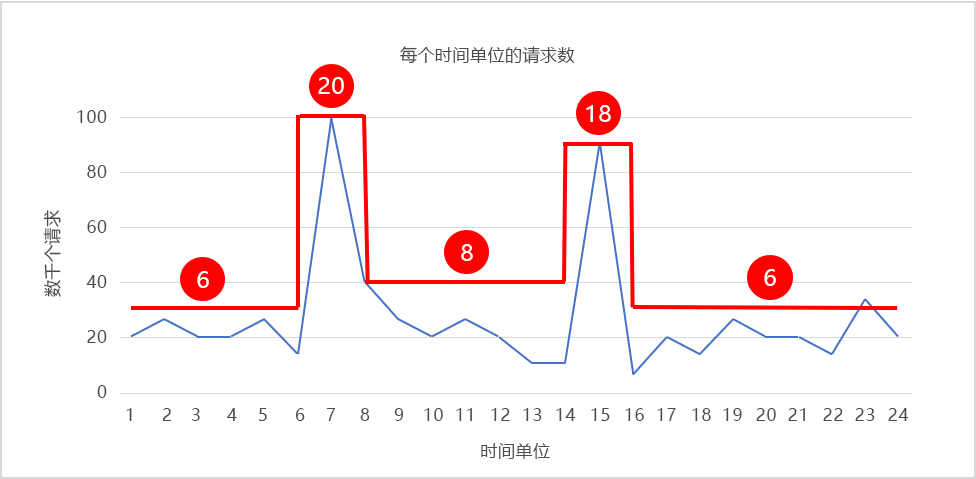
图 6:按需缩小和横向扩展。
缩放取决于流量的特性及其在 Web 服务中产生的后续负载。 如果流量遵循可预测模式(例如,基于人类行为:晚上通过 Web 服务流式播放电影),则缩放可以是可预测的,以维护 QoS。 但是,在许多实例中,无法预测流量,且缩放系统需要基于不同的标准响应。
值得注意的是,可使用容器实例以及 VM 实例来执行缩小和横向扩展。 工作负载传统上在云中的 VM 上运行,但它们在容器中运行的情况变得越来越常见。 通过增加和减少 VM 数量,基于 VM 的工作负载可实现缩放。 同样,可通过更改容器数量来缩放基于容器的工作负载。 由于容器的启动速度通常比 VM 快,其弹性会略大一些,因为新容器实例花费的联机时间少于 VM 实例花费的联机时间。
垂直缩放(纵向扩展和减少)
水平缩放是获得弹性的一种方法,但不是唯一的方法。 假设网站的流量很少在单位时间内超过 15,000 个请求,并且你预配了一个可以处理 20,000 个请求的大型实例,则这足以很好地为正常流量提供服务,并且还可以应对较小的高峰。 如果网站上的负载增加,则可以用一个 CPU 核心数量和 RAM 均为两倍的服务器实例替换原有服务器实例,从而合理地适应流量的增长。 这称为纵向扩展。
垂直缩放的主要挑战在于通常存在一些切换时间,而这些切换时间会被视为停机时间。 这是因为,为了将所有操作从较小的实例移到较大的实例,即使切换时间只有几分钟,服务质量也会在该时间间隔内降级。
垂直缩放的另一个限制是粒度降低。 如果有 10 个服务器实例联机,并且需要暂时将容量增加 10%,则可以从 10 个实例横向扩展为 11 个实例,以获得所需的结果。 但是,使用垂直缩放时,下一个更大的实例大小通常具有两倍于前一个实例的容量,这相当于将 10 个实例水平缩放为 20 个实例来适应 10% 的流量增长。 与水平缩放相比,此方法的成本效益较低。
关于垂直缩放需要考虑的最终注意事项是可用性。 如果有一个大型实例为网站的所有客户提供服务,而该实例发生故障,则网站也会发生故障。 相比之下,如果预配 10 个小型实例来处理相同的负载,而其中一个实例出现故障,用户可能会注意到性能略有下降,但他们仍然能够访问该站点。 因此,即使负载可预测并随服务受欢迎程度的增长而稳定增加,许多云管理员还是会选择水平缩放而不是垂直缩放。
缩放服务器层
有时,可伸缩性比仅预配更多的资源(横向扩展)或更大的资源(纵向扩展)更微妙。 在服务器层,需求增加会加剧对特定类型资源(例如 CPU、内存和网络带宽)的竞争。 云服务提供商通常提供针对计算密集型工作负载、内存密集型工作负载和网络密集型工作负载进行优化的 VM。 了解你的工作负载并选择正确类型的 VM 与在出现问题时提供更多或更大的 VM 一样重要。 最好使用 5 个(而不是 10 个)VM 处理计算密集型工作负载,即使针对 CPU 密集型工作负载进行了优化的 VM 的成本比普通 VM 的成本高 20%。
增加硬件资源并不总是提高服务性能的最佳解决方案。 提高服务所用算法的效率还可减少资源争用并提高利用率,从而消除缩放物理资源的需求。
关于缩放的一个重要注意事项是有状态(或无状态)。 无状态服务设计本身适用于可缩放的体系结构。 无状态服务本质上意味着客户端请求包含服务器为请求提供服务所必需的全部信息。 服务器不在实例中存储任何与客户端相关的信息,而在服务器实例中存储所有与会话相关的信息。
拥有无状态服务有助于随意切换资源,而无需进行任何配置来为后续请求维护客户端连接的上下文(状态)。 如果服务有状态,则资源缩放需要一种策略来将上下文从现有配置转移到新配置。 请注意,存在用于实现有状态服务的技术,例如,维护网络缓存,以便可以跨服务器共享上下文。
缩放数据层
在面向数据的应用程序中,如果对数据库或存储系统进行大量读取和写入操作(或两者),每个请求的往返时间通常会受硬盘读取和写入时间的限制。 较大的实例可提供更高的 I/O 性能,这可以缩短硬盘上的寻道时间,并反过来减少服务的延迟。 尽管在数据层中提供多个数据实例可通过提供故障转移冗余来提高应用程序的可靠性和可用性,但如果客户端由物理上更近的数据中心提供服务,则跨多个实例复制数据在减少网络延迟方面具有更多优势。 分片或跨多个资源进行数据分区是另一种水平数据缩放策略,该策略不会仅跨多个实例复制数据,而是将数据分区为多个段并存储在多个数据服务器中。
缩放数据层时的另一个挑战是保持一致性(所有副本上的读取操作相同)、可用性(读取和写入始终成功)和分区容错性(在故障阻止跨节点通信时维护系统中的保证属性)。 这通常称为“CAP 定理”,该定理指出,在分布式数据库系统中,很难完全获得全部三个属性,因此最多可能表现出两个属性的组合1。
参考资料
- 维基百科。 CAP Theorem。 https://en.wikipedia.org/wiki/CAP_theorem。