介绍
语言模型越来越受欢迎,因为它们为用户的问题创造了令人印象深刻的连贯答案。 尤其是当用户通过聊天与语言模型交互时,它提供了一种直观的方法来获取他们需要的信息。
通过聊天实现语言模型时,一个普遍的挑战是所谓的根基性,即响应是否植根于、连接或锚定在现实或特定上下文中。 换句话说,根基性是指语言模型的响应是否基于事实信息。
没有根据的提示和响应
使用语言模型生成对提示的响应时,模型必须作为回答的基础的唯一信息来自其训练的数据,这通常是来自 Internet 或其他源的大量未经上下文化的文本。
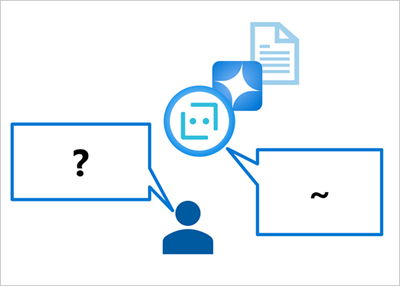
结果很可能是对提示的语法一致且有逻辑的响应,但由于它不以相关事实数据为基础,因此它未经上下文化:事实上可能不准确,并包含“发明”的信息。 例如,“我应该使用哪个产品进行 X?”这个问题可能包含虚构产品的详细信息。
有根据的提示和响应
相比之下,可以使用数据源将提示与一些相关的事实上下文连接在一起。 然后,可以将提示提交到语言模型(包括基础数据)以生成上下文化的、相关且准确的响应。
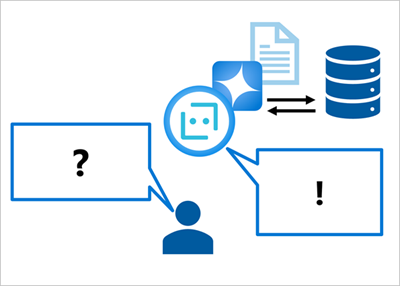
数据源可以是相关数据的任何存储库。 例如,可以使用产品目录数据库中的数据作为“我应该使用哪个产品进行 X?”这个提示的根据,使响应包含目录中存在的产品的相关详细信息。
在本模块中,你将了解如何通过使用自己的数据生成助手,以创建基于聊天且具有根基性的自有语言模型应用程序。