练习 - 构建应用程序运行状况模型
Contoso Shoes 需要一种方法来检测、诊断和预测此体系结构中的问题。 你要构建一个可通过应用于用户和系统流的运行状况状态进行度量的运行状况模型。 目标是在潜在的故障点导致中断之前识别它们。
当前状态和问题
到目前为止,你已在体系结构中添加了运行状况检查 API 并构建了多区域功能。 但是,无法深入了解包含用户和系统流的复杂拓扑。 需要填补此差距,以便 SRE 团队可以快速识别并解决问题。
在最近的一个事件中,团队无法了解影响其平台依赖项的 API 组件所导致问题的级联影响。 故障排除花费了大量时间,因为无法立即发现运行不正常的组件。 最终,这种低效导致了较长的停机时间,给公司带来了财务损失。
规范
设计可显示体系结构中所有组件(包括应用程序组件和平台依赖项)之间的关系的运行状况模型。 考虑请求流中存在的项,包括网关、计算、数据库、存储、缓存等。 还包括通常存在于请求流外部的组件。 例如,开放容器计划 (OCI) 项目、机密存储、配置服务等。 所有 Azure 服务都必须进行配置以发送诊断数据。
在体系结构中添加统一的数据接收器,用于从各种源收集数据。
基于聚合的历史日志和指标定义整体运行状况。 采用三种运行状况状态之一来表示状态:运行不正常、已降级和正常。
在表示所有流的层次结构中直观显示所有组件的运行状况。
推荐的方法
若要开始设计,建议执行以下步骤:
重要
运行状况建模是一种全面的练习。 此部分提供的方法旨在帮助你入门。 可以广泛地将模型应用于任务关键型设计中的所有功能和非功能流,以了解整个系统。
1 – 启动运行状况建模
此练习是理论性的。 在自上而下的设计活动中进行运行状况建模,你将需要体系结构中使用的组件的全面列表。 此列表应包括所有应用程序组件和 Azure 服务。
将这些组件置于显示解决方案的分层视图的依赖项关系图中。 顶层包含跟踪从最终用户到网站的请求的用户流,以及应用程序 API 级别上的流。 底层包含来自 Azure 服务的系统流。 此外,请在 Azure 资源之间映射依赖项。
你的关系图应如下所示:
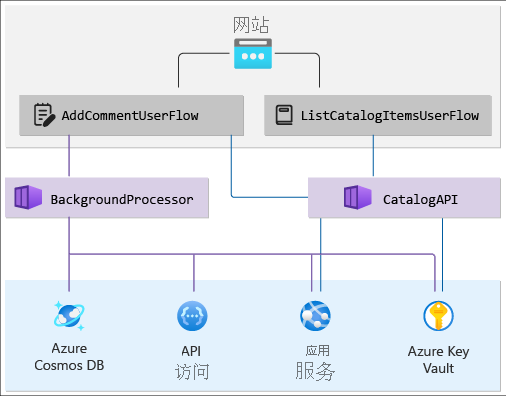
检查啊进度:分层应用程序运行状况
2 – 定义运行状况分数
对于每个组件,收集指标和指标阈值,然后确定应将组件视为正常、已降级和运行不正常时的值。 该决策应受预期性能和非功能业务要求的影响。 将指标分类为:
应用程序指标:应用程序代码中的数据点,例如异常计数。
服务指标:Azure 服务中的数据点,例如使用中的数据库事务单位 (DTU)。
解决方案指标:解决方案级别数据点,例如请求的端到端处理时间。
下面是 Azure 应用程序服务的示例:
| 应用服务 | 运行状况 |
|---|---|
| 响应时间 < 200 毫秒 HTTP 服务器错误 < 2 |
 |
| 响应时间 < 500 毫秒 HTTP 服务器错误 < 2 |
 |
| 响应时间 > 500 毫秒 HTTP 服务器错误 > 2 |
 |
3 – 定义整体运行状况
对于每个用户和系统流,定义整体状态。 需要聚合参与该流的各个组件的运行状况。
假设系统流由应用程序组件、Azure 应用服务计划和应用服务组成。
| API | 应用服务计划 | 应用服务 | 运行状况 |
|---|---|---|---|
| 最大延迟 < 30 毫秒 | CPU % < 70% HTTP 队列长度 < 5 |
响应时间 < 200 毫秒 HTTP 服务器错误 < 2 |
|
| 最大延迟 < 30 毫秒 | CPU % < 90% HTTP 队列长度 < 5 |
响应时间 < 500 毫秒 HTTP 服务器错误 < 2 |
|
| 最大延迟 > 30 毫秒 | CPU % > 90% HTTP 队列长度 > 5 |
响应时间 > 500 毫秒 HTTP 服务器错误 > 2 |
|
用户流的运行状况分数应通过所有映射组件间的最低分数来表示。 对于系统流,基于业务关键性应用适当的权重。 在两个流之间,应优先考虑财务上重要的或面向客户的用户流。
检查进度:示例 - 分层运行状况模型
4 – 收集监视数据
在每个区域中都需要一个统一的数据接收器,用于为作为区域缩放单元一部分部署的所有应用程序和平台服务收集日志和指标。 需要另一个接收器来存储从全局资源(例如 Azure Front Door 和 Cosmos DB)发出的指标。
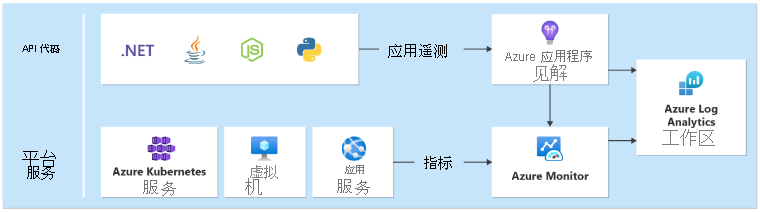
技术选择
- Azure Application Insights:用于收集所有应用程序遥测。
- Azure Monitor 日志:收集 Application insights 发送的数据和 Azure 服务的平台指标。
- Azure Log Analytics:用作中央工具,用于分析来自所有应用程序和基础结构组件的日志和指标。
检查进度:用于相关分析的统一数据接收器
5 – 设置用于监视数据的查询
Kusto 查询语言 (KQL) 与 Log Analytics 进行了良好集成。 可将自定义 KQL 查询作为函数实现,以从 Azure Monitor 检索数据。
可将自定义查询存储在代码存储库中,以便将它们作为持续集成/持续交付 (CI/CD) 管道的一部分自动导入和应用。
6 – 直观显示运行状况
可以使用交通灯表示形式来直观显示具有运行状况分数的依赖项关系图。 可使用 Azure 仪表板、Monitor 工作簿或 Grafana 等工具。 下面是一个示例:
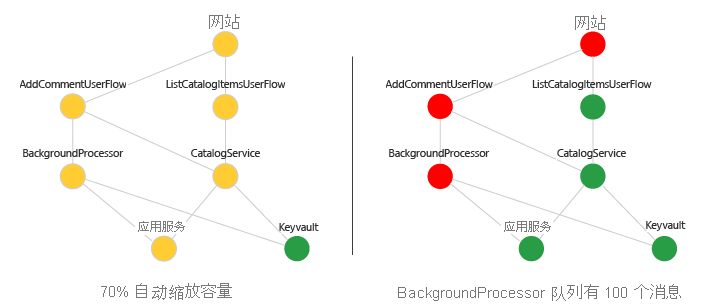
检查进度:可视化效果
7 – 对状态更改设置警报
应将仪表板与警报一起使用,以立即引起对问题的关注。
如果组件运行状况更改为“已降级”或“运行不正常”,则应立即通知操作员。 在根节点上设置警报,因为对此节点的任何更改都指示基础用户流或资源中出现运行不正常状态。
检查进度:警报
检查你的工作
观看此演示,了解监视和运行状况建模。 是否在设计中涵盖了所有方面?
- 是否有用于相关分析的统一数据接收器?
- 是否包含了应用程序日志、平台指标和解决方案数据点?
- 是否设置了仪表板以直观显示所有组件的运行状况?
- 是否考虑了每个服务(或该服务的一部分)中可能会导致服务中断或阻止缩放、部署、监视的故障点?
- 是否考虑了使用查询包来捕获有助于更快地会审问题的关键查询?
- 运行状况检查 API 是否在此模型中有所帮助? 是否需要更改该 API 以更好地适应运行状况模型?