探索事件中心捕获
使用 Azure 事件中心,可以按指定的时间间隔或大小差异在所选的 Azure Blob 存储或 Azure Data Lake Store 帐户中自动捕获事件中心的流式处理数据。 设置捕获极其简单,无需管理费用即可运行它,并且可以使用事件中心标准层中的吞吐量单位或高级层中的处理单位自动缩放它。
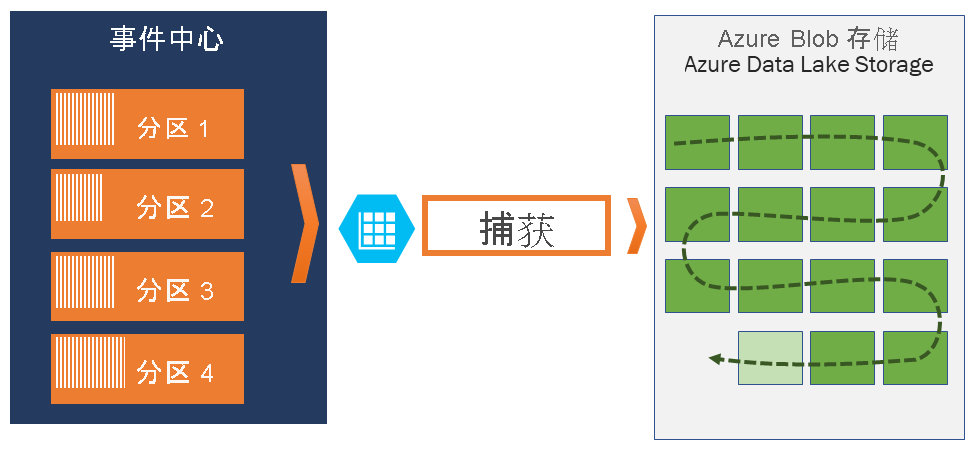
事件中心捕获可让用户在同一个流上处理实时和基于批处理的管道。 这意味着可以构建随着时间的推移随用户的需要增长的解决方案。
Azure 事件中心捕获的工作原理
事件中心是遥测数据入口的时间保留持久缓冲区,类似于分布式日志。 缩小事件中心的关键在于分区使用者模式。 每个分区是独立的数据段,并单独使用。 根据可配置的保留期,随着时间的推移此数据会过时。 因此,给定的事件中心永远不会装得“太满”。
使用事件中心捕获,用户可以指定自己的 Azure Blob 存储帐户和容器或 Azure Data Lake Store(用于存储已捕获数据)。 这些帐户可以与事件中心在同一区域中,也可以在另一个区域中,从而增加了事件中心捕获功能的灵活性。
已捕获数据以 Apache Avro 格式写入;该格式是紧凑、便捷的二进制格式,并使用内联架构提供丰富的数据结构。 这种格式广泛用于 Hadoop 生态系统、流分析和 Azure 数据工厂。 在本文后面提供了有关如何使用 Avro 的详细信息。
捕获窗口
使用事件中心捕获,用户可以设置用于控制捕获的窗口。 此窗口使用最小大小并具有使用“第一个获胜”策略的时间配置,这意味着遇到的第一个触发器将触发捕获操作。 每个分区独立捕获,并在捕获时写入已完成的块 blob,在遇到捕获间隔时针对时间进行命名。 存储命名约定如下所示:
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
请注意,日期值填充为零;示例文件名可能是:
https://mystorageaccount.blob.core.windows.net/mycontainer/mynamespace/myeventhub/0/2017/12/08/03/03/17.avro
缩放到吞吐量单位
事件中心流量由吞吐量单位控制。 单一吞吐量单位允许每秒 1 MB 或每秒 1,000 次事件的流入量和两倍的流出量。 标准事件中心可以配置 1 到 20 个吞吐量单位,可以使用增加配额支持请求来购买更多吞吐量单位。 使用在超出购买的吞吐量单位时会受到限制。 事件中心捕获直接从内部事件中心存储复制数据,从而绕过吞吐量单位出口配额,为流分析或 Spark 等其他处理读取器节省了出口量。
配置后,用户发送第一个事件时,事件中心捕获会自动运行,并持续保持运行状态。 为了让下游处理更便于了解该进程正在运行,事件中心会在没有数据时写入空文件。 此进程提供了可预测的频率以及可以供给批处理处理器的标记。