了解文本分析
在探索 Azure AI 语言服务的文本分析功能之前,让我们先了解一些用于执行文本分析和其他自然语言处理 (NLP) 任务的一般原则和常用技术。
用于通过计算机分析文本的一些最早的技术涉及对文本正文(语料库)进行统计分析,以推断某种语义。 简而言之,如果可以确定给定文档中最常用的单词,通常就可以很好地了解该文档的内容。
令牌化
分析语料库的第一步是将其分解为标记。 为简单起见,可以将训练文本中的每个不同单词视为一个标记,但实际上,可以为部分单词生成多个标记,或者将单词和标点符号组合起来。
例如,请考虑一下一个很著名的美国总统演讲中的这个短语:“we choose to go to the moon”。 该短语可以分解为以下带数字标识符的标记:
- we
- choose
- 接收方
- GO
- the
- moon
请注意,“to”(标记编号为 3)在语料库中使用了两次。 短语“we choose to go to the moon”可以用标记 [1,2,3,4,3,5,6] 表示。
注意
我们使用了一个简单的示例,为其文本中的每个不同单词标识了标记。 但是,请考虑以下可能适用于词汇切分的概念(具体取决于你尝试解决的 NLP 问题的特定类型):
- 文本规范化:在生成标记之前,可以选择通过删除标点符号并将所有单词更改为小写来规范化文本。 对于纯粹依赖词频的分析,这种方法可以提高整体性能。 但是,某些语义可能会丢失 - 例如,考虑一下这个句子:“Mr Banks has worked in many banks.”。 你可能希望所做的分析能够区分 Banks(班克斯)先生这个人和他工作的 banks(银行)。 你可能还希望将“banks.”视为“banks”的单独标记,因为包含句点意味着该单词出现在句子末尾。
- 停止字词删除。 停用词:是指应从分析中排除的字词。 例如,“the”、“a”或“it”使文本更易于供人阅读,但几乎没有语义学上的意义。 通过排除这些单词,文本分析解决方案可以更好地识别重要单词。
- N 元语法:是多词短语,如“我有”或“他走过”。 单词短语是一元语法,两词短语是二元语法,三词短语是三元语法,依此类推。 通过将字词视为组,机器学习模型可以更好地理解文本。
- “词干提取”是一种应用算法在对单词计数之前对单词进行合并的技术,目的是将词根相同的单词(例如“power”、“powered”和“powerful”)解释为相同的标记。
频率分析
对单词进行标记后,可以执行一些分析来计算每个标记出现的次数。 最常用单词(除“a”、“the”等停用词之外的单词)通常可以提供有关以下内容的线索:文本语料库的主要主题。 例如,我们之前考虑的“go to the moon”演讲全文中的最常用单词包括“new”、“go”、“space”和“moon”。 如果我们将文本标记为二元组(单词对),则该演讲中最常见的二元组是“the moon”。 从这些信息中,我们可以很容易地推测出该文本主要与太空旅行和登月有关。
提示
简单的频率分析(只需计算每个标记出现的次数)可能是分析单个文档的有效方法,但当你需要区分同一语料库中的多个文档时,则需要一种方法来确定每个文档中哪些标记最相关。 “词频 - 逆文档频率”(TF-IDF) 是一种常见技术,根据单词或术语在一个文档中出现的频率(相对于其在整个文档集合中的更一般频率而言)来计算分数。 使用这种技术时,我们假设在特定文档中频繁地出现但在众多的其他文档中相对不频繁地出现的单词具有高度相关性。
用于文本分类的机器学习
另一种有用的文本分析技术是分类算法(例如逻辑回归),可以使用它来训练机器学习模型,该模型根据一组已知的分类对文本进行分类。 此技术的常见应用是训练一个模型,将文本分为“正面”文本或“负面”文本,以便执行“情绪分析”或“观点挖掘”操作。
例如,考虑以下餐厅评论,这些评论已经被标记为 0(负面)或 1(正面):
- The food and service were both great:1
- A really terrible experience:0
- Mmm! tasty food and a fun vibe:1
- Slow service and substandard food:0
有了足够多的带标签评论,你就可以使用标记化文本作为特征并使用情绪(0 或 1)作为标签来训练分类模型。 该模型会封装标记和情绪之间的关系 - 例如,带有“great”、“tasty”或“fun”之类字词的标记的评论更有可能返回 1(正面)情绪,而包含“terrible”、“slow”和“substandard”之类字词的评论更有可能返回 0(负面)情绪。
语义语言模型
随着 NLP 技术的进步,慢慢可以训练那些封装标记之间的语义关系的模型,这就导致了强大的语言模型的出现。 这些模型的核心是将语言标记编码为向量(多值数字数组),称为“嵌入”。
将标记嵌入向量中的元素视为多维空间中的坐标可能会很有用,这样每个标记就会占据一个特定的“位置”。标记在特定的维度上彼此越近,它们在语义上的相关程度就越高。 换言之,相关单词会更紧密地组合在一起。 举个简单的例子,假设标记的嵌入由包含三个元素的向量组成,例如:
- 4 ("dog"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
我们可以在三维空间中基于这些向量绘制标记的位置,如下所示:
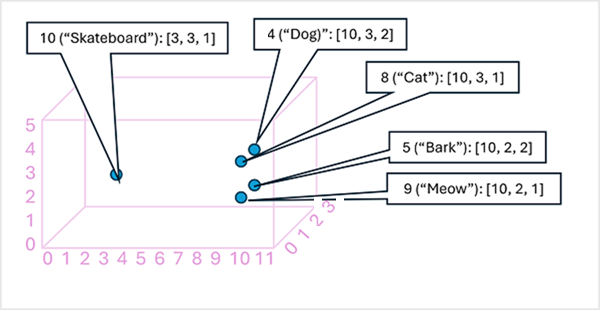
标记在嵌入空间中的位置包括一些有关标记彼此关联程度的信息。 例如,“dog”的标记接近“cat”,也接近“bark”。“cat”和“bark”的标记接近“meow”。“skateboard”的标记离其他标记更远。
我们在行业中使用的语言模型就基于这些原则,但较为复杂。 例如,使用的向量通常有更多维度。 还可通过多种方式计算给定标记集的适当嵌入。 方法不同,自然语言处理模型生成的预测也会不同。
下图显示了大多数现代自然语言处理解决方案的概括视图。 大型原始文本语料库被标记化并被用于训练语言模型,这些模型可以支持许多不同类型的自然语言处理任务。
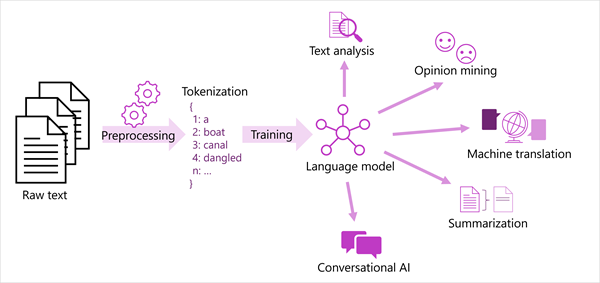
语言模型支持的常见 NLP 任务包括:
- 文本分析,例如提取关键术语或标识文本中的命名实体。
- 情绪分析和观点挖掘,用于将文本分为正面文本或负面文本。
- 机器翻译,可以自动将文本从一种语言翻译为另一种语言。
- 汇总,即汇总大型文本正文的要点。
- 对话式 AI 解决方案,例如机器人或数字助手,其中的语言模型可以解释自然语言输入并返回适当的响应。
这些功能以及更多功能均由 Azure AI 语言服务中的模型提供支持,我们接下来将对此进行探讨。