使用 KEDA 进行缩放
Kubernetes 事件驱动的自动缩放
Kubernetes 事件驱动的自动缩放 (KEDA) 是简化应用程序自动缩放的单一用途轻型组件。 可以将 KEDA 添加到任何 Kubernetes 群集,并将其与标准 Kubernetes 组件(如水平 Pod 自动缩放程序(HPA)或群集自动缩放程序)一起使用,以扩展其功能。 通过 KEDA,可以针对所需的特定应用使用事件驱动的缩放,并允许其他应用使用不同的缩放方法。 KEDA 是一个灵活且安全的选择,可以与任意数目的 Kubernetes 应用程序或框架一起运行。
关键功能和特性
- 使用缩放到零的功能构建可持续且经济高效的应用程序
- 使用 KEDA 缩放程序缩放应用程序工作负载,以满足需求
- 使用
ScaledObjects自动缩放应用程序 - 使用
ScaledJobs自动缩放作业 - 通过将自动缩放和身份验证与工作负载分离来使用生产级安全性
- 自带外部缩放程序,以使用定制的自动缩放配置
体系结构
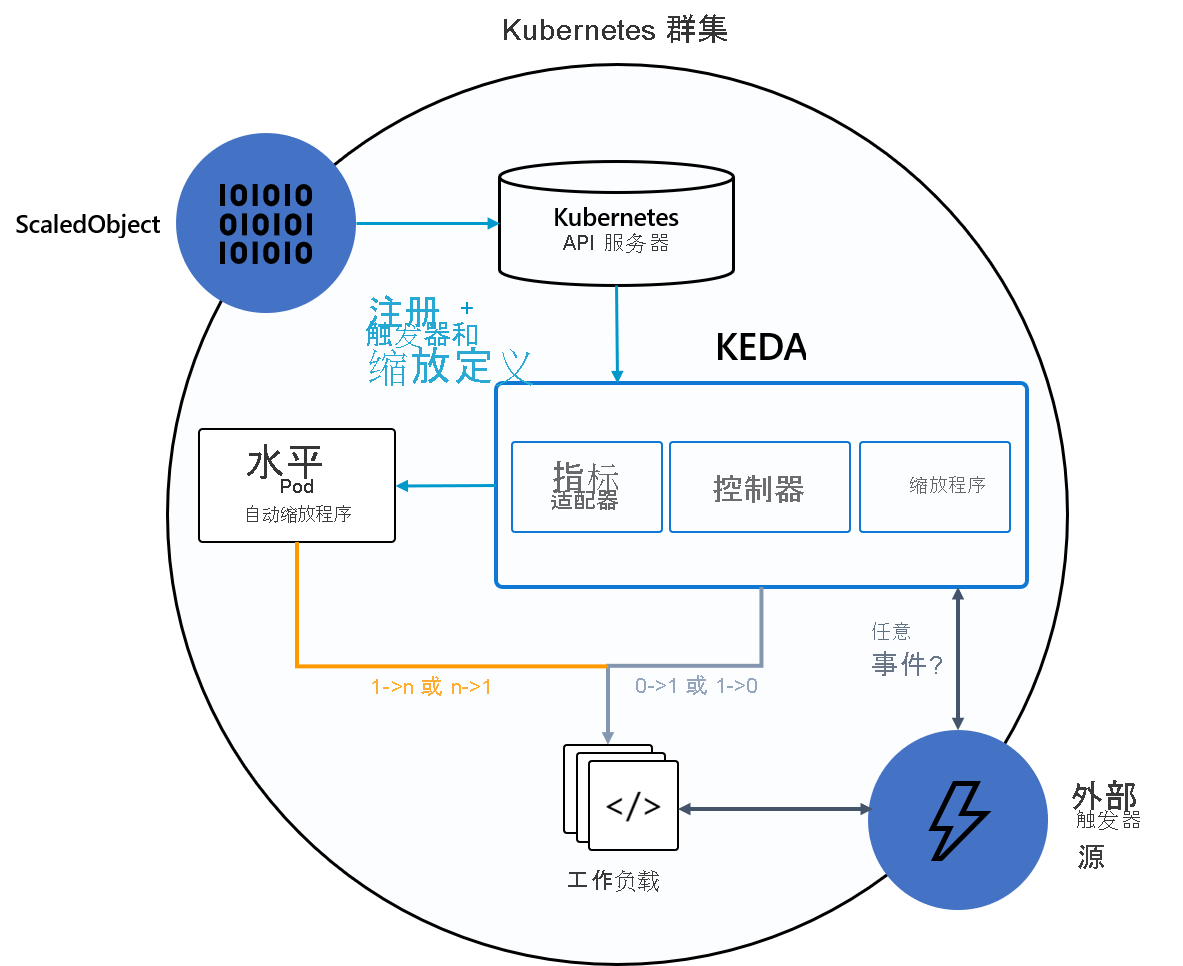
KEDA 提供两个主要组件:
- KEDA 运算符:允许最终用户在支持 Kubernetes 部署、作业、状态集或任何定义
/scale子资源的客户资源的情况下,将工作负载在零到 N 个实例之间横向缩减或扩展。 - 指标服务器:向 HPA 公开外部指标(如 Kafka 主题中的消息或 Azure 事件中心的事件),以驱动自动缩放操作。 由于上游限制,KEDA 指标服务器必须是群集中唯一安装的指标适配器。
下图显示了 KEDA 如何与 Kubernetes HPA、外部事件源和 Kubernetes 的 API 服务器集成以提供自动缩放功能:
提示
有关详细信息,请参阅官方 KEDA 文档。
事件源和缩放程序
KEDA 缩放程序可以检测应激活还是停用部署,并馈送特定事件源的自定义指标。 部署和 StatefulSet 是使用 KEDA 缩放工作负载的最常见方法。 还可以缩放实现 /scale 子资源的自定义资源。 可以定义希望 KEDA 基于缩放触发器缩放的 Kubernetes 部署或 StatefulSet。 KEDA 监视这些服务,并根据发生的事件自动横向或纵向扩展它们。
在后台,KEDA 监视事件源,并将该数据馈送到 Kubernetes 和 HPA,以推动快速资源缩放。 资源的每个副本都主动从事件源拉取项。 使用 KEDA 和 Deployments/StatefulSets,可以基于事件进行缩放,同时使用事件源(例如顺序处理、重试、死信、检查点)保留丰富的连接和处理语义。
缩放的对象规格
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
缩放作业规格
作为部署缩放事件驱动代码的替代方法,还可以以 Kubernetes 作业运行和缩放代码。 考虑此选项的主要原因是可能需要处理长期运行的执行。 每个检测到的事件都计划自己的 Kubernetes 作业,而不是在部署中处理多个事件。 使用此方法可以隔离处理每个事件,并根据队列中的事件数缩放并发执行数。
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}