使用查询存储监视工作负载的最佳做法
适用于:![]() SQL Server 2016(13.x)及更高版本
SQL Server 2016(13.x)及更高版本![]() Azure SQL 数据库 Azure SQL 托管实例
Azure SQL 数据库 Azure SQL 托管实例![]()
![]() Azure Synapse Analytics(仅限专用 SQL 池)
Azure Synapse Analytics(仅限专用 SQL 池)![]() Microsoft Fabric 中的 SQL 数据库
Microsoft Fabric 中的 SQL 数据库
本文概述使用 SQL Server 查询存储处理工作负载的最佳做法。
- 若要详细了解如何使用查询存储进行配置和管理,请参阅使用查询存储监视性能。
- 如需详细了解如何使用查询存储发现可操作信息并优化性能,请参阅使用查询存储优化性能。
- 有关在 Azure SQL 数据库中运行查询存储的信息,请参阅 在 Azure SQL 数据库中运行查询存储。
- 在 Azure Synapse Analytics 中,默认情况下,不会为专用 SQL 池启用查询存储,但可以启用。 不支持查询存储的其他配置选项。 有关详细信息,请参阅 Azure Synapse Analytics 中的历史查询存储和分析。
使用最新版 SQL Server Management Studio
SQL Server Management Studio 提供了一组用户界面,旨在配置查询存储和使用收集的工作负载数据。 下载 SQL Server Management Studio 的最新版本。
有关如何使用查询存储进行故障排除的简要说明,请参阅Query Store Azure blogs。
在 Azure SQL 数据库中使用 Query Performance Insight
如果在 Azure SQL 数据库中运行查询存储,则可使用 Query Performance Insight 来分析一定时段内的资源消耗情况。 虽然可以使用 Management Studio 和 Azure Data Studio 来获取所有查询的详细资源消耗情况(例如 CPU、内存和 I/O),但使用查询性能见解可以快速且有效地确定查询对数据库总体 DTU 消耗情况的影响。 有关详细信息,请参阅 Azure SQL Database Query Performance Insight(Azure SQL 数据库的 Query Performance Insight)。
若要 监视 Fabric SQL 数据库中的性能,请使用 性能仪表板。
将查询存储与弹性池数据库配合使用
可以毫无顾忌地在所有数据库中使用 Query Store,甚至是在密集打包的 Azure SQL 数据库弹性池中。 之前与资源过度使用(为弹性池中的大量数据库启用了查询存储时可能会遇到这种情况)相关的所有问题都已得到了解决。
开始进行查询性能故障排除
查询存储工作流的故障排除很简单,如下图所示:

按上一节的说明通过 Management Studio 来启用查询存储,或者执行以下 Transact-SQL 语句:
ALTER DATABASE [DatabaseOne] SET QUERY_STORE = ON;
查询存储收集能够准确代表工作负载的数据集需要一定的时间。 通常情况下,即使是很复杂的工作负荷,一天的时间也足够了。 但是,在启用此功能后,就可以立即开始浏览数据并确定需要注意的查询。 转到 Management Studio 的对象资源管理器中数据库节点下的查询存储子文件夹,然后打开特定方案的故障排除视图。
Management Studio Query Store 视图在操作时使用一组执行度量值,每个度量值都表示为下述任意统计函数:
| SQL Server 版本 | 执行度量值 | 统计函数 |
|---|---|---|
| SQL Server 2016 (13.x) | CPU 时间、持续时间、执行计数、逻辑读取次数、逻辑写入次数、内存消耗、物理读取次数、CLR 时间、并行度 (DOP) 和行计数 | 平均值、最大值、最小值、标准偏差、总数 |
| SQL Server 2017 (14.x) | CPU 时间、持续时间、执行计数、逻辑读取次数、逻辑写入次数、内存消耗、物理读取次数、CLR 时间、并行度、行计数、日志内存、TempDB 内存和等待时间 | 平均值、最大值、最小值、标准偏差、总数 |
下图显示了如何查找 Query Store 视图:
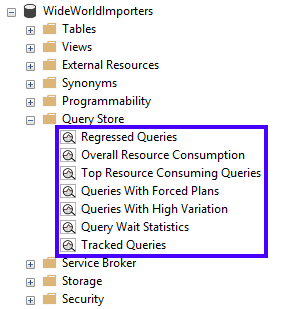
下表说明了何时使用每个 Query Store 视图:
| SQL Server Management Studio | 场景 |
|---|---|
| 回归查询 | 查明哪些查询的执行度量值最近进行了回归(例如,变得更糟)。 使用此视图将应用程序中观察到的性能问题与需要进行修复或改进的实际查询关联起来。 |
| 总体资源消耗 | 针对任意执行度量值分析数据库的总资源消耗量。 使用此视图可以确定资源模式(白天工作负荷与夜间工作负荷的比较),并优化数据库的总体消耗。 |
| 资源使用排名靠前的查询 | 选择所关注的执行度量值,确定在指定的时间间隔内具有最极端值的查询。 使用此视图可以帮助你关注最相关的查询,这些查询对数据库资源消耗的影响最大。 |
| 具有强制计划的查询 | 使用查询存储列出以前的强制计划。 使用此视图快速访问当前的所有强制计划。 |
| 变化程度高的查询 | 分析执行变化程度较高的查询,此类变化可涉及任何可用的维度,例如所需时间间隔内的持续时间、CPU 时间、IO 和内存使用情况。 使用此视图可以标识性能有很大差异且可能会影响用户跨应用程序体验的查询。 |
| 查询等待统计信息 | 分析数据库中最活跃的等待类别和对所选等待类别贡献最大的查询。 使用此视图分析等待统计信息并识别可能在应用程序中影响用户体验的查询。 适用于:从 SQL Server Management Studio v18.0 和 SQL Server 2017 (14.x) 开始。 |
| 跟踪的查询 | 实时跟踪最重要查询的执行情况。 通常情况下,使用此视图是因为你计划强制执行相关查询,因此需确保查询性能的稳定性。 |
提示
如需详细了解如何使用 Management Studio 来确定资源使用排名靠前的查询并修复那些因计划选择变化而导致回归的查询,请参阅 Query Store Azure Blogs。
如果确定某个查询的性能不够理想,则可根据问题性质进行操作。
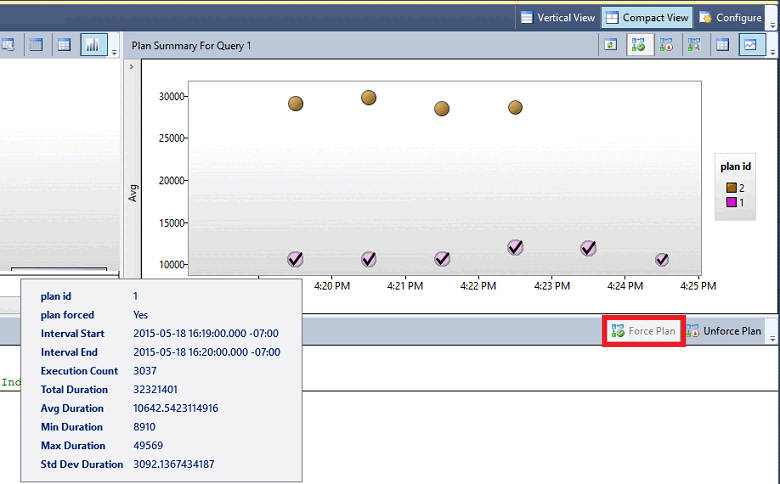
- 如果所执行的查询具有多个计划,而最后一个计划明显不如前面的计划,则可通过计划强制机制来强制使用最佳计划。 SQL Server 尝试强制实施优化器中的计划。 如果计划强制实施失败,将触发 XEvent,并指示优化器正常优化。
注意
前面的图形针对特定的查询计划会显示不同的形状,以下是可能出现的每种形状的对应含义:
| 形状 | 含义 |
|---|---|
| 圆圈 | 查询已完成,这意味着常规执行成功完成。 |
| Square | 已取消,这意味着客户端发起的执行中止。 |
| 三角形 | 失败,这意味着异常执行中止。 |
此外,形状大小反映指定时间间隔内的查询执行计数。 如果执行次数较多,该形状会变大。
- 你可以认为,你的查询因为缺少索引而无法达到最佳执行效果。 此信息显示在查询执行计划中。 使用查询存储创建缺失的索引并检查查询性能。

如果你在 SQL 数据库上运行工作负载,可注册获取 SQL 数据库索引顾问,然后即可自动接收索引建议。
- 在某些情况下,如果你看到执行计划中估计的行数和实际的行数存在显著差异,则可强制执行统计信息的重新编译。
- 重写有问题的查询,例如可以充分利用查询参数化或实现更优化的逻辑。
确保查询存储持续收集查询数据
查询存储可在无提示的情况下更改操作模式。 请定期监视查询存储的状态以确保查询存储正常运行,并采取相应措施,避免发生不必要的故障。 执行以下查询,以便确定操作模式并查看最相关的参数:
USE [QueryStoreDB];
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
actual_state_desc 和 desired_state_desc 之间存在差异,这表明自动更改了操作模式。 最常见的更改是查询存储在无提示的情况下切换到只读模式。 在极罕见的情况下,查询存储可能会因内部错误而导致处于错误状态。
当实际状态为只读时,可使用 readonly_reason 列来确定根本原因。 通常情况下,你会发现,查询存储转换为只读模式是因为超出了大小配额。 在这种情况下,readonly_reason 设置为 65536。 有关其他原因,请参阅 sys.database_query_store_options (Transact-SQL)。
考虑执行以下步骤将 Query Store 切换为读写模式并激活数据收集功能:
使用
ALTER DATABASE的MAX_STORAGE_SIZE_MB选项增大最大存储大小。使用以下语句清理 Query Store 数据:
ALTER DATABASE [QueryStoreDB] SET QUERY_STORE CLEAR;
在应用这两项或其中一项步骤时,可以执行以下语句,通过显式方式将操作模式改回为读写:
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
采用以下前摄性步骤:
- 遵循最佳实践规范即可避免在无提示情况下更改操作模式。 如果可以确保查询存储大小始终小于最大允许值,则会极大地降低转换为只读模式的几率。 根据配置查询存储部分所述,可激活基于大小的策略,使查询存储在大小接近极限时自动清除数据。
- 为了确保最新的数据能够得到保留,可将基于时间的策略配置为定期删除过时信息。
- 最后,请考虑将“查询存储捕获模式”设置为“Auto”,因为这样通常可以筛选掉与工作负载不太相关的查询。
错误状态
若要恢复查询存储,可尝试以显式方式设置读写模式,然后再次检查实际状态。
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
如果问题仍然存在,则表明磁盘上的查询存储数据已永久损坏。
从 SQL Server 2017 (14.x) 开始,可通过在受影响的数据库内执行 sys.sp_query_store_consistency_check 存储过程来恢复查询存储。 必须先禁用查询存储,然后才能尝试恢复操作。 可使用或修改以下示例查询,完成 QDS 的一致性检查和恢复:
IF EXISTS (SELECT * FROM sys.database_query_store_options WHERE actual_state=3)
BEGIN
BEGIN TRY
ALTER DATABASE [QDS] SET QUERY_STORE = OFF
Exec [QDS].dbo.sp_query_store_consistency_check
ALTER DATABASE [QDS] SET QUERY_STORE = ON
ALTER DATABASE [QDS] SET QUERY_STORE (OPERATION_MODE = READ_WRITE)
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_SEVERITY() AS ErrorSeverity
,ERROR_STATE() AS ErrorState
,ERROR_PROCEDURE() AS ErrorProcedure
,ERROR_LINE() AS ErrorLine
,ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
END
对于 SQL Server 2016 (13.x),需要从查询存储中清除数据,如下所示。
如果恢复失败,可先尝试清除查询存储,然后再设置读写模式。
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE CLEAR;
GO
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
避免使用非参数化查询
在不必要的情况下使用非参数化查询不是最佳做法。 临时分析就是一个示例。 不能重复使用缓存的计划,因为这会强制查询优化器在碰到每个唯一的查询文本时都进行查询编译。 有关详细信息,请参阅强制参数化使用指南。
此外,查询存储可能会很快超过大小配额,因为可能会存在大量不同的查询文本,导致存在大量不同但具有相同形状的执行计划。 结果就是,工作负载性能无法优化,查询存储可能会切换为只读模式,或者可能会不断删除数据以应对传入的查询。
请考虑以下选项:
- 在适用时进行参数化查询。 例如,在存储过程或
sp_executesql中包装查询。 有关详细信息,请参阅参数和执行计划重用。 - 如果工作负载包含许多一次性使用的临时批处理且查询计划各不相同,请使用针对临时工作负载进行优化选项。
- 将不同 query_hash 值的数目与
sys.query_store_query中项的总数进行比较。 如果该比率接近 1,则说明临时工作负载生成了不同的查询。
- 将不同 query_hash 值的数目与
- 如果不同查询计划的数量不多,请对数据库或部分查询应用强制参数化。
- 请参阅计划指南,仅对选定查询强制执行参数化操作。
- 如果工作负载中不同查询计划的数目很小,则使用 parameterization database option 命令配置强制的参数化操作。 例如,当不同 query_hash 的计数与
sys.query_store_query中项的总数之比远小于 1 时。
- 将
QUERY_CAPTURE_MODE设置为AUTO即可自动筛选掉资源消耗小的即席查询。
提示
使用对象关系映射 (ORM) 解决方案(如实体框架 (EF))时,手动 LINQ 查询树或某些原始 SQL 查询等应用程序查询可能不会参数化,这会影响计划重新使用以及在查询存储中跟踪查询的能力。 有关详细信息,请参阅 EF 查询缓存和参数化以及 EF 原始 SQL 查询。
在查询存储中查找非参数化查询
可以使用以下查询、查询存储 DMV、SQL Server、Azure SQL 托管实例 或Azure SQL 数据库找到存储在查询存储中的计划数:
SELECT count(Pl.plan_id) AS plan_count, Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
FROM sys.query_store_plan AS Pl
INNER JOIN sys.query_store_query AS Qry
ON Pl.query_id = Qry.query_id
INNER JOIN sys.query_store_query_text AS Txt
ON Qry.query_text_id = Txt.query_text_id
GROUP BY Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
ORDER BY plan_count desc;
以下示例创建一个扩展事件会话来捕获事件 query_store_db_diagnostics,这在诊断查询资源消耗方面很有用。 在 SQL Server 中,此扩展事件会话会默认在 SQL Server 日志文件夹中创建一个事件文件。 例如,在 Windows 上默认安装 SQL Server 2019 (15.x) 时,会在文件夹 C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\Log 中创建事件文件(.xel 文件)。 对于 Azure SQL 托管实例,请改为指定 Azure Blob 存储位置。 有关详细信息,请参阅 Azure SQL 托管实例的 XEvent event_file。 事件“qds.query_store_db_diagnostics”不适用于 Azure SQL 数据库。
CREATE EVENT SESSION [QueryStore_Troubleshoot] ON SERVER
ADD EVENT qds.query_store_db_diagnostics(
ACTION(sqlos.system_thread_id,sqlos.task_address,sqlos.task_time,sqlserver.database_id,sqlserver.database_name))
ADD TARGET package0.event_file(SET filename=N'QueryStore',max_file_size=(100))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF);
使用这些数据,可以查找查询存储中的计划计数,以及许多其他统计信息。 在事件数据中查找 plan_count、query_count、max_stmt_hash_map_size_kb 和 max_size_mb 列,了解使用的内存量和查询存储跟踪的计划数量。 如果计划计数高于正常值,则表示非参数化查询有所增加。 使用以下查询存储 DMV 查询查看查询存储中的参数化查询和非参数化查询。
对于参数化查询:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE qsq.query_parameterization_type<>0 or qsqt.query_sql_text like '%@%';
对于非参数化查询:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE query_parameterization_type=0;
避免对包含对象使用 DROP 和 CREATE 模式
查询存储会将查询条目与包含对象(例如存储过程、函数和触发器)相关联。 重新创建包含对象时,会针对同一查询文本生成新的查询条目。 这会阻止你跟踪该查询在一定时段内的性能统计信息,并会使用计划强制机制。 若要避免这种情况,请尽可能使用 ALTER <object> 过程来更改包含对象定义。
定期检查强制计划的状态
可以方便地使用计划强制机制来修复关键查询的性能问题,使这些查询的结果更可预测。 与计划提示和计划指南一样,强制实施某项计划并不能确保在今后的执行过程中会用到它。 通常情况下,如果对数据库架构的更改导致执行计划所引用的对象被更改或删除,计划强制就会失败。 在这种情况下,SQL Server 会回退到重新编译查询,而强制失败的实际原因则显示在 sys.query_store_plan 中。 以下查询返回强制计划的相关信息:
USE [QueryStoreDB];
GO
SELECT p.plan_id, p.query_id, q.object_id as containing_object_id,
force_failure_count, last_force_failure_reason_desc
FROM sys.query_store_plan AS p
JOIN sys.query_store_query AS q on p.query_id = q.query_id
WHERE is_forced_plan = 1;
有关原因的完整列表,请参阅 sys.query_store_plan。 你还可以使用 query_store_plan_forcing_failed XEvent 来跟踪和故障排除计划强制失败情况。
避免在使用强制计划执行查询时重命名数据库
执行计划使用由三个部分组成的名称(例如 database.schema.object)来引用对象。
如果重命名数据库,计划强制就会失败,导致在执行所有后续的查询时都需要重新编译。
在任务关键型服务器中使用查询存储
全局跟踪标志 7745 和 7752 可用于使用查询存储来提高数据库的可用性。 有关更多信息,请参见跟踪标记。
- 跟踪标志 7745 会阻止以下默认行为:在可关闭 SQL Server 之前,查询存储将数据写入磁盘。 这意味着在
DATA_FLUSH_INTERVAL_SECONDS定义的时间窗口之前,已收集但尚未保留到磁盘的查询存储数据将会丢失。 - 跟踪标志 7752 启用了查询存储的异步加载。 这会使数据库变为联机状态,并且在查询存储完全恢复之前执行查询。 默认行为是同步加载查询存储。 默认行为可在恢复查询存储之前防止执行查询,但同时也可在数据集合中防止遗漏任何查询。
注意
从 SQL Server 2019 (15.x) 开始,此行为由引擎控制,跟踪标志 7752 不再有效。
重要
如果仅对 SQL Server 2016 (13.x) 中的实时工作负载见解使用查询存储,请尽快安装 SQL Server 2016 (13.x) SP2 CU2 (KB 4340759) 中的性能可伸缩性改进。 如果没有这些改进,则当数据库处于繁重的工作负载下时,可能会发生旋转锁争用,并且服务器性能可能会变慢。 特别是,你可能会发现 QUERY_STORE_ASYNC_PERSIST 旋转锁或 SPL_QUERY_STORE_STATS_COOKIE_CACHE 旋转锁上出现繁重的争用情况。 应用此改进后,查询存储将不再导致旋转锁争用。
重要
如果你在 SQL Server(SQL Server 2016 (13.x) 到 SQL Server 2017 (14.x))中使用查询存储来获取实时工作负载见解,请尽快在 SQL Server 2016 (13.x) SP2 CU15、SQL Server 2017 (14.x) CU23 和 SQL Server 2019 (15.x) CU9 中安装性能可伸缩性改进功能。 如果没有此改进,则当数据库处于繁重的即席工作负载下时,查询存储可能会占用大量内存,并且服务器性能可能会变慢。 应用此改进后,查询存储会对其各个组件可使用的内存量施加内部限制,并且可以自动将操作模式更改为只读,直到有足够的内存返回到数据库引擎。 不会记录查询存储内部内存限制,因为它们随时可能更改。
在 Azure SQL 数据库活动异地复制中使用查询存储
Azure SQL 数据库的辅助活动异地复制上的查询存储将是主要副本上的活动的只读副本。
避免在使用 Azure SQL 数据库异地复制时出现不匹配的层。 辅助数据库在大小方面应与主数据库相同或相近,并且应与主数据库处于同一服务层。 在 sys.dm_db_wait_stats 中查找 HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO 等待类型,该类型表示由于辅助延迟而导致主要副本上的事务日志速率受限。
若要详细了解如何估计和配置活动异地复制的辅助 Azure SQL 数据库的大小,请参阅配置辅助数据库。
始终根据工作负载调整查询存储
本文扩展了有关配置和管理查询存储的最佳做法和建议:管理查询存储的最佳做法。