对 JSON 数据编制索引
适用范围:![]() SQL Server 2016 (13.x) 及更高版本
SQL Server 2016 (13.x) 及更高版本![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例
可以使用标准索引优化对 JSON 文档的查询。 SQL Server 没有自定义 JSON 索引。
- 目前在 SQL Server 中,json 不属于内置数据类型。
- JSON 数据类型目前以预览版提供Azure SQL 数据库和Azure SQL 托管实例(配置了 Always-up-to-date 更新策略)。
索引的工作方式与 varchar/nvarchar 或本机 json 数据类型中的 JSON 数据相同。
数据库索引可提升筛选和排序操作的性能。 如果没有索引,每次查询数据时,SQL Server 不得不扫描整个表。
通过使用计算列对 JSON 属性编制索引
将 JSON 数据存储在 SQL Server 中时,通常会希望按 JSON 文档的一个或多个属性对查询结果进行筛选或排序。
示例
此示例假定 AdventureWorks.SalesOrderHeader 表包含 Info 列,此列包含关于销售订单的采用 JSON 格式的各种信息。 例如,包含客户、销售人员、装运和帐单邮寄地址等非结构化数据。 可使用 Info 列的值来筛选某个客户的销售订单。
默认情况下,所用的 Info 列不存在,可使用以下代码在 AdventureWorks 数据库中创建它。 以下示例不适用于 AdventureWorksLT 系列的示例数据库。
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
要优化的查询
以下示例说明可使用索引进行优化的查询类型。
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
示例索引
如果想要加快对 JSON 文档中某属性的筛选或 ORDER BY 子句的速度,可使用已用于其他列的索引。 但是,不能直接引用 JSON 文档中的属性。
- 首先创建一个“虚拟列”,用于返回你要用于筛选的值。
- 然后,对该虚拟列创建索引。
下面的示例创建可用于编制索引的计算列。 然后对此计算列创建索引。 此示例创建一个公开客户名称的列,名称存储在 JSON 数据中的 $.Customer.Name 路径中。
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
此语句将返回以下警告:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
JSON_VALUE 函数最多可以返回 8000 个字节的文本值(例如,作为 nvarchar(4000) 类型)。 但是,不能对长度超过 1700 字节的值编制索引。 如果尝试在索引计算列中输入长度超过 1700 字节的值,那么数据操作语言 (DML) 操作将失败。
为了提升性能,请尝试将使用计算列公开的值强制转换为最小的适用数据类型。 可以将 string 类型替换为 int 和 datetime2 类型。
关于计算列的详细信息
计算列是非持久化的。 仅在需要重新生成索引时对计算列进行计算。 它不会在表中占用额外空间。
需使用计划在查询中使用的同一表达式来创建计算列,这一点很重要 - 在此示例中该表达式为 JSON_VALUE(Info, '$.Customer.Name')。
无须重新编写查询。 如果使用带有 JSON_VALUE 函数的表达式(如前面的示例查询所示),SQL Server 会认为存在具有相同表达式的等效计算列,并会在可能的情况下应用索引。
此示例的执行计划
下面是此示例中查询的执行计划。
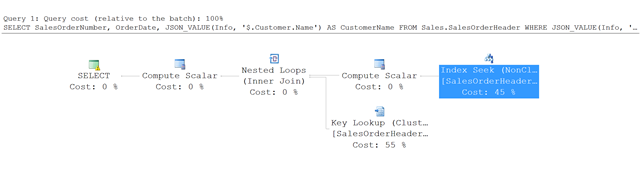
SQL Server 在非聚集索引中使用索引查找而非进行全表扫描,由此找到满足指定条件的行。 然后它在 SalesOrderHeader 表中使用键查找来提取查询中引用的其他列 - 在此示例中为 SalesOrderNumber 和 OrderDate。
通过包含的列进一步优化索引
如果在索引中添加所需的列,则可避免在表中进行这一附加查找。 可将这些列作为标准包含列添加,如以下示例中所示,这是对前面的 CREATE INDEX 示例的延伸。
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
在这种情况下,SQL Server 不必从 SalesOrderHeader 表中读取其他数据,因为所需内容已全部包含在非聚集 JSON 索引中。 这种索引是在查询中将 JSON 和列数据相结合以及为工作负载创建最佳索引的一个好方法。
JSON 索引是可识别排序规则的索引
索引可识别排序规则,这是针对 JSON 数据的一个重要索引功能。 创建计算列时使用的 JSON_VALUE 函数的结果是一个文本值,该值从输入表达式继承其排序规则。 因此,将使用源列中定义的排序规则对索引中的值进行排序。
为了阐释索引可识别排序规则,下面的示例创建具有主键和 JSON 内容的一个简单集合表。
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
前一个命令指定 json 列的塞尔维亚西里尔文排序规则。 后面的示例填充表,并对名称属性创建索引。
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
前面的命令对计算列 vName 创建标准索引,它表示 JSON $.name 属性的值。 在塞尔维亚西里尔文代码页中,字母的顺序是 А、Б、В、Г、Д、Ђ、Е 等。索引中的项的顺序符合塞尔维亚西里尔文规则,因为 JSON_VALUE 函数的结果从源列继承其排序规则。 下面的示例查询此集合并按名称对结果进行排序。
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
如果查看实际的执行计划,会发现它使用非聚集索引中经过排序的值。

虽然查询具有 ORDER BY 子句,但执行计划不使用 Sort 运算符。 此时已根据塞尔维亚西里尔文规则对 JSON 索引进行了排序。 因此 SQL Server 可使用其中的结果已经过排序的非聚集索引。
但是,如果更改 ORDER BY 表达式的排序规则(例如,如果将 COLLATE French_100_CI_AS_SC 添加到 JSON_VALUE 函数之后),会得到其他查询执行计划。

由于索引中的值的顺序不符合法语排序规则,所以 SQL Server 无法使用索引对结果进行排序。 因此,它会添加一个使用法语排序规则对结果进行排序的 Sort 运算符。
Microsoft 视频
注意
此部分中的某些视频链接在此时可能不起作用。 Microsoft 会将以前在第 9 频道上的内容迁移到新平台。 随着视频迁移到新平台,我们将更新链接。
有关 SQL Server 和 Azure SQL 数据库中内置 JSON 支持的视频介绍,请观看以下视频: