使用缺失索引建议优化非聚集索引
适用于:![]() SQL Server
SQL Server ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例 ![]() Microsoft Fabric SQL 数据库
Microsoft Fabric SQL 数据库
缺失索引功能是一种轻量工具,用于查找可显著提高查询性能的缺失索引。 本文介绍如何使用缺失索引建议来有效地优化索引并提高查询性能。
缺失索引功能的限制
当查询优化器生成查询计划时,它将分析什么是用于特定筛选条件的最佳索引。 如果不存在最佳索引,查询优化器仍会使用成本最低的可用访问方法生成查询计划,但也会存储有关这些索引的信息。 使用缺失索引功能,你可以访问有关最佳索引的信息以决定是否实现它们。
查询优化是一个有时效性的过程,因此缺失索引功能存在限制。 限制包括:
- 缺失索引建议基于在查询执行之前优化单个查询期间所做的估算。 查询执行后,不会测试或更新缺失索引建议。
- 缺失索引功能建议仅使用基于磁盘的行存储非聚集索引。 不建议使用唯一和筛选索引。
- 建议使用键列,但该建议未指定这些列的顺序。 有关对列进行排序的信息,请参阅本文的应用缺失的索引建议部分。
- 建议使用包含列,然而,当包含列数量过大时,SQL Server 不会对所得索引的大小进行成本效益分析。
- 缺失索引请求可能会在查询中对同一表和列提供类似的索引变体。 查看索引建议并尽可能合并非常重要。
- 不会针对普通查询计划提出建议。
- 对于只涉及不等谓词的查询,成本信息不太准确。
- 最多收集 600 个缺失索引组的建议。 达到此阈值后,不会收集更多缺少的索引组数据。
由于这些限制,在执行索引分析、设计、优化和测试时,最好将缺失索引建议视为多种信息源之一。 缺失索引建议并不是完全按照建议创建索引的规定。
注意
Azure SQL 数据库提供自动索引优化。 自动索引优化使用机器学习通过 AI 从 Azure SQL 数据库中的所有数据库横向学习,并动态改进其优化操作。 自动索引优化包括一个验证过程,以确保工作负载性能通过创建的索引能得到显著改善。
查看缺失索引建议
缺失索引功能包含两个组件:
- 执行计划的 XML 中的
MissingIndexes元素。 通过该元素,你可以将查询优化器认为缺失的索引与索引缺失的查询相关联。 - 一组动态管理视图 (DMV),可对其进行查询以返回有关缺失索引的信息。 这样,便可以查看数据库的所有缺失索引建议。
查看执行计划中的缺失索引建议
可以通过多种方式生成或获取查询执行计划:
- 编写或优化查询时,可以使用 SQL Server Management Studio (SSMS) 来显示估计的执行计划而不运行查询,或执行查询并显示实际执行计划。
- 查询存储启用后将收集执行计划。
- 可以通过查询 DMV(例如 sys.dm_exec_text_query_plan)来识别缓存的执行计划。
例如,可以使用以下查询针对 AdventureWorks 示例数据库生成缺失索引请求。
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
生成和查看缺失索引请求:
打开 SSMS 并将会话连接到 AdventureWorks 示例数据库副本。
通过选择“显示估计的执行计划”工具栏按钮,将查询粘贴到会话中并在 SSMS 中为查询生成估计的执行计划。 执行计划随即显示在当前会话的窗格中。 图形计划顶部附近将显示一个绿色的 Missing Index 语句。
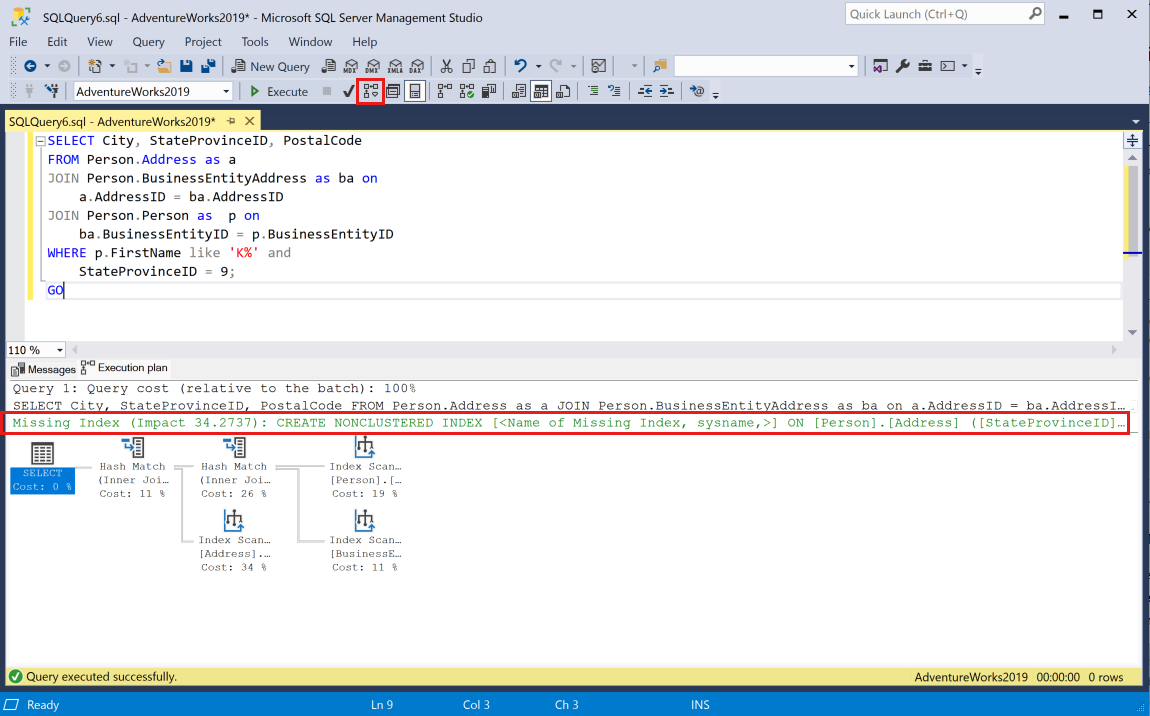
单个执行计划可能包含多个缺失索引请求,但图形执行计划中只能显示一个缺失索引请求。 查看执行计划缺失索引的完整列表的一种方法是查看执行计划 XML。
右键单击执行计划并从菜单中选择“显示执行计划 XML...”。
执行计划 XML 将在 SSMS 中作为新选项卡打开。
注意
即使执行计划 XML 中存在多个建议,“缺失索引详细信息...”菜单选项中也只会显示一个缺失索引建议。 显示的缺失索引建议可能不是对查询估计改进最大的建议。
使用 CTRL+f 快捷方式显示“查找”对话框。
搜索
MissingIndex。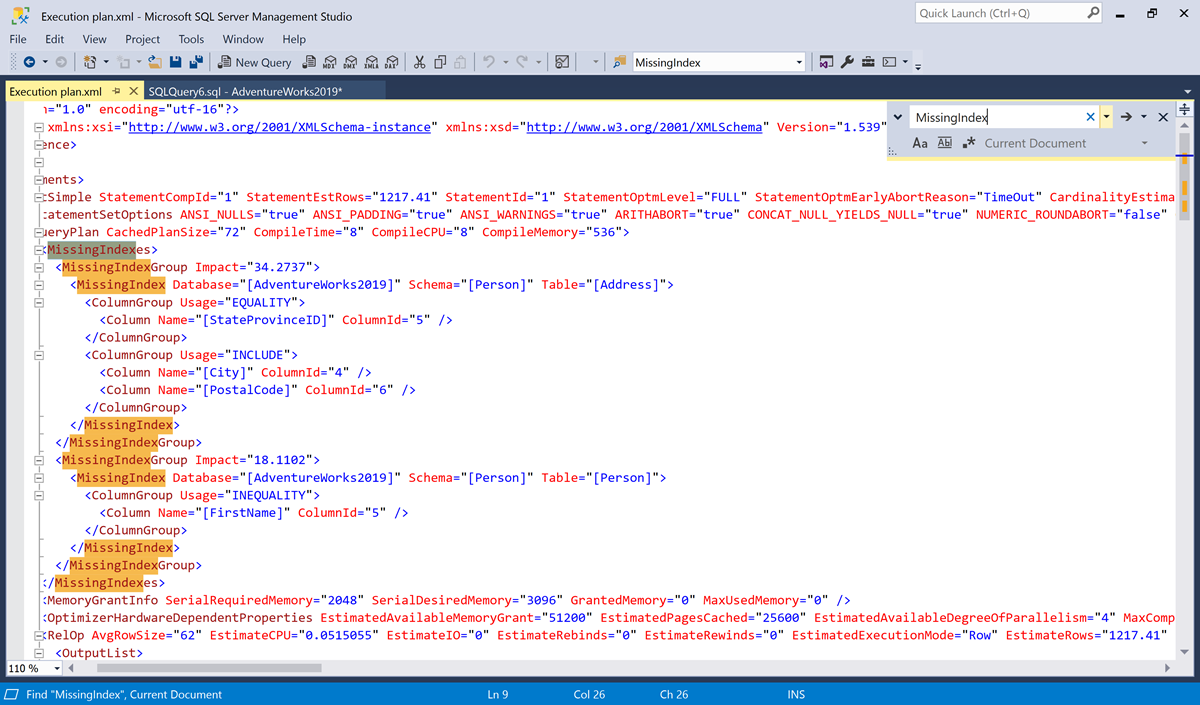
在此示例中,有两个
MissingIndex元素。


数据库中每个基于磁盘的非聚集索引都会占用空间,增加插入、更新和删除的开销,并且可能需要维护。 出于这些原因,最佳做法是先查看表的所有缺失索引请求和表的现有索引,然后再根据查询执行计划添加索引。
查看 DMV 中的缺失索引建议
可通过查询下表中列出的动态管理对象检索有关缺失索引的信息。
| 动态管理视图 | 返回的信息 |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | 返回有关缺失索引组的摘要信息,例如,通过实现一组特定的缺失索引可以获得的性能改进。 |
| sys.dm_db_missing_index_groups (Transact-SQL) | 返回有关特定组缺失索引的信息,例如组标识符以及该组中包含的所有缺失索引的标识符。 |
| sys.dm_db_missing_index_details (Transact-SQL) | 返回有关缺失索引的详细信息,例如它返回缺少索引的表的名称和标识符,以及构成缺失索引的列和列类型。 |
| sys.dm_db_missing_index_columns (Transact-SQL) | 返回与缺少索引的数据库表列有关的信息。 |
以下查询使用缺失索引 DMV 生成 CREATE INDEX 语句。 此处的索引创建语句旨在帮助你在检查表的所有请求以及表上的现有索引后创建自己的 DDL。
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
此查询按名为 estimated_improvement 的列对建议进行排序。 估计的改进由以下内容共同决定:
- 与缺失索引请求关联的查询的估计查询成本。
- 添加索引的估计影响。 这是对非聚集索引将在多大程度上降低查询成本的估计。
- 已针对与缺失索引请求关联的查询运行的查询运算符(查找和扫描)的执行总和。 正如我们在使用查询存储保留缺失索引中所讨论的,此信息会定期清除。
注意
Microsoft 的 Tiger Toolbox 中的 Index-Creation 脚本会检查缺失索引 DMV,并自动删除所有多余的建议索引,解析出影响较小的索引,并生成索引创建脚本供你查看。 与上面的查询一样,它不会执行索引创建命令。 Index-Creation 脚本适用于 SQL Server 和 Azure SQL 托管实例。 对于 Azure SQL 数据库,请考虑实现自动索引优化。
在创建索引之前查看缺失索引功能的限制以及如何应用缺失索引建议,并修改索引名称以匹配数据库的命名约定。
使用查询存储保留缺失索引
DMV 中的缺失索引建议会因实例重启、故障转移和将数据库设置为脱机等事件而清除。 此外,当表的元数据发生更改时,有关此表的所有缺失索引信息都将从这些动态管理对象中删除。 举例来说,当向表添加或从中删除列时,或者当对表的列创建索引时,可能会发生表元数据更改。 对表的索引执行 ALTER INDEX REBUILD 操作也会清除该表的缺失索引请求。
同样,存储在计划缓存中的执行计划也会因实例重启、故障转移和将数据库设置为脱机等事件而清除。 由于内存压力和重新编译,可能会从缓存中删除执行计划。
通过启用查询存储,可以在这些事件中保留执行计划中的缺失索引建议。
以下查询根据查询的总逻辑读取的大致估计,检索包含查询存储缺少索引请求的前 20 个查询计划。 数据仅限于过去 48 小时内的查询执行。
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
应用缺失索引建议
若要有效地使用缺失索引建议,请遵循非聚集索引设计指南。 当优化缺失索引建议的非聚集索引时,请查看基表结构,仔细合并索引,考虑键列顺序,并查看包含列建议。
查看基表结构
在根据缺失索引建议对表创建非聚集索引之前,请查看表的聚集索引。
检查聚集索引的一种方法是使用 sp_helpindex 系统存储过程。 例如,我们可以通过执行以下语句来查看 Person.Address 表的索引摘要:
exec sp_helpindex 'Person.Address';
GO
查看 index_description 列。 一个表只能包含一个聚集索引。 如果已为表实施了聚集索引,则 index_description 将包含“聚集”一词。

如果不存在聚集索引,则该表为堆。 在这种情况下,请检查表是否有意创建为堆以解决特定的性能问题。 大多数表都可从聚集索引中受益:通常,表是意外被实现为堆的。 考虑根据聚集索引设计指南实现聚集索引。
查看缺失索引和现有索引是否有重叠
缺失索引可能会在查询中对同一表和列提供类似的非聚集索引变体。 缺失索引也可能类似于表上的现有索引。 为获得最佳性能,最好检查缺失索引和现有索引是否重叠,避免创建重复索引。
为表上的现有索引编写脚本
检查表上现有索引的定义的一种方法是使用对象资源管理器详细信息编写索引:
- 将对象资源管理器连接到实例或数据库。
- 在对象资源管理器中展开相关数据库的节点。
- 展开 “表” 文件夹。
- 展开要为其索引编写脚本的表。
- 选择索引文件夹。
- 如果“对象资源管理器详细信息”窗格尚未打开,请在“视图”菜单上选择“对象资源管理器详细信息”或按 F7。
- 使用快捷方式 CTRL+a 选择“对象资源管理器详细信息”窗格中列出的所有索引。
- 右键单击所选区域中的任意位置并选择菜单选项“将索引脚本编写为”,然后选择“创建至”和“新查询编辑器窗口”。

查看索引并尽可能合并
以组的形式查看一个表的缺失索引建议,以及该表上现有索引的定义。 请记住,在定义索引时,通常应将相等列放在不等列之前,并且它们应一起构成索引的键。 若要确定相等列的有效顺序,请基于其选择性排序:首先列出选择性最强的列(列列表中的最左侧)。 唯一列的选择性最强,而具有许多重复值的列选择性较弱。
应该使用 INCLUDE 子句将包含列添加到 CREATE INDEX 语句。 包含列的顺序不会影响查询性能。 因此,合并索引时,可以合并包含列,而不用担心顺序。 有关详细信息,请参阅包含列指南。
例如,可能有一个表 Person.Address,其键列 StateProvinceID 上存在一个现有索引。 对于以下列,可能会看到 Person.Address 表的缺失索引建议:
StateProvinceID和City的相等筛选器StateProvinceID和City的相等筛选器,包括PostalCode
修改现有索引以匹配第二个建议,具有 StateProvinceID 和 City 上的键(包括 PostalCode)的索引可能会满足生成两个索引建议的查询。
权衡在索引优化中很常见。 对于许多数据集,City 列可能比 StateProvinceID 列更具选择性。 但是,如果我们在 StateProvinceID 上的现有索引被大量使用,并且其他请求主要在 StateProvinceID 和 City 上进行搜索,则对于数据库而言,具有在键中同时包含这两个列的单个索引所产生的开销较低,以 StateProvinceID 为前导列,虽然它并不是选择性最强的列。
可通过多种方式修改索引:
- 可以将 CREATE INDEX 语句与 DROP_EXISTING 子句一起使用。 可能希望在修改后重命名索引,以便名称仍然准确地描述索引定义,具体取决于自己的命名约定。
- 你可以使用 DROP INDEX (Transact-SQL) 语句,后跟 CREATE INDEX 语句。
合并索引建议时,索引键的顺序很重要:City 作为前导列与 StateProvinceID 作为前导列并不一样。 有关详细信息,请参阅非聚集索引设计指南。
创建索引时,请考虑使用联机索引操作(如果可用)。
虽然索引在某些情况下可以显着提高查询性能,但索引也有开销和管理成本。 请查看常规索引设计指南,以帮助在创建索引之前评估索引的好处。
验证索引更改是否成功
务必确认索引更改是否成功:查询优化器是否使用索引?
验证索引更改的一种方法是使用查询存储来识别缺失索引请求的查询。 请注意查询的 query_id。 使用查询存储中的“跟踪的查询”视图检查查询的执行计划是否已更改,以及优化器是否正在使用新索引或修改后的索引。 在开始进行查询性能故障排除中了解有关跟踪查询的详细信息。
相关内容
有关索引和性能优化的详细信息,请参阅以下文章: