堆(没有聚集索引的表)
适用于:![]() SQL Server
SQL Server ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例 ![]() Microsoft Fabric SQL 数据库
Microsoft Fabric SQL 数据库
堆是不含聚集索引的表。 可在存储为堆的表上创建一个或多个非聚集索引。 数据存储于堆中并且无需指定顺序。 通常,数据最初是按照插入行的顺序存储的。 但是,数据库引擎可以在堆中移动数据以高效地存储行。 在查询结果中,无法预测数据顺序。 若要确保从堆返回的行的顺序,使用 ORDER BY 子句。 若要指定用于存储行的永久逻辑顺序,请对表创建聚集索引,以便表不是堆。
注意
有时候可能有必要将表保留为堆,而不是创建聚集索引,但高效率地使用堆需要较高的技能。 大多数表应该具有仔细选择的聚集索引,除非有足够的理由将表保留为堆。
何时使用堆
堆非常适合经常被截断和重新加载的表。 数据库引擎通过填充最早的可用空间来优化堆中的空间。
考虑以下情况:
- 在堆中查找可用空间的成本可能很高,尤其是在有许多删除或更新的情况下。
- 聚集索引为不经常被截断的表提供稳定的性能。
对于经常被截断或重新创建的表(如临时表),使用堆通常更高效。
在使用堆和聚集索引之间选择可能会显著影响数据库的性能和效率。
在将某个表存储为堆时,通过引用由文件号、数据页码和页上的槽 (FileID:PageID:SlotID) 构成的 8 字节行标识符 (RID),标识单独行。 行 ID 是一个小且高效的结构。
可使用堆作为临时表来暂存大型无序插入操作。 由于插入数据时不应用严格的顺序,因此插入操作通常比插入到聚集索引的等效操作更快。 如果要读取堆的数据并将其处理成最终目标,创建一个包含查询所用搜索谓词的窄带非聚集索引可能会很有用。
注意
按数据页面的顺序从堆中检索数据,但这不一定是插入数据的顺序。
始终通过非聚集索引访问数据且 RID 小于聚集索引键时,有时数据专业人员也会使用堆。
如果某个表是堆并且不具有任何非聚集索引,则必须读取整个表(表扫描)以便找到任何行。 SQL Server 无法直接在堆上查找 RID。 当表较小时,此行为可以接受。
何时不使用堆
在经常以排序后的顺序返回数据时,不要使用堆。 排序列上的聚集索引可以避免排序操作。
在数据经常组合在一起时,不要使用堆。 数据必须首先进行排序,然后才能分组,并且排序列上的聚集索引可以避免排序操作。
在经常从表查询数据范围时,不要使用堆。 范围列上的聚集索引避免对整个堆进行排序。
在不存在非聚集索引并且表比较大时,不要使用堆。 此设计的唯一应用是在没有任何指定顺序的情况下返回整个表内容。 在堆中,数据库引擎会读取所有行以查找任何行。
如果数据经常更新,请不要使用堆。 如果更新记录,并且更新在数据页中使用的空间比当前使用的空间多,则必须将记录移动到具有足够可用空间的数据页。 这会创建指向数据的新位置的前推记录,并且前推指针必须在以前保存该数据的页中写入,以指示新的物理位置。 这会在堆中引入碎片。 当数据库引擎扫描堆时,它会遵循这些指针。 此操作会限制预读性能,并且可能会产生额外的 I/O,从而降低扫描性能。
管理堆
若要创建堆,请创建没有聚集索引的表。 如果表已具有某一聚集索引,则删除该聚集索引以便将该表返回到某一堆。
若要删除堆,请在该堆上创建聚集索引。
重新生成堆以回收浪费的空间:
- 在该堆上创建一个聚集索引,然后删除该聚集索引。
- 使用
ALTER TABLE ... REBUILD命令重新生成堆。
警告
创建或删除聚集索引要求重写整个表。 如果该表具有非聚集索引,则只要更改聚集索引,就必须全都重新创建所有非聚集索引。 因此,从堆更改为聚集索引结构或反之可能占用大量时间,并且要求足够的磁盘空间以便对 tempdb 中的数据重新进行排序。
识别堆
以下查询会返回当前数据库中的堆列表。 此列表包括:
- 表名
- 架构名称
- 行数
- 表大小 (KB)
- 索引大小 (KB)
- 未使用的空间
- 用于识别堆的列
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
堆结构
堆是不含聚集索引的表。 堆的 sys.partitions中具有一行,对于堆使用的每个分区,都有 index_id = 0 。 默认情况下,一个堆有一个分区。 当堆有多个分区时,每个分区有一个堆结构,其中包含该特定分区的数据。 例如,如果一个堆有四个分区,则有四个堆结构;每个分区有一个堆结构。
根据堆中的数据类型,每个堆结构将有一个或多个分配单元来存储和管理特定分区的数据。 每个堆中每个分区至少有一个 IN_ROW_DATA 分配单元。 如果堆包含大型对象 (LOB) 列,则该堆的每个分区还将有一个 LOB_DATA 分配单元。 如果堆包含超过 8,060 字节的行大小限制的变量长度列,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
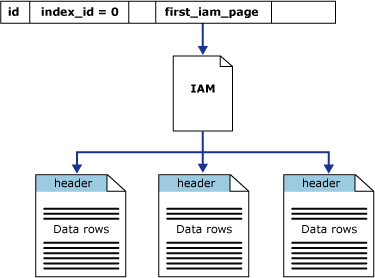
first_iam_page 系统视图中的列 sys.system_internals_allocation_units 指向 IAM 页链中的第一个 IAM 页,该 IAM 页链可管理分配给特定分区中的堆的空间。 SQL Server 使用 IAM 页在堆之间移动。 堆内的数据页和行没有任何特定的顺序,也不链接在一起。 数据页之间唯一的逻辑连接是记录在 IAM 页内的信息。
重要
sys.system_internals_allocation_units 系统视图保留为仅供 SQL Server 内部使用。 不保证以后的兼容性。
可以通过扫描 IAM 页对堆进行表扫描或串行读操作来找到容纳该堆的页的扩展盘区。 因为 IAM 按扩展盘区在数据文件内存在的顺序表示它们,所以这意味着串行堆扫描连续沿每个文件进行。 使用 IAM 页设置扫描顺序还意味着堆中的行一般不按照插入的顺序返回。
下图说明了 SQL Server 数据库引擎如何使用 IAM 页检索单个分区堆中的数据行。
相关内容
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
描述的聚集索引和非聚集索引