教程:通过 SQL 机器学习在 R 中构建聚类分析模型
适用于: ![]() SQL Server 2016 (13.x) 及更高版本
SQL Server 2016 (13.x) 及更高版本 ![]() Azure SQL 托管实例
Azure SQL 托管实例
此系列教程由四个部分组成,这是第三部分。你将在 R 中构建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将在 SQL Server 机器学习服务中或大数据群集上将此模型部署到数据库中。
此系列教程由四个部分组成,这是第三部分。你将在 R 中构建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将使用 SQL Server 机器学习服务将此模型部署到数据库中。
此系列教程由四个部分组成,这是第三部分。你将在 R 中构建一个 K-Means 模型来执行聚类分析。 在此系列的下一部分中,你将使用 SQL Server R Services 将此模型部署到数据库中。
此系列教程由四个部分组成,这是第三部分。你将在 R 中构建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将使用 Azure SQL 托管实例机器学习服务在数据库中部署此模型。
本文将指导如何进行以下操作:
- 定义 K-Means 算法的群集数
- 执行聚类分析
- 分析结果
在第一部分中,你安装了必备条件并还原了示例数据库。
在第二部分中,你了解了如何从数据库准备数据以执行聚类分析。
在第四部分中,你将了解如何在数据库中创建存储过程,以便基于新数据在 R 中执行聚类分析。
先决条件
定义群集数
若要对客户数据进行聚类分析,需要使用 K-Means 聚类分析算法,这是最简单、最常见的数据分组方法之一。 有关 K-Means 的详细信息,请参阅 K-means 聚类分析算法的完整指南。
该算法接受两个输入:数据本身,以及代表要生成的群集数的预定义数字“k”。 输出是 K 个群集,输入数据在群集之间进行分区。
要确定要使用的算法的群集数,请使用组内平方和的图,并按提取的群集数进行绘制。 要使用的适当群集数是在曲线的折弯处或“肘形”处。
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
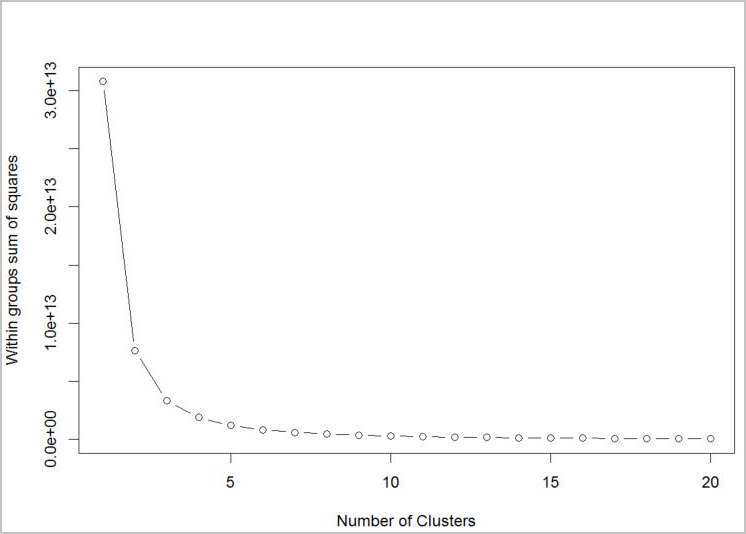
根据该图,看起来 k = 4 将是一个不错的尝试值。 该 ķ 值将客户分组为四个群集。
执行聚类分析
在下面的 R 脚本中,你将使用函数 kmeans 来执行聚类分析。
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
分析结果
使用 K 平均值完成聚类后,下一步是分析结果,并看看是否可以找到任何可行的信息。
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
使用第二部分中定义的变量给出四种群集平均值:
- orderRatio = 退单率(部分或全部退货的订单总数与订单总数的比率)
- itemsRatio = 退货率(退货总数与购买商品数量的比率)
- monetaryRatio = 退款率(退货的总货币金额与购买总金额的比率)
- frequency = 退货频率
使用 K-Means 进行数据挖掘通常需要对结果进行进一步的分析,并采取进一步的步骤以更好地理解每个群集,但是它可以提供一些优秀的潜在顾客。 下面通过以下几种方法来解释这些结果:
- 聚类 1(最大聚类)似乎是不太活跃的客户组(所有值均为零)。
- 群集 3 似乎是一个在返回行为方面出现的组。
清理资源
如果不打算继续学习本教程,请删除 tpcxbb_1gb 数据库。
后续步骤
在此教程系列的第三部分中,你已了解如何执行以下操作:
- 定义 K-Means 算法的群集数
- 执行聚类分析
- 分析结果
若要部署已创建的机器学习模型,请按照本系列教程的第四部分进行操作: