教程:使用 Spark 作业将数据引入 SQL Server 数据池
适用于: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
本教程演示如何使用 Spark 作业将数据加载到 SQL Server 2019 大数据群集 的数据池。
在本教程中,你将了解如何执行以下操作:
- 在数据池中创建外部表。
- 创建 Spark 作业以从 HDFS 加载数据。
- 在外部表中查询结果。
提示
如果需要,可以下载并运行本教程中的命令脚本。 有关说明,请参阅 GitHub 上的数据池示例。
先决条件
- 大数据工具
- kubectl
- Azure Data Studio
- SQL Server 2019 扩展
- 将示例数据加载到大数据群集中
在数据池中创建外部表
以下步骤会在数据池中创建一个名为“web_clickstreams_spark_results”的外部表 。 然后,可以将此表用作将数据引入到大数据群集的位置。
在 Azure Data Studio 中,连接到大数据群集的 SQL Server 主实例。 有关详细信息,请参阅连接到 SQL Server 主实例。
双击“服务器”窗口中的连接,以显示 SQL Server 主实例的服务器仪表板 。 选择“新建查询” 。
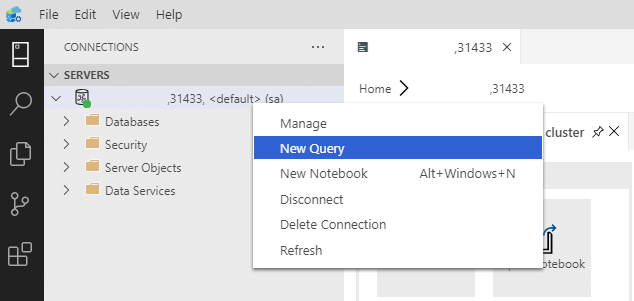
为 MSSQL-Spark 连接器创建权限。
USE Sales CREATE LOGIN sample_user WITH PASSWORD ='<password>' CREATE USER sample_user FROM LOGIN sample_user -- To create external tables in data pools GRANT ALTER ANY EXTERNAL DATA SOURCE TO sample_user; -- To create external tables GRANT CREATE TABLE TO sample_user; GRANT ALTER ANY SCHEMA TO sample_user; -- To view database state for Sales GRANT VIEW DATABASE STATE ON DATABASE::Sales TO sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user ALTER ROLE [db_datawriter] ADD MEMBER sample_user如果尚未创建数据池的外部数据源,请创建该数据源。
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');在数据池中创建一个名为“web_clickstreams_spark_results”的外部表 。
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstreams_spark_results') CREATE EXTERNAL TABLE [web_clickstreams_spark_results] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );为数据池创建登录名,并向用户提供权限。
EXECUTE( ' Use Sales; CREATE LOGIN sample_user WITH PASSWORD = ''<password>;'') AT DATA_SOURCE SqlDataPool; EXECUTE('Use Sales; CREATE USER sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user; ALTER ROLE [db_datawriter] ADD MEMBER sample_user;') AT DATA_SOURCE SqlDataPool;
创建数据池外部表是一项锁定操作。 在所有后端数据池节点上创建指定表后,控制权恢复。 如果在创建操作期间发生故障,便会向调用方返回错误消息。
启动 Spark 流式处理作业
下一步是创建一个 Spark 流式处理作业,将 Web 点击流数据从存储池 (HDFS) 加载到你在数据池中创建的外部表。 此数据已添加到将示例数据加载到大数据群集中的 /clickstream_data。
在 Azure Data Studio 中,连接到大数据群集的主实例。 有关详细信息,请参阅连接到大数据群集。
创建新笔记本并选择 Spark | Scala 作为内核。
运行 Spark 引入作业
- 配置 Spark-SQL 连接器参数
注意
如果大数据群集通过 Active Directory 集成进行部署,请替换下面的主机名的值,以包含附加到服务名称的 FQDN。 例如 hostname=master-p-svc.<domainName>.
import org.apache.spark.sql.types._ import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} // Change per your installation val user= "username" val password= "<password>" val database = "MyTestDatabase" val sourceDir = "/clickstream_data" val datapool_table = "web_clickstreams_spark_results" val datasource_name = "SqlDataPool" val schema = StructType(Seq( StructField("wcs_click_date_sk",LongType,true), StructField("wcs_click_time_sk",LongType,true), StructField("wcs_sales_sk",LongType,true), StructField("wcs_item_sk",LongType,true), StructField("wcs_web_page_sk",LongType,true), StructField("wcs_user_sk",LongType,true) )) val hostname = "master-p-svc" val port = 1433 val url = s"jdbc:sqlserver://${hostname}:${port};database=${database};user=${user};password=${password};"- 定义并运行 Spark 作业
- 每个作业都有两部分:readStream 和 writeStream。 下面,我们使用上面定义的架构创建数据帧,然后将其写入到数据池中的外部表。
import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} val df = spark.readStream.format("csv").schema(schema).option("header", true).load(sourceDir) val query = df.writeStream.outputMode("append").foreachBatch{ (batchDF: DataFrame, batchId: Long) => batchDF.write .format("com.microsoft.sqlserver.jdbc.spark") .mode("append") .option("url", url) .option("dbtable", datapool_table) .option("user", user) .option("password", password) .option("dataPoolDataSource",datasource_name).save() }.start() query.awaitTermination(40000) query.stop()
查询数据
以下步骤演示了 Spark 流式处理作业将数据从 HDFS 加载到数据池中。
在查询引入的数据之前,请查看 Spark 执行状态(包括 Yarn 应用 ID、Spark UI 和驱动程序日志)。 当你首次启动 Spark 应用程序时,此信息显示在笔记本中。
返回到本教程开头部分打开的 SQL Server 主实例查询窗口。
运行以下查询以检查引入的数据。
USE Sales GO SELECT count(*) FROM [web_clickstreams_spark_results]; SELECT TOP 10 * FROM [web_clickstreams_spark_results];还可以在 Spark 中查询数据。 例如,下面的代码将打印表中记录的数量:
def df_read(dbtable: String, url: String, dataPoolDataSource: String=""): DataFrame = { spark.read .format("com.microsoft.sqlserver.jdbc.spark") .option("url", url) .option("dbtable", dbtable) .option("user", user) .option("password", password) .option("dataPoolDataSource", dataPoolDataSource) .load() } val new_df = df_read(datapool_table, url, dataPoolDataSource=datasource_name) println("Number of rows is " + new_df.count)
清除
使用以下命令删除本教程中创建的数据库对象。
DROP EXTERNAL TABLE [dbo].[web_clickstreams_spark_results];
后续步骤
了解如何在 Azure Data Studio 中运行示例笔记本: