在 Spark History Server 中调试和诊断 SQL Server 大数据群集 上的 Spark 应用程序
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
本文提供有关如何使用扩展的 Spark History Server 调试和诊断 SQL Server 大数据群集中的 Spark 应用程序的指南。 这些调试和诊断功能内置于 Spark History Server 中且由 Microsoft 提供支持。 扩展插件包括“数据”选项卡和“图形”选项卡以及“诊断”选项卡。在“数据”选项卡中,用户可以检查 Spark 作业的输入和输出数据。 在“图形”选项卡中,用户可以检查数据流并重播作业图。 在“诊断”选项卡中,用户可以参考数据倾斜、时间偏差和执行程序使用情况分析。
开始使用 Spark History Server
开放源代码提供的 Spark History Server 用户体验丰富了以下内容,其中包括作业特定数据、作业图的交互式可视化效果和大数据群集数据流。
通过 URL 打开 Spark History Server Web UI
通过浏览到以下 URL 打开 Spark History Server,并将 <Ipaddress> 和 <Port> 替换为大数据群集特定信息。 对于在 SQL Server 2019 CU 5 之前部署且具有基本身份验证(用户名/密码)大数据群集设置的群集,当系统提示登录网关 (Knox) 终结点时,必须提供 root 用户的登录信息。 请参阅部署 SQL Server 大数据群集。 从 SQL Server 2019 (15.x) CU 5 开始,当使用基本身份验证部署新群集时,所有终结点(包括网关)都使用 AZDATA_USERNAME 和 AZDATA_PASSWORD。 升级到 CU 5 的群集上的终结点继续使用 root 作为用户名连接到网关终结点。 此更改不适用于使用 Active Directory 身份验证的部署。 请参阅发行说明中的通过网关终结点访问服务所用的凭据。
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Spark History Server Web UI 如下所示:
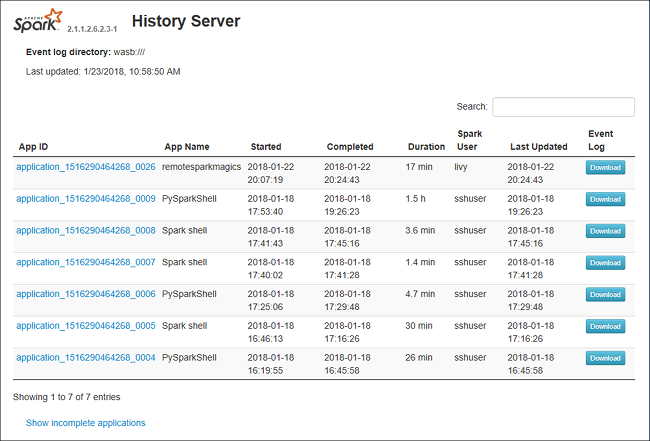
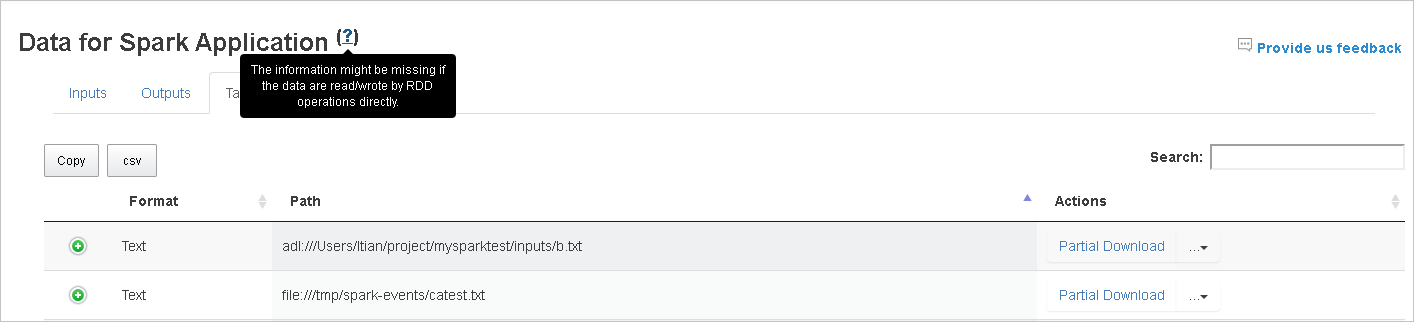
Spark History Server 中的“数据”选项卡
选择作业 ID,然后单击工具菜单上的“数据”以获取数据视图。
分别选择“输入”、“输出”和“表操作”,以选中这些选项卡 。
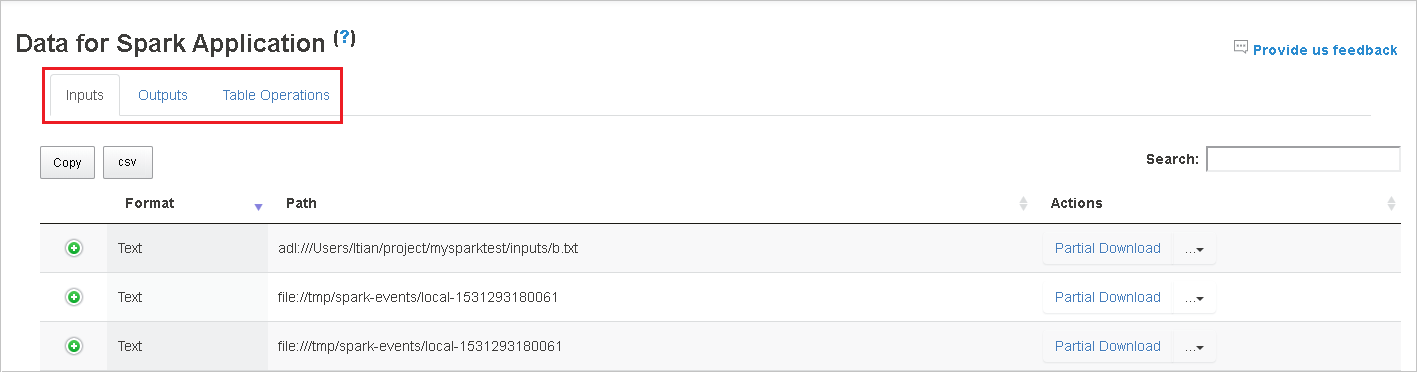
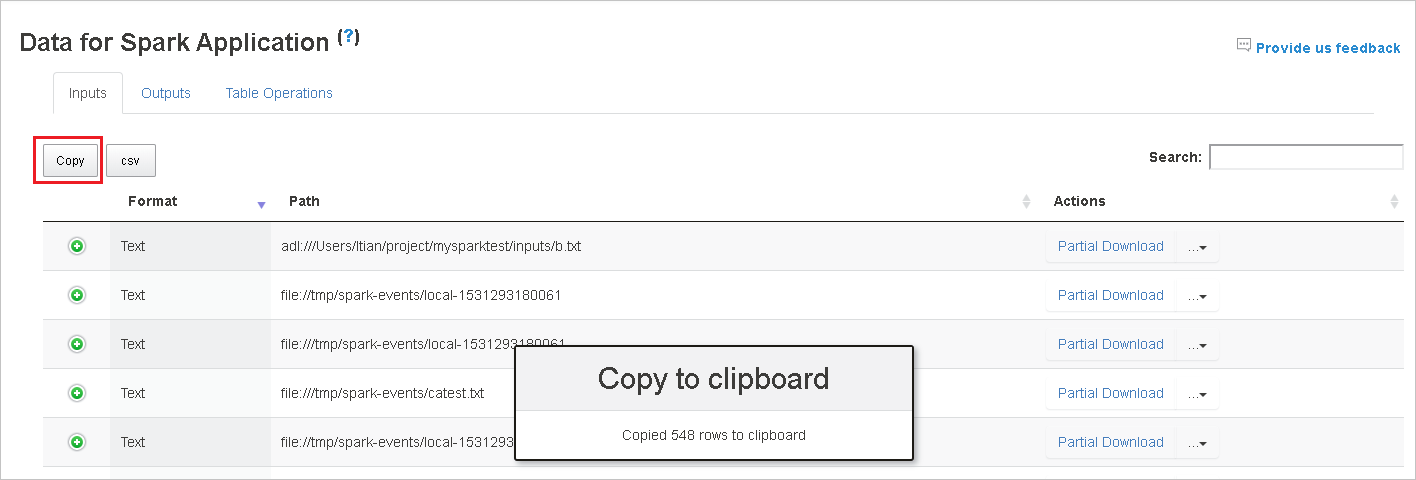
单击“复制”按钮,复制所有行。
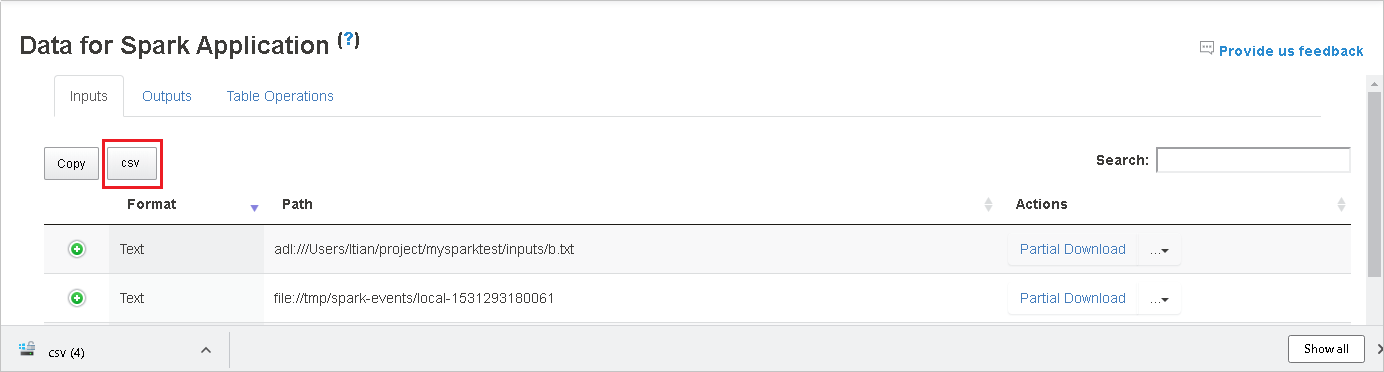
单击“csv”按钮,将所有数据另存为 CSV 文件。
在“搜索”字段中输入关键字进行搜索,搜索结果将立即显示。
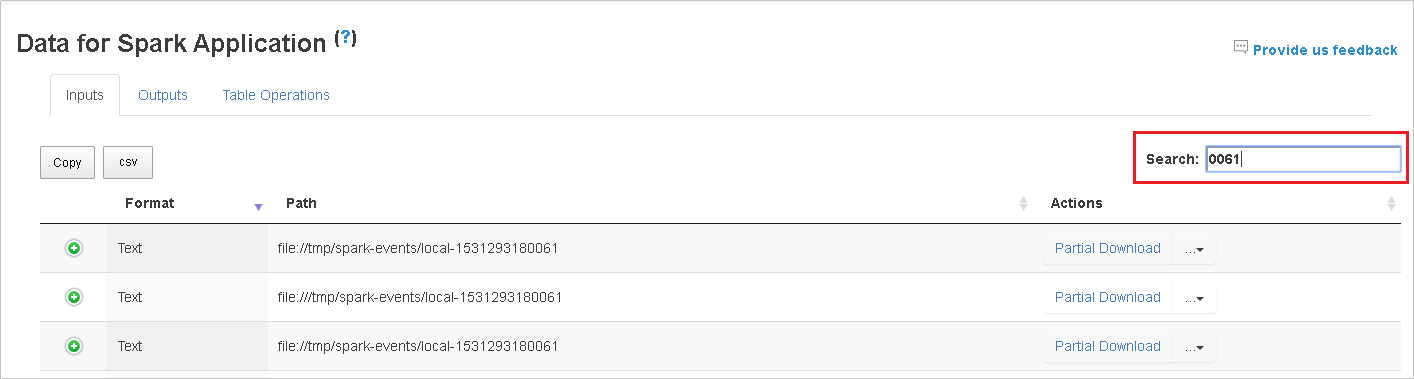
单击列标题以对表进行排序,单击加号展开行以显示更多详细信息,或单击减号以折叠行。
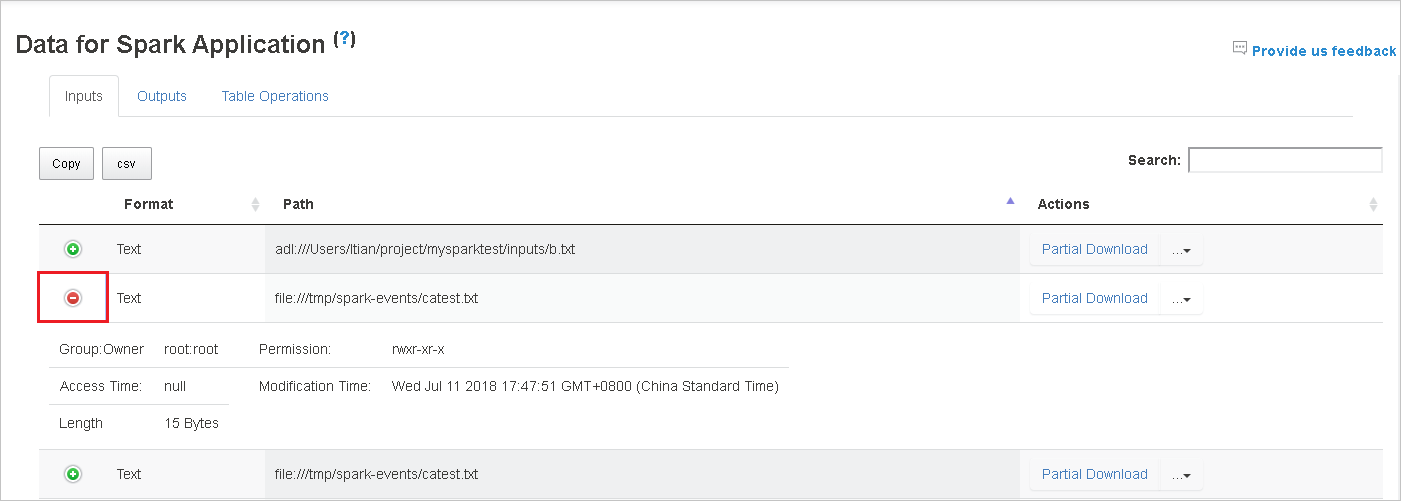
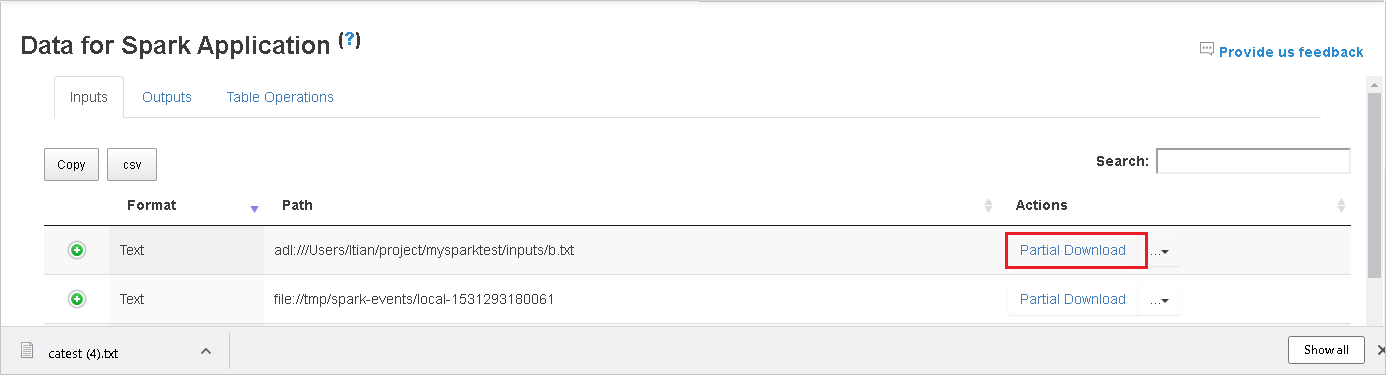
单击右侧的“部分下载”按钮,下载单个文件,然后将所选文件下载到本地位置。 如果该文件不存在,则打开一个新选项卡以显示错误消息。
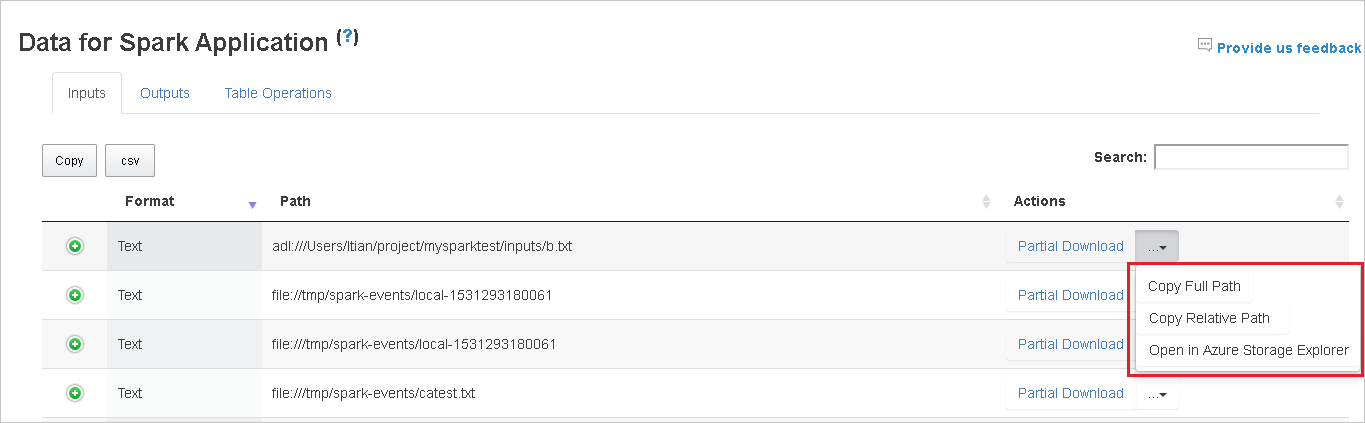
选择从下载菜单展开的“复制完整路径”和“复制相对路径”,复制完整路径或相对路径 。 对于 azure data lake storage 文件,单击“在 Azure 存储资源管理器中打开”启动 Azure 存储资源管理器。 并在登录时找到确切的文件夹。
如果要在一个页面中显示多个行,请单击表格下方的数字以导航页面。

将鼠标悬停在“数据”旁边的问号上以显示工具提示,或单击问号以获取更多信息。
单击“向我们提供反馈”,发送相关问题的反馈。
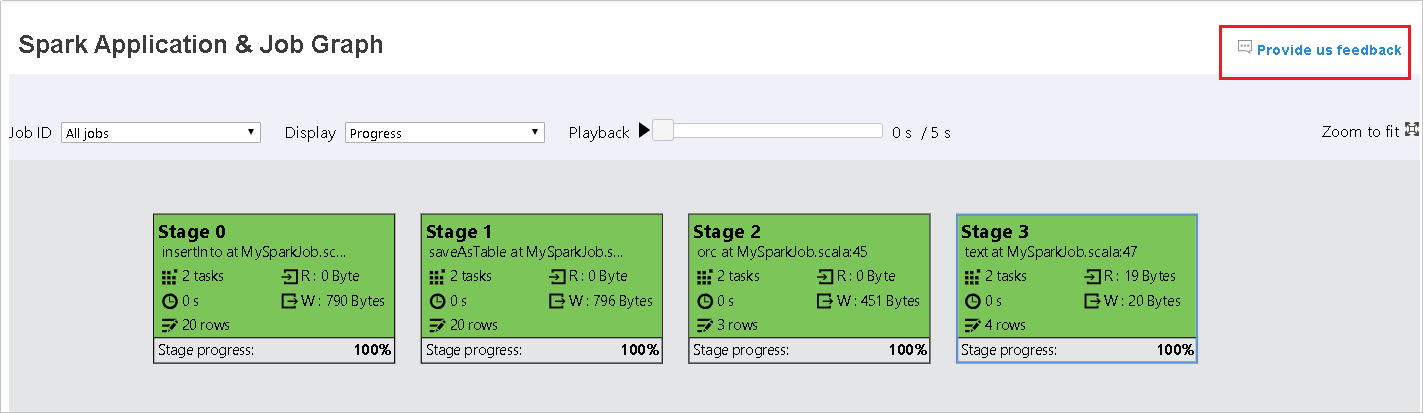
Spark History Server 中的“图形”选项卡
选择作业 ID,然后单击工具菜单上的“图形”以获取作业图视图。
按生成的作业图检查作业概述。
默认情况下,它将显示所有作业,并且可以按“作业 ID”进行筛选。
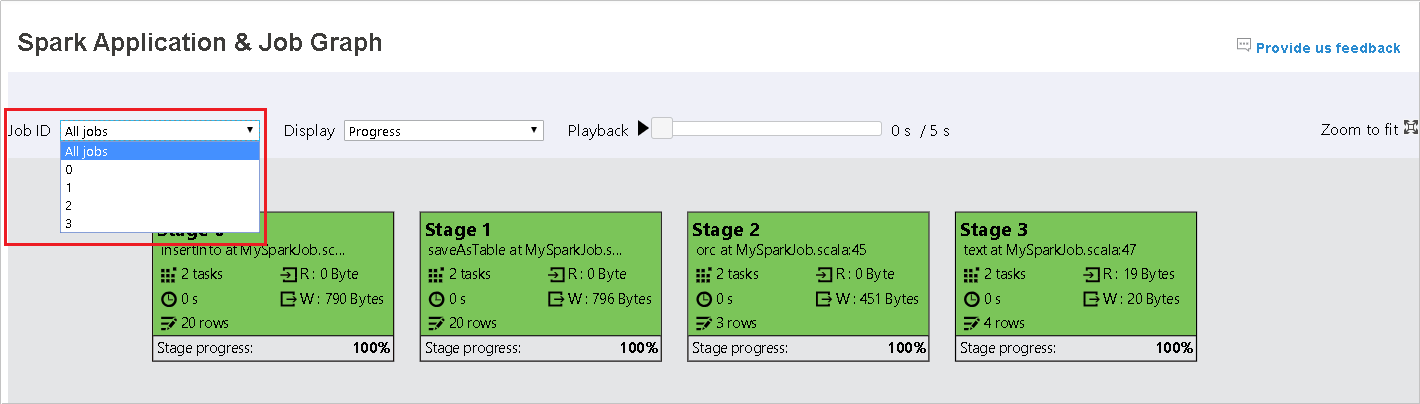
将“进度”保留为默认值。 通过在“显示”下拉列表中选择“读取”或“写入”,用户可以检查数据流。
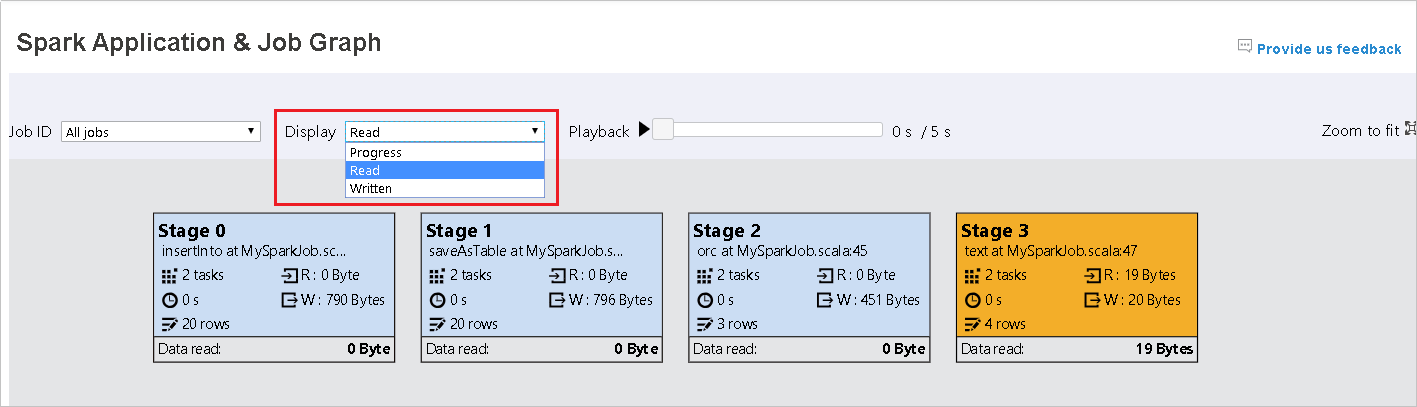
图形节点以显示热度地图的颜色显示。

单击“播放”按钮播放作业,然后单击“停止”按钮随时停止。 任务以彩色显示,以显示播放时的不同状态:
- 绿色表示已成功:作业已成功完成。
- 橙色表示重试:失败但不影响作业最终结果的任务实例。 这些任务包括可能稍后会成功的重复或重试实例。
- 蓝色表示正在运行:任务正在运行。
- 白色表示等待或跳过:任务正在等待运行或已跳过该阶段。
- 红色表示失败:任务失败。

跳过的阶段以白色显示。


注意
每个作业都可以播放。 未完成的作业不可以播放。
滚动鼠标可放大/缩小作业图,或单击“缩放到适合大小”以使其适合屏幕大小。
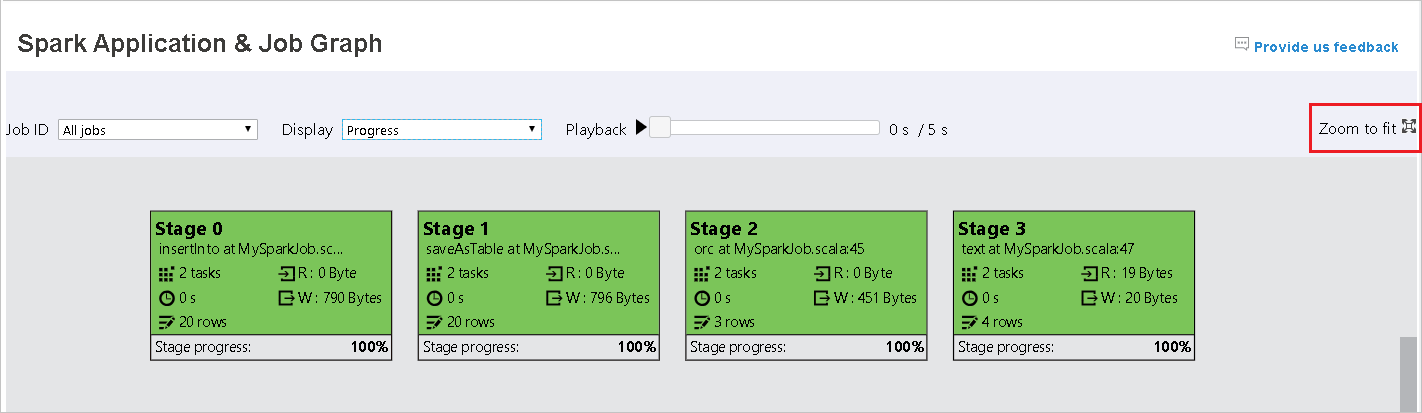
将鼠标悬停在图形节点上以查看任务失败时的工具提示,然后单击“阶段”以打开“阶段”页。
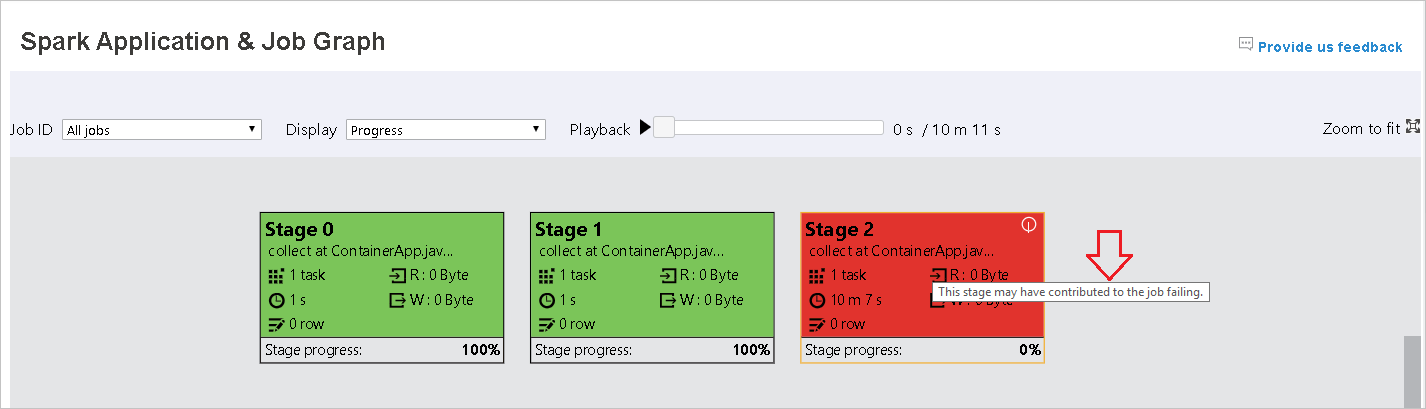
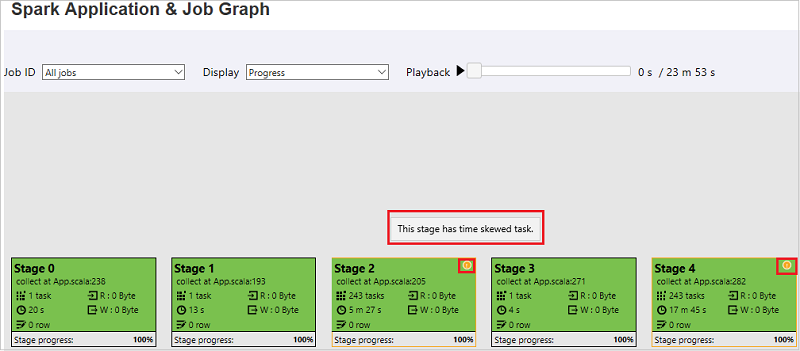
在“作业图”选项卡中,如果任务满足以下条件,则会显示工具提示和小图标:
- 数据倾斜:数据读取大小 > 此阶段内所有任务的平均数据读取大小 * 2 并且数据读取大小 > 10 MB
- 时间偏差:执行时间 > 此阶段内所有任务的平均执行时间 * 2 并且执行时间 > 2 分钟
作业图节点将显示每个阶段的以下信息:
- ID。
- 名称或说明。
- 总任务数。
- 数据读取:输入大小和随机读取大小的总和。
- 数据写入:输出大小和随机写入大小的总和。
- 执行时间:从第一次尝试的开始时间到最后一次尝试的完成时间的时间和。
- 行计数:输入记录、输出记录、随机读取记录和随机写入记录的总和。
- 进度。
注意
默认情况下,作业图节点将显示每个阶段最后一次尝试的相关信息(阶段执行时间除外),但在播放过程中,图形节点将显示每次尝试的相关信息。
备注
对于读写的数据大小,我们使用 1MB = 1000 KB = 1000 * 1000 字节。
单击“向我们提供反馈”,发送相关问题的反馈。
Spark History Server 中的“诊断”选项卡
选择作业 ID,然后单击工具菜单上的“诊断”以获取作业诊断视图。 诊断选项卡包括“数据倾斜”、“时间偏差”和“执行程序使用情况分析” 。
分别选择“数据倾斜”、“时间偏差”和“执行程序使用情况分析”,以选中这些选项卡 。
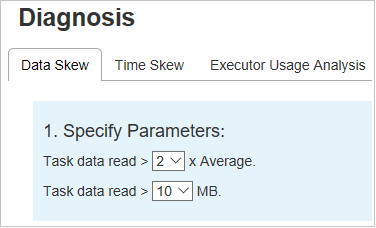
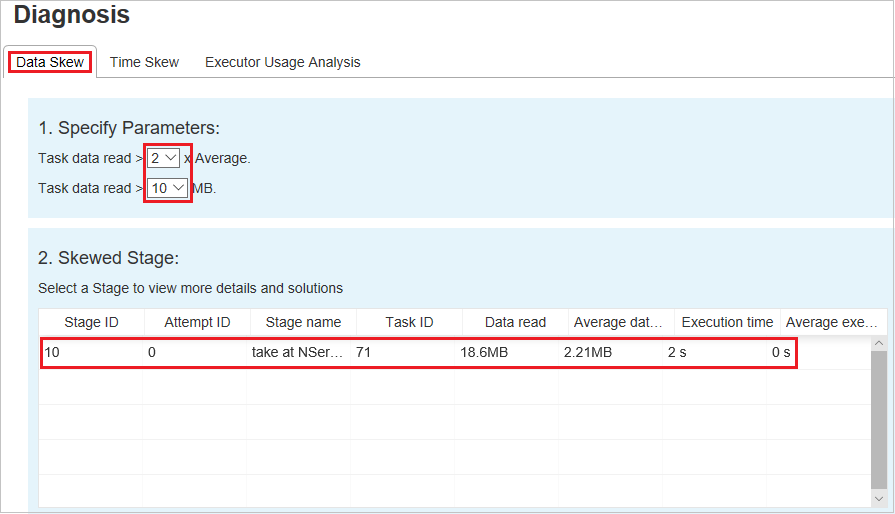
数据倾斜
单击“数据倾斜”选项卡,根据指定的参数显示相应的倾斜任务。
指定参数 - 第一部分显示用于检测数据倾斜的参数。 内置规则是:读取的任务数据比读取的平均任务数据多三倍,读取的任务数据超过 10 MB。 如果要为倾斜的任务定义自己的规则,可以选择自己的参数,“倾斜阶段”和“倾斜字符型”部分将相应刷新 。
倾斜阶段 - 第二部分显示其任务满足上面指定的条件的阶段。 如果一个阶段中存在多个倾斜任务,则倾斜阶段表仅显示倾斜程度最高的任务(例如,数据倾斜的最大数据)。
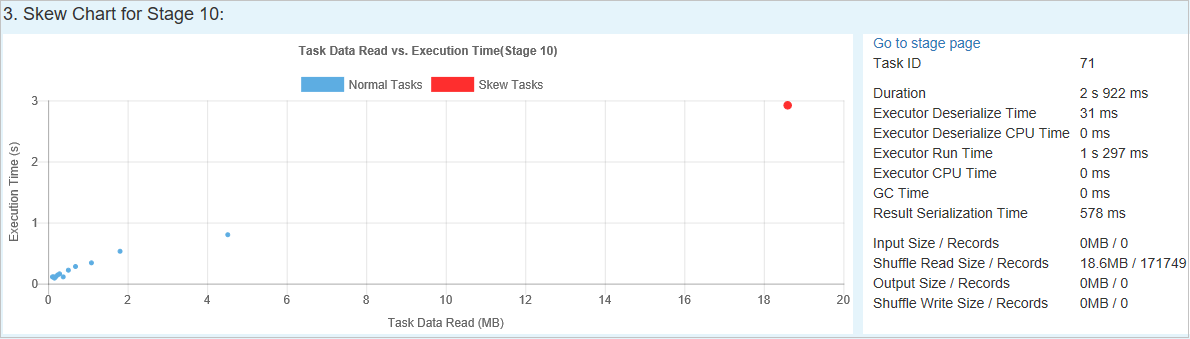
倾斜图表 - 选中倾斜阶段表中的行时,倾斜图表会根据数据读取和执行时间显示更多任务分布详细信息。 倾斜任务标记为红色,普通任务标记为蓝色。 出于性能方面的考虑,图表仅显示最多 100 个示例任务。 任务详细信息显示在右下方的面板中。
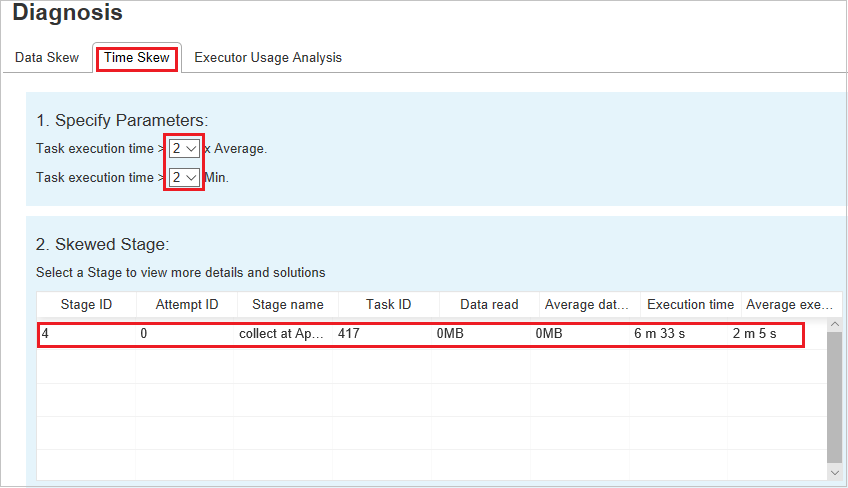
时间倾斜
“时间倾斜”选项卡根据任务执行时间显示倾斜任务。
指定参数 - 第一部分显示用于检测时间倾斜的参数。 用于检测时间倾斜的默认条件是:任务执行时间是平均执行时间的三倍,任务执行时间大于 30 秒。 可以按需更改相关参数。 与上面的“时间倾斜”选项卡一样,倾斜阶段和倾斜图表显示相应的阶段和任务信息 。
单击“时间倾斜”,然后根据“指定参数”部分中设置的参数,在“倾斜阶段”部分中显示筛选结果 。 单击“倾斜阶段”部分中的某项,然后在第 3 部分中绘制相应的图表,任务详细信息随即显示在右下方面板中。
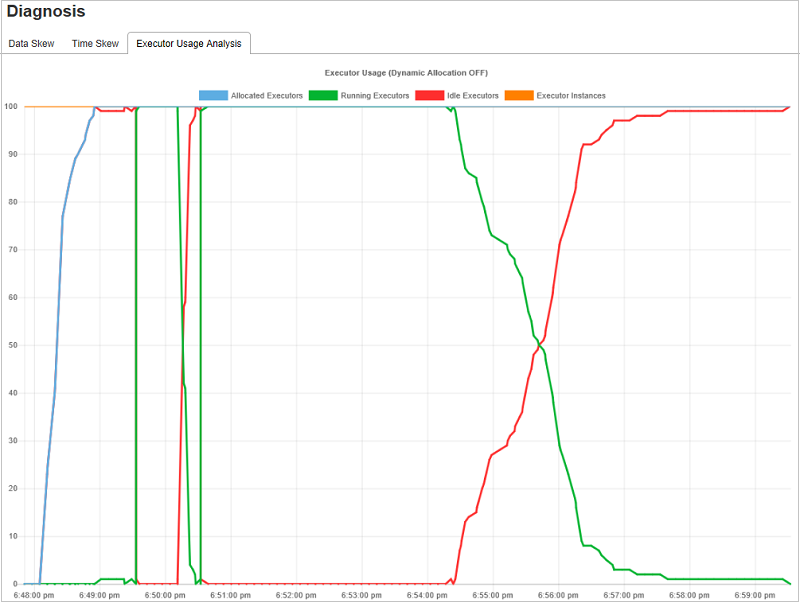
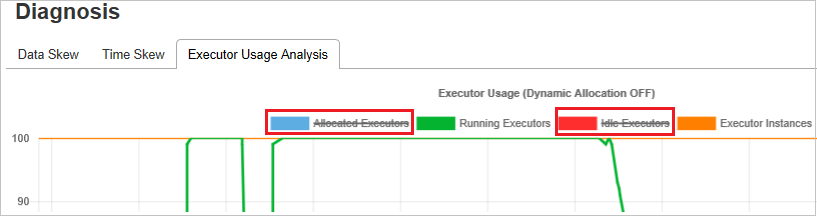
执行程序使用情况分析
执行程序使用情况图可视化 Spark 作业实际执行程序分配和运行状态。
单击“执行程序使用情况分析”,然后采用四种类型的曲线来绘制执行程序使用情况。 它们包括“分配的执行程序”、“正在运行的执行程序”、“空闲执行程序”以及“最大执行程序实例” 。 对于分配的执行程序,每个“已添加执行程序”或“已删除执行程序”事件都将增加或减少分配的执行程序。 可以在“作业”选项卡中选中“事件时间线”以进行更多比较。
单击颜色图标以选中或取消选中所有草稿中的相应内容。
Spark/Yarn 日志
除 Spark History Server 外,还可以在此处分别查找 Spark 和 Yarn 日志:
- Spark 事件日志:hdfs:///system/spark-events
- Yarn 日志:hdfs:///tmp/logs/root/logs-tfile
注意:这两种日志的默认保持期为 7 天。 如果要更改保持期,请参阅配置 Apache Spark 和 Apache Hadoop 页面。 无法更改位置。
已知问题
Spark History Server 具有以下已知问题:
目前它仅适用于 Spark 3.1 群集 (CU13+) 和 Spark 2.4 (CU12-)。
使用 RDD 的输入/输出数据不会显示在“数据”选项卡中。
后续步骤
- SQL Server 大数据群集入门
- 配置 Spark 设置
- 配置 Spark 设置