在高可用性配置中部署 HDFS 名称节点和共享 Spark 服务
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
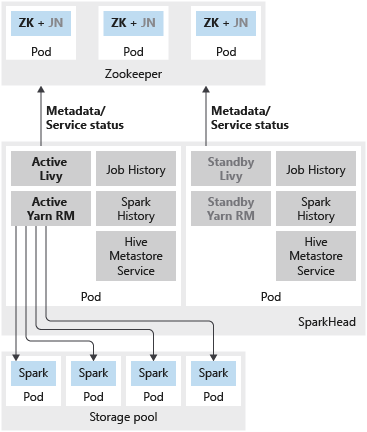
除了使用可用性组在高可用性配置中部署 SQL Server 主实例以外,还可以在大数据群集中部署其他任务关键型服务,以确保提高可靠性。 可以使用附加副本来配置 HDFS name node 和按 sparkhead 分组的共享 Spark 服务。 在这种情况下,还会在大数据群集中部署 Zookeeper,用作以下服务的群集协调器和元数据存储:
- HDFS 名称节点
- Livy 和 Yarn 资源管理器。
Spark 历史记录、作业历史记录和 Hive 元数据服务是无状态服务。 Zookeeper 不参与确保这些组件的服务运行健康状况。
为这些服务部署多个副本可提高可用副本间工作负载的可伸缩性、可靠性和负载均衡。
注意
下列服务以容器形式部署在 sparkhead pod 中:
- Livy
- Yarn 资源管理器
- Spark 历史记录
- 作业历史记录
- Hive 元数据服务
下图展示了 SQL Server 大数据群集中的 spark HA 部署:
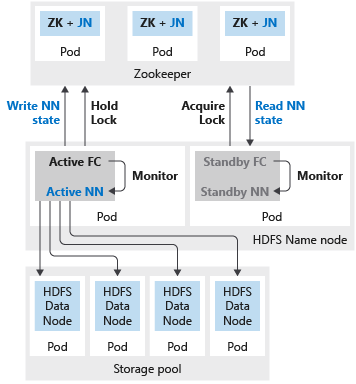
下图展示了 SQL Server 大数据群集中的 HDFS HA 部署:
部署
如果名称节点或 spark 头配置了两个副本,则还必须配置具有三个副本的 Zookeeper 资源。 在 HDFS 名称节点的高可用性配置中,两个 pod 托管两个副本。 这两个 pod 分别为 nmnode-0 和 nmnode-1。 此配置为主动-被动。 一次只有一个名称节点处于活动状态。 另一个节点处于备用状态 - 在发生故障转移事件变为活动状态。
可以使用 aks-dev-test-ha 或 kubeadm-prod 内置配置文件来开始自定义大数据群集部署。 这些配置文件包括配置其他高可用性资源所需的设置。 例如,下面是 bdc.json 配置文件中的一部分,适用于部署具有高可用性的 HDFS 名称节点、Zookeeper 和共享 Spark 资源 (sparkhead)。
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
最佳做法是,在生产部署中,必须将 HDFS 块复制配置为 3。 此设置已在 aks-dev-test-ha 和 kubeadm-prod 配置文件中指定。 请参阅以下 bdc.json 配置文件中的部分:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
已知限制
为 SQL Server 大数据群集中的 Hadoop 服务配置高可用性的已知问题和限制包括:
- 在部署大数据群集时必须指定所有配置。 使用 SQL Server 2019 CU1 版本,无法在部署后启用高可用性配置。
后续步骤
- 有关在大数据群集部署中使用配置文件的详细信息,请参阅如何在 Kubernetes 上部署 SQL Server 大数据群集。
- 有关大数据群集中 SQL Server 主高可用性选项的详细信息,请参阅部署具有高可用性的 SQL Server 主实例主题。