SQL Server 大数据群集 中的存储池简介
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
本文介绍 SQL Server 大数据群集中 SQL Server 存储池的作用。 以下部分介绍存储池的体系结构和功能。
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
存储池体系结构
存储池是 SQL Server 大数据群集中的本地 HDFS (Hadoop) 群集。 它为非结构化的和半结构化的数据提供永久性存储。 数据文件(如 Parquet 或带分隔符的文本)可以存储在存储池中。 为了实现永久性存储,池中的每个 Pod 都连接了一个永久性卷。 可通过以下方式访问存储池文件:通过 SQL Server 借助 PolyBase 访问或直接使用 Apache Knox 网关访问。
经典 HDFS 安装程序由一组附加了存储的商用硬件计算机组成。 为了实现容错和利用并行处理,数据以块的形式分散在各个节点上。 群集中的一个节点充当名称节点,并包含该数据节点中各文件的元数据信息。
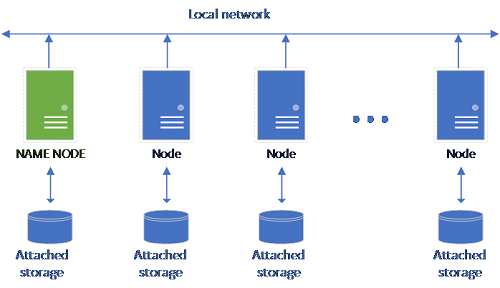
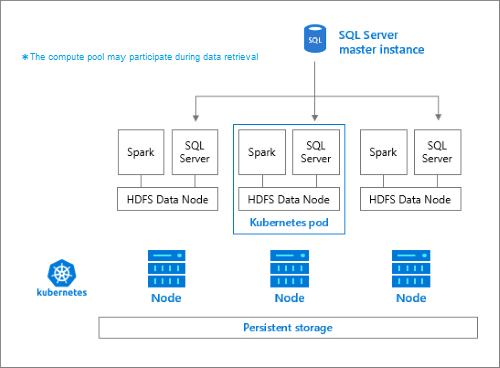
存储池由作为 HDFS 群集成员的存储节点组成。 它运行一个或多个 Kubernetes pod,每个 pod 托管以下容器:
- 链接到永久性卷(存储)的 Hadoop 容器。 所有此类型的容器一起构成了 Hadoop 群集。 Hadoop 容器中的 YARN 节点管理器进程可创建按需 Apache Spark 工作进程。 Spark 头节点托管 Hive元存储、Spark 历史记录和 YARN 作业历史记录容器。
- 使用 OpenRowSet 技术从 HDFS 读取数据的 SQL Server 实例。
- 用于收集指标数据的
collectd。 - 用于收集日志数据的
fluentbit。
职责
存储节点负责:
- 通过 Apache Spark 进行数据引入。
- HDFS 中的数据存储(Parquet 和带分隔符的文本格式)。 HDFS 还提供数据持久性,因为 HDFS 数据分散到 SQL BDC 中的所有存储节点上。
- 通过 HDFS 和 SQL Server 终结点进行数据访问。
访问数据
访问存储池中的数据的主要方法包括:
- Spark 作业。
- 利用 SQL Server 外部表,从而允许使用 PolyBase 计算节点和在 HDFS 节点中运行的 SQL Server 实例来查询数据。
你也可以使用以下各项与 HDFS 交互:
- Azure Data Studio。
- Azure Data CLI (
azdata)。 - kubectl,用于向 Hadoop 容器发出命令。
- HDFS http 网关。
后续步骤
若要了解有关 SQL Server 大数据群集 的详细信息,请参阅以下资源: