通过 SQL Server 大数据群集部署的资源
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
本文介绍了 SQL Server 大数据集部署的资源。
大数据群集根据部署配置文件来部署 Pod。 有关详细信息,请参阅默认配置。
本文介绍了使用 aks-dev-test-ha 配置文件部署的 Pod,并包括 Spark 池。 查询 Kubernetes,以查看群集中部署的 Pod。 下面的示例返回特定命名空间下的 Pod 列表。
kubectl get pods -n <namespace>
将 <namespace> 替换为大数据群集的名称。
有关详细信息,请参阅如何在 Kubernetes 上部署 SQL Server 大数据群集。
下图显示了大数据集中部署的组件:
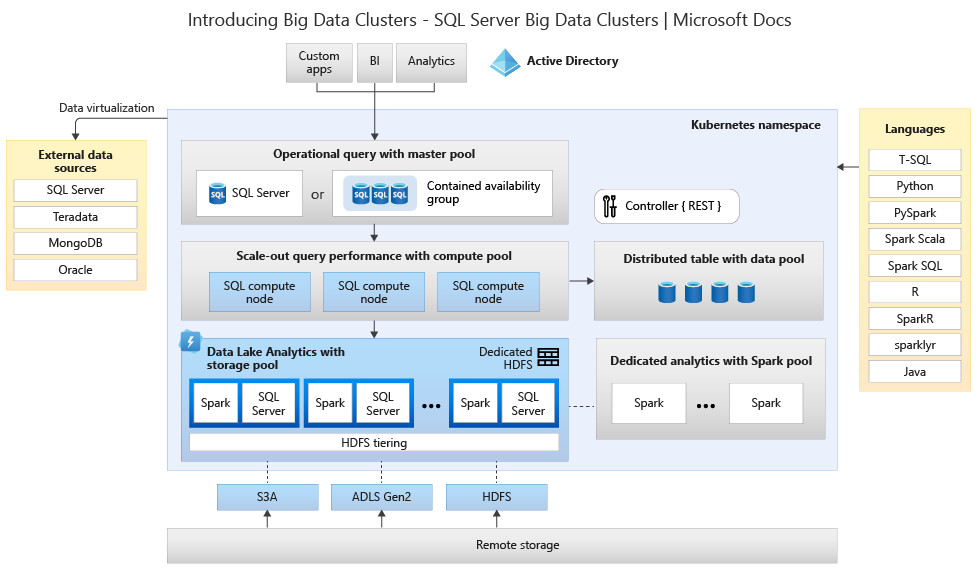
若要了解体系结构,请参阅 SQL Server 大数据群集简介。
已部署的 Pod
下表列出了部署在大数据群集中的 Pod。
| 名称 | 区域 |
|---|---|
control-<nnnn> |
控制 |
controldb-<#> |
控制 |
controlwd-<nnnn> |
控制 |
logsdb-<#> |
控制 |
logsui-<nnnn> |
控制 |
metricsdb-<#> |
控制 |
metricsdc-<nnnn> |
控制 |
metricsui-<nnnn> |
控制 |
mgmtproxy-<nnnn> |
控制 |
zookeeper-<#> |
控制 |
dns-<nnnn> |
控制 |
master-<#n> |
主实例 |
operator-<nnnn> |
主实例 |
compute-<#n>-<#m> |
计算池 |
data-<#>-<#> |
数据池 |
storage-<#>-<#> |
存储池 |
nmnode-<#>-<#> |
存储池 |
sparkhead-<#> |
存储池 |
appproxy-<#m> |
应用程序池 |
gateway-<#> |
网关服务 |
并非每个大数据群集中都包含所有 Pod。 具有高可用性的部署或 Active Directory 集成包含特定的 Pod。
高可用性特定的 Pod:
operator-<nnnn>zookeeper-<#>
Active Directory 特定的 Pod:
dns-<nnnn>
以下部分介绍了 Pod,并列出每个 Pod 中的容器。
控制
控制 Pod 提供控制服务。
| Pod 名称 | Count | Kubernetes 控制器类型 | 容器 |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
每个 Kubernetes 节点 1 个。 | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
Active Directory 集成 0 或 1 个 | ReplicaSet | - dns- fluentbit |
主实例
master-<#n> 是 SQL Server 主实例。
- 通过 DDL 管理数据池
- 通过 DML 操作数据池中的数据
- 将分析查询执行卸载到数据池
| Pod 名称 | Count | Kubernetes 控制器类型 | 容器 |
|---|---|---|---|
master-<#n> |
高可用性 1 个或更多。 | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
高可用性 0 或 1 个 | ReplicaSet | - mssql-ha-operator |
* 仅限高可用性部署。 运算符实现并注册 SQL Server 和可用性组资源的自定义资源定义。 部署运算符时,它将自身注册为侦听器,以接收有关在 Kubernetes 群集中部署 SQL Server 资源的通知。 mssql-ha-supervisor 支持可用性组。
每个 master Pod 都包含一个 SQL Server 实例。 一个高可用性部署包括 3 个 Pod。 每个 Pod 包含一个 SQL Server 实例,其中包含 SQL Server Always On 可用性组中的数据库。
根据工作负载,在部署时包括其他 Pod。
计算池
计算池提供用于计算的 SQL Server 实例。
| Pod 名称 | Count | Kubernetes 控制器类型 | 容器 |
|---|---|---|---|
compute-<#n>-<#m> |
1 个或更多。 | StatefulSet | - mssql-server- fluentbit- collectd |
#n标识计算池。#m标识池中的实例 ID。
计算池 SQL Server 实例是无状态的。 它们只需要 tempdb 的存储。
根据工作负载,在部署时包括其他 Pod。
数据池
数据池提供用于存储和计算的 SQL Server 实例。
| Pod 名称 | Count | Kubernetes 控制器类型 | 容器 |
|---|---|---|---|
data-<#n>-<#m> |
0 个或更多 | StatefulSet | - mssql-server - fluentbit- collectd |
#n标识数据池。#m标识池中的实例 ID。
根据工作负载,在部署时包括其他 Pod。
存储池
存储池通过 Spark 提供数据引入、在 HDFS 中存储、通过 HDFS 和 SQL Server 终结点提供数据访问。
| Pod 名称 | Count | Kubernetes 控制器类型 | 容器 |
|---|---|---|---|
storage-0-# |
1 个或更多。 根据工作负载,在部署时包括其他 Pod。 | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
高可用性 1 个或更多 | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
高可用性 1 个或更多 | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
高可用性 0 或 3 个。 | StatefulSet | - zookeeper- fluentbit |
应用程序池
应用程序池包含在一些测试配置文件中。 应用程序池承载应用程序服务代理,这些代理在部署大数据群集的应用程序时定义。
appproxy 是位于应用程序池应用程序前面的 Web API。 它对用户进行身份验证,然后将请求路由到应用程序。
| Pod 名称 | Kubernetes 控制器类型 | 容器 |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
有关详细信息,请参阅大数据群集上的应用程序部署简介。
根据工作负载,在部署时包括其他 Pod。
网关服务
网关服务提供到 Spark、HDFS、Yarn、Yarn UI 和 Spark UI 的 Knox 网关。
| Pod 名称 | Kubernetes 控制器类型 | 容器 |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
仅支持一个网关。
开放源代码容器引用
有关特定开源项目和版本,请参阅开源软件参考。
后续步骤
若要了解有关 SQL Server 大数据群集 的详细信息,请参阅以下资源: