在 Microsoft Purview 中连接到和管理 Azure Databricks
本文概述了如何注册 Azure Databricks,以及如何在 Microsoft Purview 中对 Azure Databricks 进行身份验证和交互。 有关 Microsoft Purview 的详细信息,请阅读 介绍性文章。
支持的功能
| 元数据提取 | 完整扫描 | 增量扫描 | 作用域扫描 | 分类 | 标记 | 访问策略 | 世系沿袭 | 数据共享 | 实时视图 |
|---|---|---|---|---|---|---|---|---|---|
| 是 | 是 | 否 | 是 | 否 | 否 | 否 | 是 | 否 | 否 |
注意
此连接器从 Azure Databricks 工作区范围的 Hive 元存储中引入元数据。 若要扫描 Azure Databricks Unity目录中的元数据,请参阅 Azure Databricks Unity目录连接器。
扫描 Azure Databricks Hive 元存储时,Microsoft Purview 支持:
提取技术元数据,包括:
- Azure Databricks 工作区
- Hive 服务器
- Databases
- 表,包括列、外键、唯一约束和存储说明
- 视图,包括列和存储说明
提取外部表与Azure Data Lake Storage Gen2/Azure Blob 资产之间的关系 (外部位置) 。
基于视图定义在表和视图之间提取静态世系。
设置扫描时,可以选择扫描整个 Hive 元存储,或将扫描范围限定为架构的子集。
比较通过通用 Hive 元存储连接器 进行扫描,以防之前使用它扫描 Azure Databricks:
- 可以直接为 Azure Databricks 工作区设置扫描,而无需直接访问 HMS。 它使用 Databricks 个人访问令牌进行身份验证,并连接到群集以执行扫描。
- 捕获 Databricks 工作区信息。
- 捕获表和存储资产之间的关系。
已知限制
从数据源中删除对象时,当前后续扫描不会自动删除 Microsoft Purview 中的相应资产。
先决条件
必须具有具有活动订阅的 Azure 帐户。 免费创建帐户。
必须具有有效的 Microsoft Purview 帐户。
需要 Azure 密钥保管库,并授予 Microsoft Purview 访问机密的权限。
需要数据源管理员和数据读取者权限才能在 Microsoft Purview 治理门户中注册和管理源。 有关权限的详细信息,请参阅 Microsoft Purview 中的访问控制。
设置最新的 自承载集成运行时。 有关详细信息,请参阅 创建和配置自承载集成运行时。 支持的最低自承载Integration Runtime版本为 5.20.8227.2。
在 Azure Databricks 工作区中:
注册
本部分介绍如何使用 Microsoft Purview 治理门户在 Microsoft Purview 中注册 Azure Databricks 工作区。
转到Microsoft Purview 帐户。
在左窗格中选择“ 数据映射 ”。
选择“注册”。
在 “注册源”中,选择“ Azure Databricks>继续”。
在“ (Azure Databricks) 注册源 ”屏幕上,执行以下作:
对于 “名称”,请输入Microsoft Purview 将列为数据源的名称。
对于 Azure 订阅 和 Databricks 工作区名称,请从下拉列表中选择要扫描的订阅和工作区。 Databricks 工作区 URL 会自动填充。
从列表中选择集合。
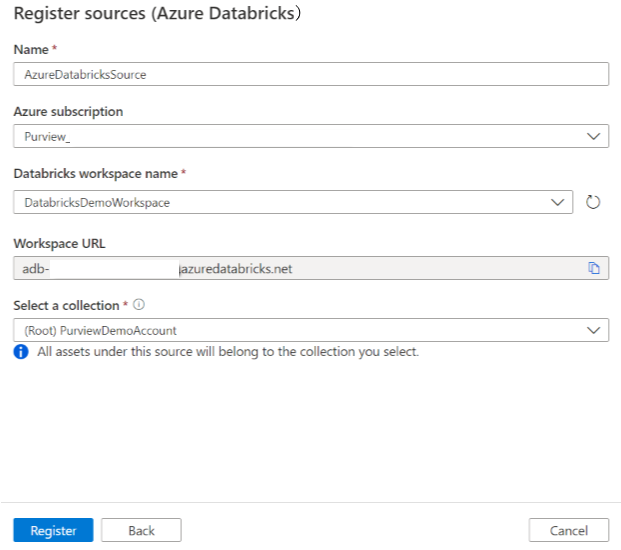
选择“完成”。
扫描
使用以下步骤扫描 Azure Databricks 以自动识别资产。 有关一般扫描的详细信息,请参阅 Microsoft Purview 中的扫描和引入。
在“管理中心”中,选择“集成运行时”。 确保已设置自承载集成运行时。 如果未设置,请使用 创建和管理自承载集成运行时中的步骤。
转到 “源”。
选择已注册的 Azure Databricks。
选择“ + 新建扫描”。
提供以下详细信息:
名称:输入扫描的名称。
提取方法:指示从 Hive 元存储或Unity目录中提取元数据。 选择“ Hive 元存储”。
通过集成运行时进行连接:选择配置的自承载集成运行时。
凭据:选择要连接到数据源的凭据。 请确保:
- 创建凭据时选择“ 访问令牌身份验证 ”。
- 在相应的框中提供在 “先决条件” 中创建的个人访问令牌的机密名称。
有关详细信息,请参阅 Microsoft Purview 中的源身份验证凭据。
群集 ID:指定Microsoft Purview 连接到并启用扫描的群集 ID。 可以在 Azure Databricks 工作区 - 计算 ->> 群集 -> 标记 -> 自动添加的标记 ->
ClusterId中找到它。装入点:将外部存储手动装载到 Databricks 时提供装入点和 Azure 存储源位置字符串。 使用格式
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net。 它用于捕获表与 Microsoft Purview 中相应存储资产之间的关系。 此设置是可选的,如果未指定,则不会检索此类关系。通过在笔记本中运行以下 Python 命令,可以获取 Databricks 工作区中的装入点列表:
dbutils.fs.mounts()它将打印所有装入点,如下所示:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]在此示例中,将以下内容指定为装入点:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.net架构:要导入的架构子集以分号分隔的架构列表表示。 例如,
schema1;schema2。 如果该列表为空,则导入所有用户架构。 默认情况下,将忽略所有系统架构和对象。可接受的架构名称模式可以是静态名称,也可以包含通配符 %。 例如:
A%;%B;%C%;D- 从 A 或 开始
- 以 B 或 结尾
- 包含 C 或
- 等于 D
不能接受使用 NOT 和特殊字符。
注意
自承载Integration Runtime版本 5.32.8597.1 及更高版本支持此架构筛选器。
最大可用内存:客户计算机上可供扫描进程使用的最大内存 () GB。 此值取决于要扫描的 Azure Databricks 的大小。
注意
作为经验法则,请为每 1000 个表提供 1GB 内存。
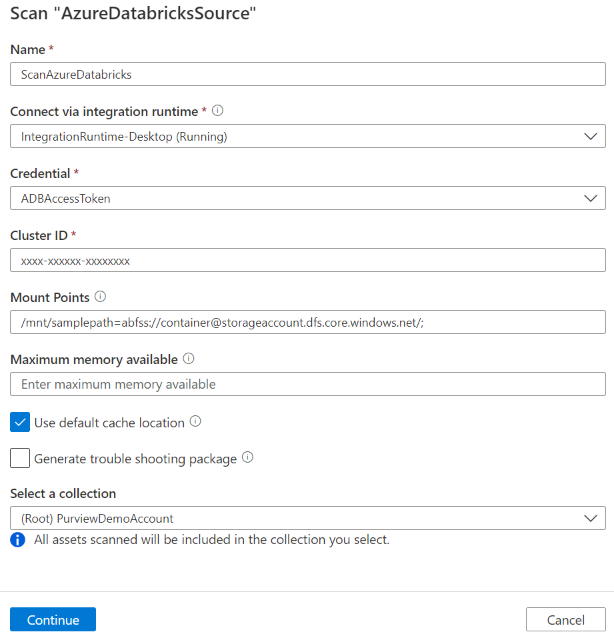
选择 继续。
对于 “扫描触发器”,选择是设置计划还是运行扫描一次。
查看扫描并选择“ 保存并运行”。
扫描成功完成后,请参阅如何 浏览和搜索 Azure Databricks 资产。
查看扫描和扫描运行
查看现有扫描:
- 转到 Microsoft Purview 门户。 在左窗格中,选择“ 数据映射”。
- 选择数据源。 可以在“最近扫描”下查看该数据源上的现有 扫描列表,也可以在“扫描”选项卡上查看所有 扫描 。
- 选择要查看的结果的扫描。 窗格显示之前的所有扫描运行,以及每个扫描运行的状态和指标。
- 选择运行 ID 以检查扫描运行详细信息。
管理扫描
若要编辑、取消或删除扫描,请执行以下作:
转到 Microsoft Purview 门户。 在左窗格中,选择“ 数据映射”。
选择数据源。 可以在“最近扫描”下查看该数据源上的现有 扫描列表,也可以在“扫描”选项卡上查看所有 扫描 。
选择要管理的扫描。 然后,可以:
- 通过选择“编辑扫描 ”来编辑扫描。
- 选择“取消扫描运行”, 取消正在进行的扫描。
- 通过选择“删除扫描” 来删除扫描。
注意
- 删除扫描不会删除从以前的扫描创建的目录资产。
浏览和搜索资产
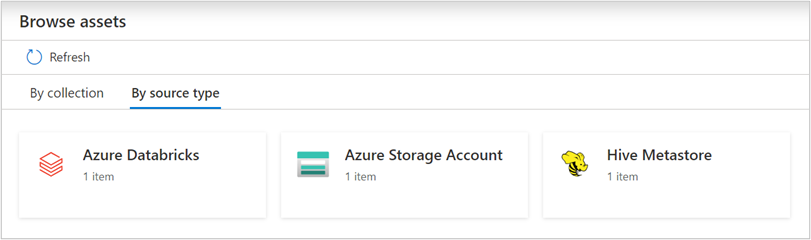
扫描 Azure Databricks 后,可以浏览统一目录或搜索统一目录以查看资产详细信息。
在 Databricks 工作区资产中,可以找到关联的 Hive 元存储和表/视图,反向应用也是如此。
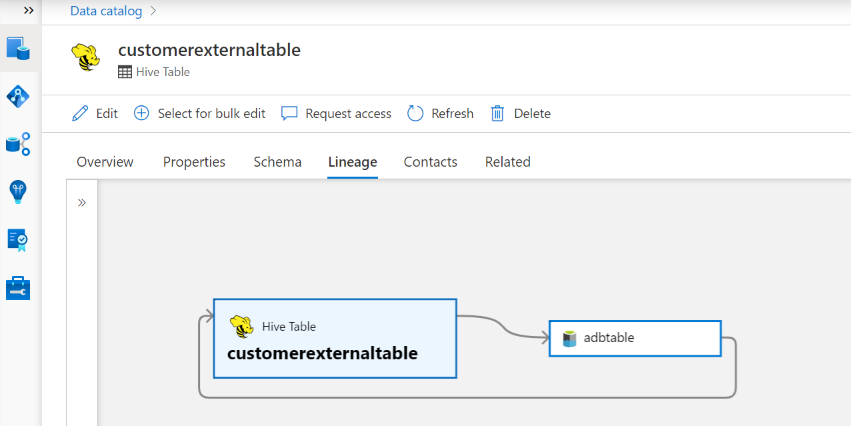
世系沿袭
有关支持的 Azure Databricks 方案,请参阅支持 的功能 部分。 有关世系的一般信息,请参阅 数据世系 和 世系用户指南。
转到 Hive 表/视图资产 -> 世系选项卡,可以看到资产关系(如果适用)。 对于表和外部存储资产之间的关系,可以看到 Hive 表资产和存储资产直接双向连接,因为它们相互影响。 如果在 create table 语句中使用装入点,则需要在 扫描设置 中提供装入点信息来提取此类关系。
后续步骤
注册源后,请使用以下指南详细了解Microsoft Purview 和数据: