Microsoft Purview 数据映射中的分类最佳做法
Microsoft Purview 数据映射中的数据分类是通过向数据资产分配唯一的逻辑标签或类来对数据资产进行分类的一种方式。 分类基于数据的业务上下文。 例如,可以按 护照号码、 驾照编号、 信用卡号、 SWIFT 代码、 人员姓名等对资产进行分类。 若要详细了解分类本身,请参阅 分类一文。
本文介绍在对数据资产进行分类时要采用的最佳做法,以便扫描更加有效,并尽可能获得有关整个数据资产的最完整信息。
扫描规则集
通过使用 扫描规则集,可以配置应应用于数据源的特定扫描的相关分类。 选择相关的系统分类,或者选择自定义分类(如果已为要扫描的数据创建一个分类)。
例如,在下图中,仅对要扫描的数据源应用特定的选定系统和自定义分类, (例如财务数据) 。

批注管理
在决定应用哪些分类时,我们建议你:
转到 “数据映射>注释管理>分类 ”窗格。
查看要应用于要扫描的数据资产的可用系统分类。 系统分类的正式名称具有 MICROSOFT 前缀。
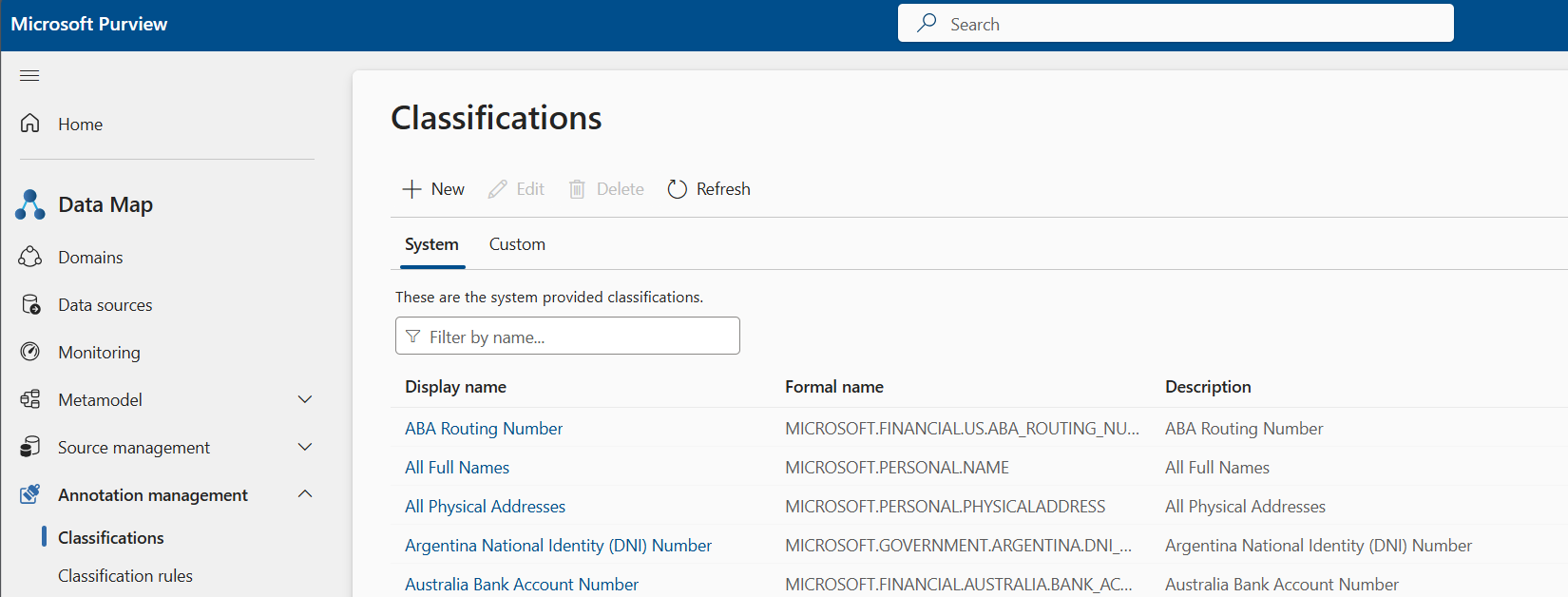
根据需要创建自定义分类。 选择“ 自定义 ”选项卡,然后选择“ + 新建”。 有关创建自定义分类的详细信息, 请参阅自定义分类一文。
为在上一步中创建的自定义分类创建分类规则。 转到 “数据映射>注释管理>分类规则”。 在这里,可以为在上一步中创建的自定义分类名称创建分类规则。
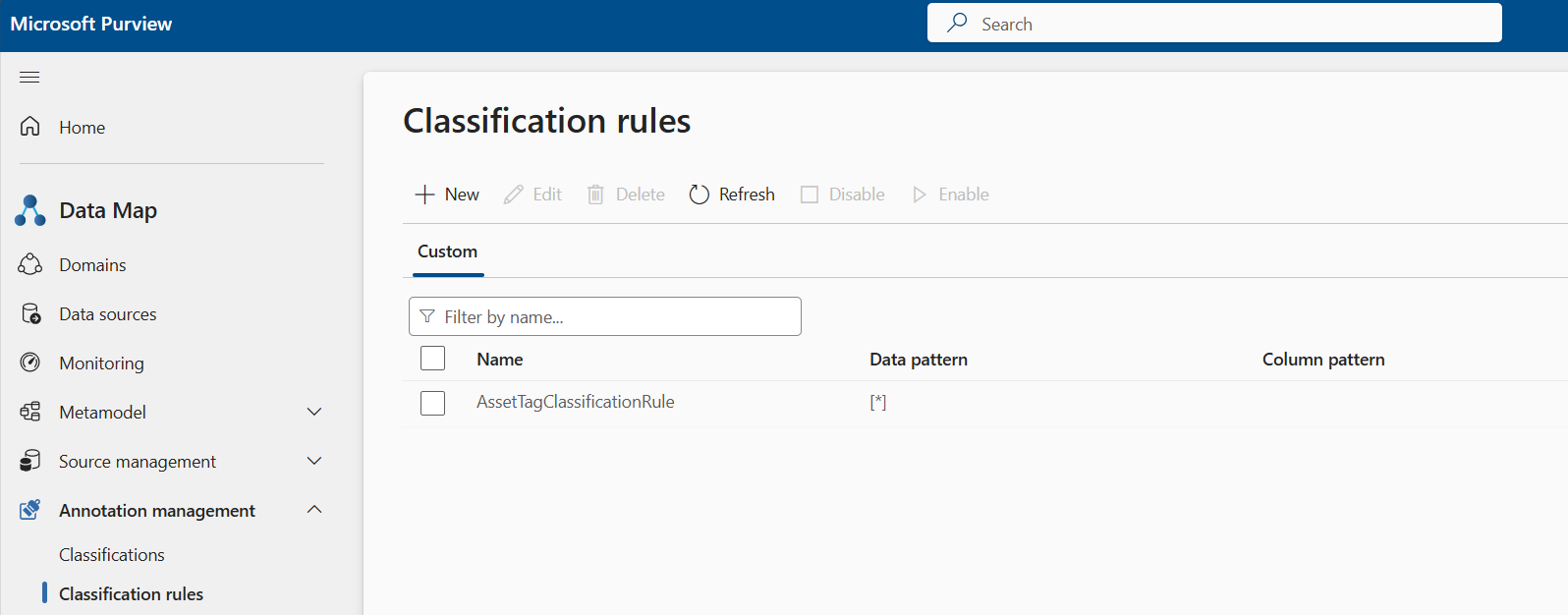


自定义分类
仅当可用的系统分类不满足你的需求时,才创建自定义分类。
对于自定义分类 的名称 ,最好使用命名空间约定 (例如 <公司名称>。<业务部门>。<自定义分类名称>) 。
例如,对于虚构公司 Contoso 的自定义EMPLOYEE_ID分类,自定义分类的名称将 CONTOSO.HR。EMPLOYEE_ID,友好名称以 HR 的形式存储在系统中。员工 ID。

创建并配置自定义分类的分类规则时,请执行以下操作:
选择要为其创建分类规则的相应分类名称。
Microsoft Purview 数据映射支持以下两种创建自定义分类规则的方法:
如果可以通过 使用正则表达式模式 来持续表达数据元素,或者可以使用数据文件生成模式,请使用正则表达式 (正则表达式) 方法。 确保示例数据反映总体。
仅当字典文件中的值列表表示要分类的所有可能的数据值,并且应符合给定的数据集 (考虑未来值以及) 时,才使用 Dictionary 方法。
使用 正则表达式 方法:
为要分类的数据配置正则表达式模式。 确保正则表达式模式足够通用,足以满足分类数据的需求。
Microsoft Purview 还提供了生成建议的正则表达式模式的功能。 上传示例数据文件后,选择其中一种建议的模式,然后选择“ 添加到模式 ”以使用建议的数据和列模式。 可以修改建议的模式,也可以键入自己的模式,而无需上传文件。
还可以配置列名称模式,以便对列进行分类,以尽量减少误报。
配置与数据模式匹配的数据可接受的 最小匹配阈值 参数,以应用分类。 阈值可以为 1% 到 100%。 建议将值至少设置为 60% 作为阈值,以避免误报。 但是,可以根据需要针对特定分类方案进行配置。 例如,如果要检测数据中的任何值并应用分类(如果该值与模式匹配),则阈值可能低至 1%。
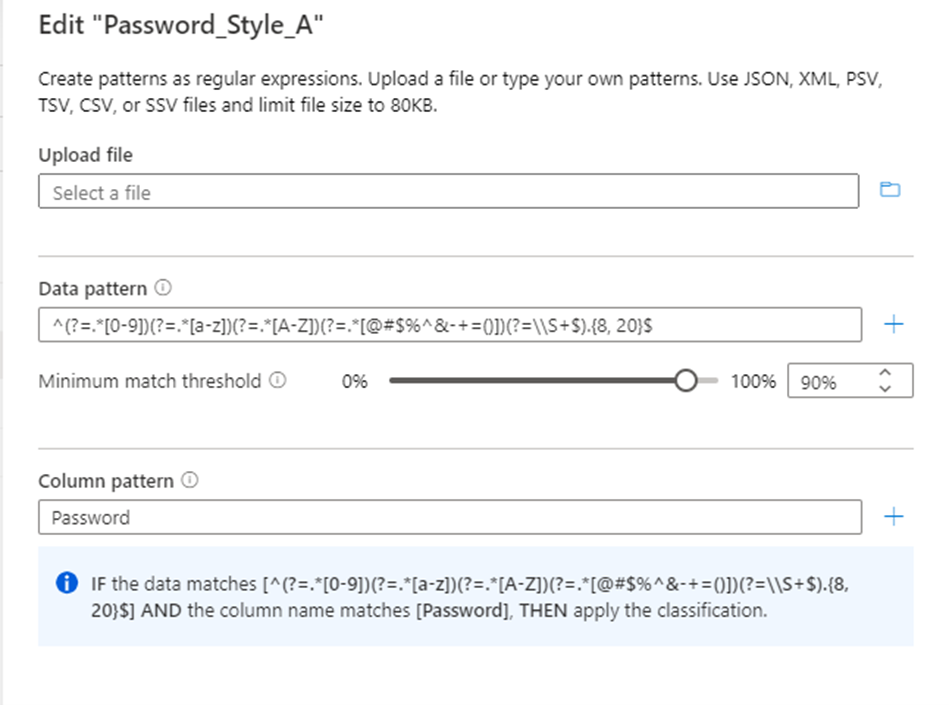
如果向分类规则添加了多个数据模式,则自动禁用用于设置最小匹配规则的选项。
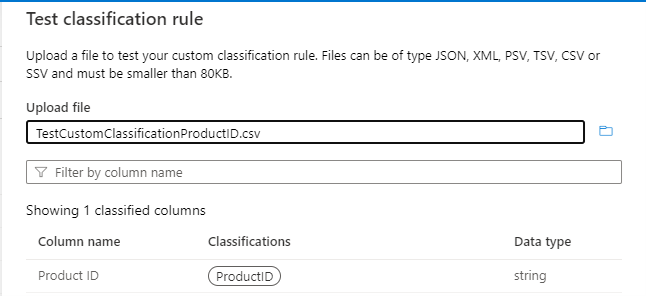
使用 测试分类规则 并结合示例数据进行测试,验证分类规则是否按预期工作。 例如,确保在示例数据 (中,在 .csv 文件中) 至少存在三列,包括要对其应用分类的列。 如果测试成功,则应在列上看到分类标签,如下图所示:
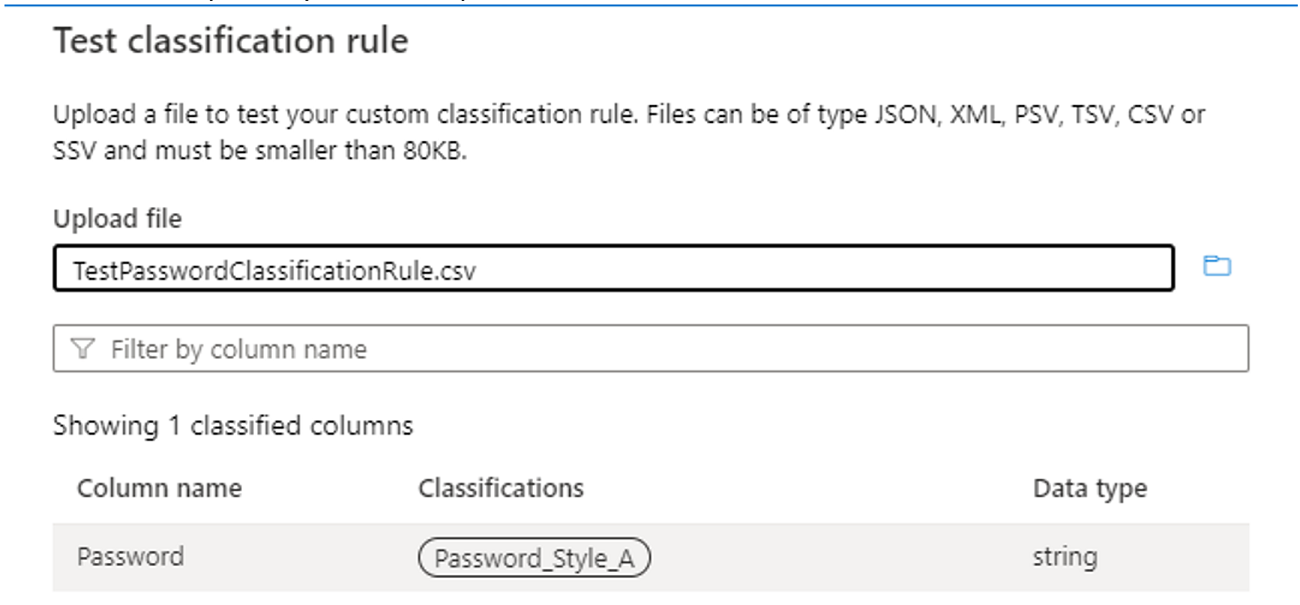
使用 Dictionary 方法:
可以使用 Dictionary 方法来拟合枚举数据,或者如果可用值的字典列表。
此方法支持 .csv 和 .tsv 文件,文件大小限制为 30 MB (MB) 。



自定义分类原型
“threshold”参数在正则表达式中的工作原理
请考虑下图中的示例源数据。 有五列,自定义分类规则应应用于数据模式 N{Digit}{Digit}{Digit}{Digit}{Digit}ANSample_col1、Sample_col2和Sample_col3列。
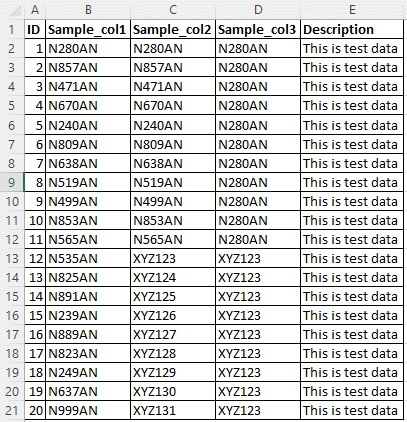
自定义分类名为 NDDDAN。
数据模式) 的分类规则 (正则表达式为 ^N[0-9]{3}AN$。
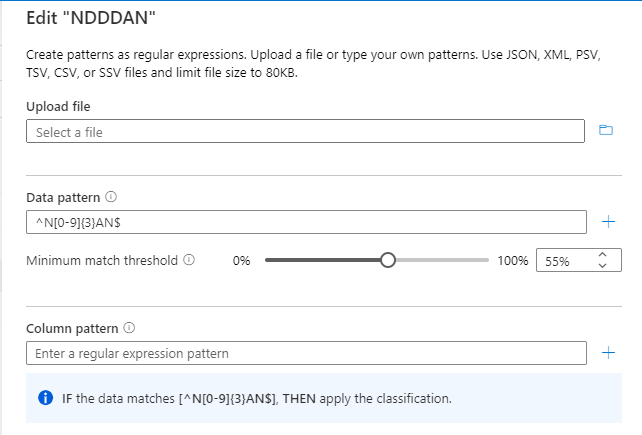
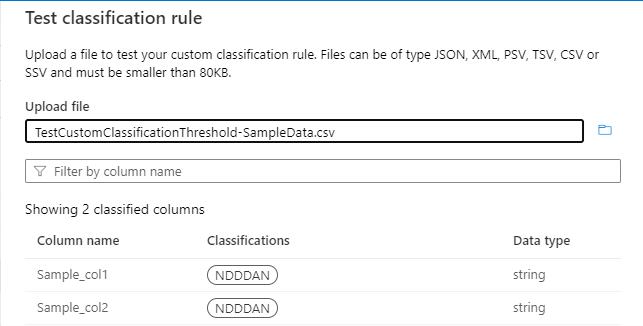
将为“^N[0-9]{3}AN$”模式计算阈值,如下图所示:

如果阈值为 55%,则仅对 Sample_col1 列和 Sample_col2 列进行分类。 Sample_col3 不会分类,因为它不符合 55% 的阈值标准。




如何使用数据和列模式
对于给定的示例数据,其中 B 列和列 C 都有类似的数据模式,可以根据数据模式“^P[0-9]{3}[A-Z]{2}$”对列 B 进行分类。
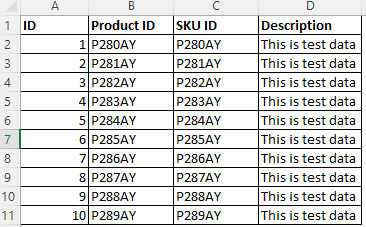
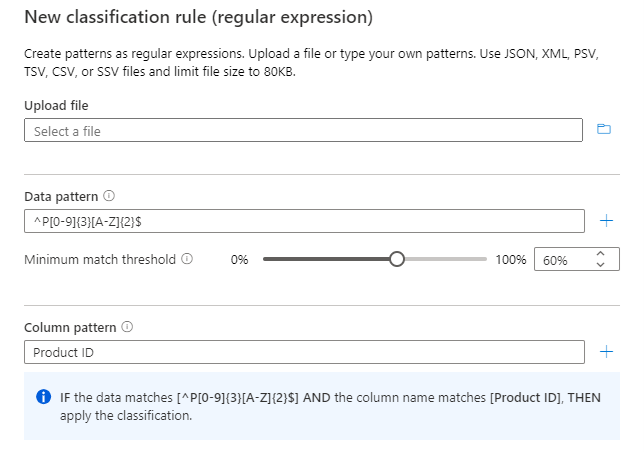
使用列模式和数据模式,确保仅 对“产品 ID ”列进行分类。
注意
列模式被验证为具有数据模式的 AND 条件。
使用 测试分类规则 并结合示例数据进行测试,验证分类规则是否按预期工作。



如何使用多个列模式
如果要为同一分类规则分类多个列模式,请使用管道 (|) 字符分隔的列名。 例如,对于 “产品 ID”、“ Product_ID”、“ ProductID”等列,请写入列模式,如下图所示:

有关详细信息,请参阅 正则表达式交替构造。
分类注意事项
下面是定义分类时要注意的一些注意事项:
若要确定在扫描之前需要对资产应用哪些分类,请考虑如何使用分类。 不必要的分类标签可能会对数据使用者造成干扰,甚至具有误导性。 可以使用分类来:
- 描述正在扫描的数据资产或架构中存在的数据的性质。 换句话说,分类应使客户能够在搜索目录时从分类标签中识别数据资产或架构的内容。
- 设置优先级并制定计划,以实现组织的安全性和合规性需求。
- 描述数据准备过程中的阶段 (原始区域、登陆区域等) 并将分类分配给特定资产以标记过程中的阶段。
通过在扫描规则中包含相关分类,可以在资产或列级别自动分配分类,也可以在将元数据引入Microsoft Purview 数据映射后手动分配分类。
有关自动分配,请参阅Microsoft Purview 数据映射支持的数据存储。
在扫描Microsoft Purview 数据映射中的数据源之前,请务必了解数据并为其配置适当的扫描规则集, (例如,选择相关的系统分类、自定义分类或两种) 的组合,因为这可能会影响扫描性能。 有关详细信息,请参阅Microsoft Purview 数据映射中支持的分类。
Microsoft Purview 扫描程序对深度扫描应用数据采样规则, (系统分类和自定义分类都受分类) 约束。 采样规则基于数据源的类型。 有关详细信息,请参阅 Microsoft Purview 中支持的数据源和文件类型中的“文件中的采样”部分。
注意
非重复数据阈值:这是扫描程序对其运行数据模式之前需要在列中找到的非重复数据值的总数。 非重复数据阈值与模式匹配无关,但它是模式匹配的先决条件。 系统分类规则要求每列中至少有 8 个不同的值,以便对其进行分类。 系统需要此值,以确保列包含足够的数据,以便扫描程序准确分类。 例如,包含多个行的列(全部包含值 1)不会被分类。 包含一行且其余行具有 null 值的列也不会进行分类。 如果指定多个模式,此值将应用于其中每个模式。
采样规则也适用于资源集。 有关详细信息,请参阅Microsoft Purview 数据映射中支持的数据源和文件类型中的“资源集文件采样”部分。
无法使用自定义分类规则对文档类型资产应用自定义分类。 只能手动应用此类类型的分类。
自定义分类不包含在任何默认扫描规则中。 因此,如果需要自动分配自定义分类,则必须部署并使用包含自定义分类的自定义扫描规则来运行扫描。
如果从 Microsoft Purview 治理门户手动应用分类,此类分类将保留在后续扫描中。
后续扫描不会从资产中删除任何分类(如果以前检测到这些分类),即使分类规则不适用。
对于 加密的源 数据资产,Microsoft Purview 仅选取文件名、完全限定的名称、结构化文件类型和数据库表的架构详细信息。 若要使分类正常工作,请在运行扫描之前解密加密的数据。