Xamarin.iOS 中的语音识别
本文介绍新的语音 API,并演示如何在 Xamarin.iOS 应用中实现它,以支持连续语音识别和将语音(从实时或录制的音频流)听录为文本。
作为 iOS 10 的新增功能,Apple 发布了语音识别 API,它让 iOS 应用可以支持连续语音识别和将语音(从实时或录制的音频流)听录为文本。
根据 Apple,语音识别 API 具有以下功能和优势:
- 高度准确
- 最先进
- 易用
- 快速
- 支持多种语言
- 尊重用户隐私
语音识别的工作原理
语音识别是在 iOS 应用中实现的,方法是获取实时或预先录制的音频(采用 API 支持的任何口述语言),并将其传递给语音识别器,由其返回口语的纯文本听录。

键盘听写
提到 iOS 设备上的语音识别,大多数用户会想到内置的 Siri 语音助手,它在 iOS 5 和 iPhone 4S 中与键盘听写一同发布。
支持 TextKit(如 UITextField 或 UITextArea)的任何接口元素都支持键盘听写,它由用户在 iOS 虚拟键盘中单击“听写按钮”(就在空格键左侧)来激活。
Apple 发布了以下键盘听写统计信息(自 2011 年起收集):
- 键盘听写自从在 iOS 5 中发布以来已广泛应用。
- 每天大约有 65,000 个应用使用它。
- 大约三分之一的 iOS 听写是在第三方应用中完成的。
键盘听写非常易于使用,因为除了在应用的 UI 设计中使用 TextKit 接口元素外,它不需要开发人员做任何工作。 键盘听写还具有不需要从应用请求任何特殊特权即可使用的优势。
使用新的语音识别 API 的应用需要用户授予特殊权限,因为语音识别要求在 Apple 的服务器上传输和临时存储数据。 有关详细信息,请参阅我们的安全和隐私增强功能文档。
虽然键盘听写很容易实现,但它确实存在一些限制和缺点:
- 它需要使用文本输入字段和键盘的显示。
- 它仅适用于实时音频输入,并且应用无法控制音频录制过程。
- 它无法控制用于解释用户语音的语言。
- 应用无法知道听写按钮是否对用户可用。
- 应用无法自定义音频录制过程。
- 它提供了一组非常浅显的结果,缺少诸如时间和置信度等信息。
语音识别 API
作为 iOS 10 的新增功能,Apple 发布了语音识别 API,它为 iOS 应用实现语音识别提供了更强大的方法。 此 API 与 Apple 用来为 Siri 和键盘听写提供支持的 API 相同,它能够提供快速听录,具有最先进的准确性。
语音识别 API 提供的结果以透明的方式为各个用户自定义,无需应用收集或访问任何用户私密数据。
语音识别 API 能够在用户说话的同时几乎实时地将结果返回给调用应用,它还能提供有关翻译结果的详细信息,而不仅仅是文本。 这些设置包括:
- 对用户所说的内容进行多种解释。
- 各个翻译的置信度。
- 时间信息。
如上所述,音频可由实时源或预先录制的源提供以进行翻译,可使用 iOS 10 支持的 50 多种语言和方言。
语音识别 API 可在运行 iOS 10 的任何 iOS 设备上使用,在大多数情况下,需要实时 Internet 连接,因为大部分翻译发生在 Apple 的服务器上。 不过,某些较新的 iOS 设备支持对特定语言进行始终可用、设备上的翻译。
Apple 加入了一个可用性 API,用于确定给定语言目前是否可用于翻译。 应用应使用此 API,而不是直接测试 Internet 连接本身。
如上面的键盘听写部分所述,语音识别要求通过 Internet 在 Apple 的服务器上传输和临时存储数据,因此,应用必须向用户请求执行识别的权限,方法是在其 Info.plist 文件中加入 NSSpeechRecognitionUsageDescription 键并调用 SFSpeechRecognizer.RequestAuthorization 方法。
根据用于语音识别的音频源,可能需要对应用的 Info.plist 文件进行其他更改。 有关详细信息,请参阅我们的安全和隐私增强功能文档。
在应用中采用语音识别
为了采用语音识别,开发人员在 iOS 应用中必须采取四个主要步骤:
- 使用
NSSpeechRecognitionUsageDescription键在应用的Info.plist文件中提供使用说明。 例如,相机应用可包含以下说明:“它让你只需说出‘茄子’一词即可拍摄照片”。 - 通过调用
SFSpeechRecognizer.RequestAuthorization方法来请求授权,在对话框中说明(在上面的NSSpeechRecognitionUsageDescription键中提供)应用为何希望获取用户的语音识别访问权限,并允许他们接受或拒绝。 - 创建语音识别请求:
- 对于磁盘上的预录制音频,请使用
SFSpeechURLRecognitionRequest类。 - 对于实时音频(或内存中的音频),请使用
SFSPeechAudioBufferRecognitionRequest类。
- 对于磁盘上的预录制音频,请使用
- 将语音识别请求传递给语音识别器 (
SFSpeechRecognizer) 以开始识别。 应用可以选择保留返回的SFSpeechRecognitionTask以监视并跟踪识别结果。
下面将详细介绍这些步骤。
提供使用说明
若要在 Info.plist 文件中提供所需的 NSSpeechRecognitionUsageDescription 键,请执行以下操作:
双击
Info.plist文件将其打开以供编辑。切换到“源”视图:
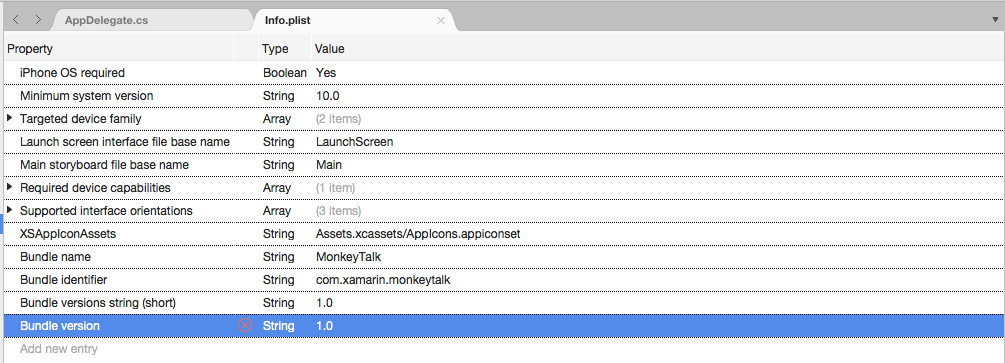
单击“添加新条目”,输入
NSSpeechRecognitionUsageDescription作为“属性”、String作为“类型”,“使用说明”作为“值”。 例如: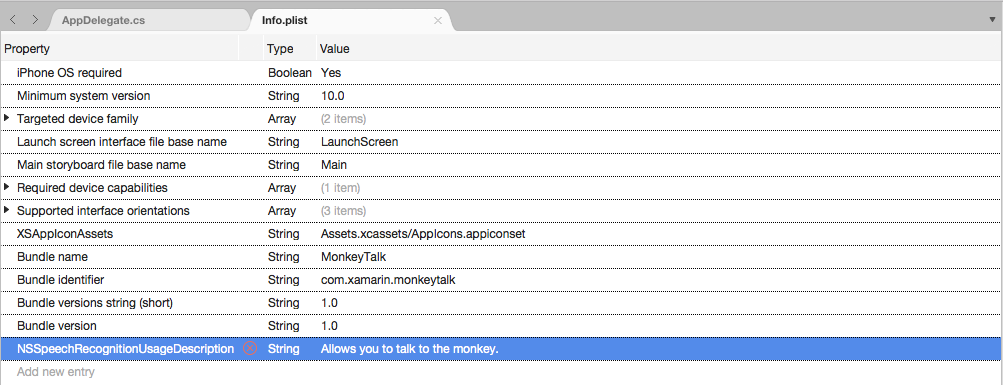
如果应用将处理实时音频听录,则还需要提供麦克风使用说明。 单击“添加新条目”,输入
NSMicrophoneUsageDescription作为“属性”、String作为“类型”,“使用说明”作为“值”。 例如: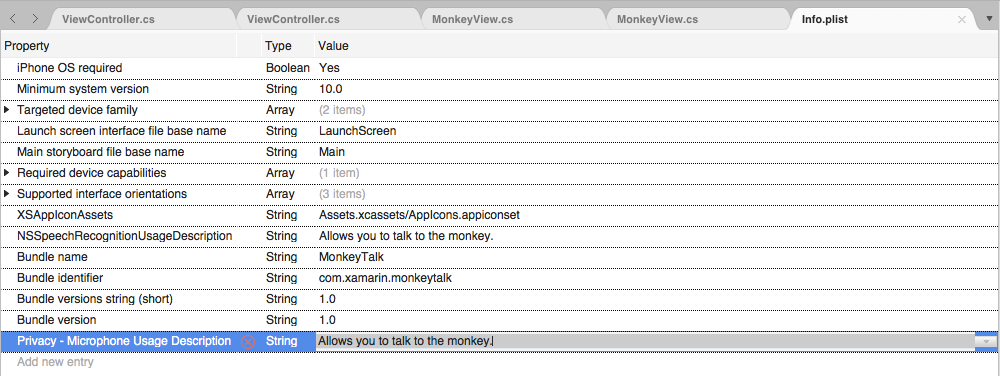
保存对文件所做的更改。





重要
尝试访问语音识别或麦克风以处理实时音频时,如果无法提供上述 Info.plist 键(NSSpeechRecognitionUsageDescription 或 NSMicrophoneUsageDescription)之一,则可能会导致应用失败,而不会发出警告。
请求授权
若要请求允许应用访问语音识别所需的用户授权,请编辑主 View Controller 类并添加以下代码:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
SFSpeechRecognizer 类的 RequestAuthorization 方法将使用开发人员在 Info.plist 文件的 NSSpeechRecognitionUsageDescription 键中提供的原因向用户请求访问语音识别的权限。
SFSpeechRecognizerAuthorizationStatus 结果将返回到 RequestAuthorization 方法的回调例程,它可用于根据用户的权限执行操作。
重要
Apple 建议等用户在应用中启动需要语音识别的操作后再请求此权限。
识别预先录制的语音
如果应用想要从预先录制的 WAV 或 MP3 文件中识别语音,则可以使用以下代码:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
详细查看此代码,它首先尝试创建一个语音识别器 (SFSpeechRecognizer)。 如果语音识别不支持默认语言,则会返回 null 且函数会退出。
如果语音识别器可用于默认语言,则应用会使用 Available 属性检查它当前是否可用于识别。 例如,如果设备没有活动的 Internet 连接,则识别可能不可用。
SFSpeechUrlRecognitionRequest 是从 iOS 设备上预先录制的文件的 NSUrl 位置创建的,它被交给语音识别器以使用回调例程进行处理。
调用回调时,如果 NSError 不是 null,则存在必须处理的错误。 由于语音识别是以增量方式完成的,因此可以多次调用回调例程,以对 SFSpeechRecognitionResult.Final 属性进行测试,确定翻译是否完整且翻译的最佳版本是否已写出 (BestTranscription)。
识别实时语音
如果应用想要识别实时语音,该过程与识别预先录制的语音非常相似。 例如:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
详细查看此代码,它会创建多个专用变量来处理识别过程:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
它使用 AV Foundation 录制将传递给 SFSpeechAudioBufferRecognitionRequest 以处理识别请求的音频:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
如果无法启动录制,应用将尝试开始录制,并处理任何错误:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
识别任务启动,句柄留给识别任务 (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
回调的使用方式与上面在预先录制的语音上的使用方式相似。
如果用户停止录制,则会通知音频引擎和语音识别请求:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
如果用户取消识别,则会通知音频引擎和识别任务:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
如果用户取消翻译以释放内存和设备处理器,请务必调用 RecognitionTask.Cancel。
重要
未能提供NSSpeechRecognitionUsageDescription或NSMicrophoneUsageDescriptionInfo.plist密钥可能会导致应用在尝试访问语音识别或麦克风进行实时音频时失败,而不会发出警告。var node = AudioEngine.InputNode; 有关详细信息,请参阅上面的提供使用说明部分。
语音识别限制
在 iOS 应用中使用语音识别时,Apple 会施加以下限制:
- 语音识别对所有应用免费,但用量并不无限:
- 各个 iOS 设备具有每天可执行的有限的识别数量。
- 应用将按每天的请求受到全局限制。
- 应用必须准备好处理语音识别网络连接和使用速率限制失败。
- 语音识别会给用户的 iOS 设备带来很高的电池损耗和网络流量成本,因此,Apple 施加了大约一分钟的语音持续时间上限。
如果某个应用经常达到其速率限制的上限,Apple 会要求开发人员与他们联系。
隐私和可用性注意事项
Apple 在 iOS 应用中加入语音识别时,发布了以下关于保持透明并尊重用户隐私的建议:
- 录制用户的语音时,请务必清楚地指示录制是在应用的用户界面中发生的。 例如,应用可能会播放“录制”声音并显示录制指示器。
- 请勿对敏感信息(如密码、健康数据或财务信息)使用语音识别。
- 在对识别结果执行操作之前显示它们。 这不仅能提供有关应用正在执行的操作的反馈,还让用户可以在发生识别错误时处理它们。
总结
本文介绍了新的语音 API,并演示了如何在 Xamarin.iOS 应用中实现它,以支持连续语音识别和将语音(从实时或录制的音频流)听录为文本。