Azure Data Lake Storage 迁移准则和模式
可以将数据、工作负载和应用程序从 Azure Data Lake Storage Gen1 迁移到 Azure Data Lake Storage Gen2。 本文介绍了建议的迁移方法,以及不同的迁移模式和何时使用每个迁移模式。 为了便于阅读,本文使用术语 Gen1 来指代 Azure Data Lake Storage Gen1,并使用术语 Gen2 来指代 Azure Data Lake Storage Gen2 。
注意
Azure Data Lake Storage Gen1 现已停用。 请参阅此处的停用公告。Data Lake Storage Gen1 资源不再可访问。
Azure Data Lake Storage Gen2 以 Azure Blob 存储为基础而构建,能够提供一组专用于大数据分析的功能。 Data Lake Storage Gen2 将 Azure Data Lake Storage Gen1 中的功能(例如文件系统语义、目录、文件级安全性和规模)与 Azure Blob 存储中的低成本分层存储、高可用性/灾难恢复功能进行了组合。
注意
由于 Gen1 和 Gen2 是不同的服务,因此没有就地升级体验。 若要使用 Azure 门户简化迁移到 Gen2 的过程,请参阅使用 Azure 门户将 Azure Data Lake Storage 从 Gen1 迁移到 Gen2。
推荐的方法
若要从 Gen1 迁移到 Gen2,我们建议采用以下方法。
步骤1:评估准备情况
步骤 2:准备进行迁移
步骤 3:迁移数据和应用程序工作负载
步骤 4:从 Gen1 转换为 Gen2
步骤1:评估准备情况
了解 Data Lake Storage Gen2 产品/服务及其优势、成本和常规体系结构。
将 Gen1 的功能与 Gen2 的功能进行比较。
查看已知问题的列表,评估功能间的任何差距。
Gen2 支持诊断日志记录、访问层和 Blob 存储生命周期管理策略等 Blob 存储功能。 如果你对使用其中任何一种功能感兴趣,请查看当前支持级别。
查看 Azure 生态系统支持的当前状态,确保 Gen2 支持解决方案所依赖的任何服务。
步骤 2:准备进行迁移
确定要迁移的数据集。
利用此机会清理不再使用的数据集。 除非计划一次迁移所有数据,否则请花些时间来确定可以分阶段迁移的数据逻辑组。
对 Gen1 帐户执行老化分析(或类似功能),以确定哪些文件或文件夹在库存中保留了很长时间或可能即将过时。
确定迁移将对你的业务造成的影响。
例如,请考虑进行迁移时是否可以承受任何停机时间。 这些注意事项可以帮助你确定适当的迁移模式,并选择最合适的工具。
创建迁移计划。
建议采用这些迁移模式。 可以选择其中一种模式,将它们组合在一起,或者设计自己的自定义模式。
步骤 3:迁移数据、工作负载和应用程序
使用你喜欢的模式迁移数据、工作负载和应用程序。 建议以增量方式验证方案。
创建存储帐户启用分层命名空间功能。
迁移数据。
将工作负载中的服务配置为指向 Gen2 终结点。
对于 HDInsight 群集,可将存储帐户配置设置添加到 %HADOOP_HOME%/conf/core-site.xml 文件。 如果你打算将外部 Hive 表从 Gen1 迁移到 Gen2,请确保将存储帐户设置也添加到 %HIVE_CONF_DIR%/hive-site.xml 文件。
可以使用 Apache Ambari 修改每个文件的设置。 若要查找存储帐户设置,请参阅 Hadoop Azure 支持:ABFS - Azure Data Lake Storage Gen2。 此示例使用
fs.azure.account.key设置来启用共享密钥授权:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>有关可帮助你将 HDInsight、Azure Databricks 和其他 Azure 服务配置为使用 Gen2 的文章链接,请参阅支持 Azure Data Lake Storage Gen2 的 Azure 服务。
更新应用程序以使用 Gen2 API。 请参阅以下指南:
更新脚本以使用 Data Lake Storage Gen2 PowerShell cmdletAzure CLI 命令。
搜索代码文件、Databricks 笔记本、Apache Hive HQL 文件或其他任何用作工作负载一部分的文件中包含字符串
adl://的 URI 引用。 将这些引用替换为新存储帐户的 Gen2 格式 URI。 例如,Gen1 URI:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfile可能会变为abfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile。在帐户上配置安全性,以包括 Azure 角色、文件和文件夹级别安全性,以及 Azure 存储防火墙和虚拟网络。
步骤 4:从 Gen1 转换为 Gen2
确信应用程序和工作负载在 Gen2 上稳定后,可以开始使用 Gen2 来满足业务场景。 关闭 Gen1 上运行的任何剩余管道,并停用 Gen1 帐户。
Gen1 与 Gen2 功能比较
此表将 Gen1 的功能与 Gen2 的功能进行了比较。
| 区域 | Gen1 | Gen2 |
|---|---|---|
| 数据组织 | 分层命名空间 文件和文件夹支持 |
分层命名空间 容器、文件和文件夹支持 |
| 异地冗余 | LRS | LRS、ZRS、GRS、RA-GRS |
| 身份验证 | Microsoft Entra 托管标识 服务主体 |
Microsoft Entra 托管标识 服务主体 共享访问密钥 |
| 授权 | 管理 - Azure RBAC 数据 - ACL |
管理 - Azure RBAC 数据 - ACL、Azure RBAC |
| 加密 - 静态数据 | 服务器端 - 使用 Microsoft 管理或客户管理的密钥 | 服务器端 - 使用 Microsoft 管理或客户管理的密钥 |
| VNET 支持 | VNET 集成 | 服务终结点、专用终结点 |
| 开发人员体验 | REST、.NET、Java、Python、PowerShell、Azure CLI | 公开发布 - REST、.NET、Java、Python 公共预览版 - JavaScript、PowerShell、Azure CLI |
| 资源日志 | 经典日志 已集成 Azure Monitor |
经典日志 - 正式发布 已集成 Azure Monitor - 预览版 |
| 生态系统 | HDInsight (3.6)、Azure Databricks(3.1 及更高版本)、Azure Synapse Analytics、ADF | HDInsight(3.6、4.0)、Azure Databricks(5.1 及更高版本)、Azure Synapse Analytics、ADF |
Gen1 到 Gen2 的模式
选择迁移模式,并根据需要修改该模式。
| 迁移模式 | 详细信息 |
|---|---|
| 直接迁移 | 最简单的模式。 如果数据管道可以承受停机,这是理想选择。 |
| 增量复制 | 类似于直接迁移,但停机时间更少。 非常适合需要较长时间才能复制的大量数据。 |
| 双管道 | 非常适合无法承受任何停机时间的管道。 |
| 双向同步 | 类似于双管道,但具有更具阶段性的方法,适用于更复杂的管道。 |
我们来详细了解每种模式。
直接迁移模式
这是最简单的模式。
停止对 Gen1 的所有写入操作。
将数据从 Gen1 移动到 Gen2。 建议使用 Azure 数据工厂,或使用 Azure 门户。 ACL 随数据一起复制。
将引入操作和工作负载指向 Gen2。
停用 Gen1。
请查看直接迁移示例中的直接迁移模式示例代码。
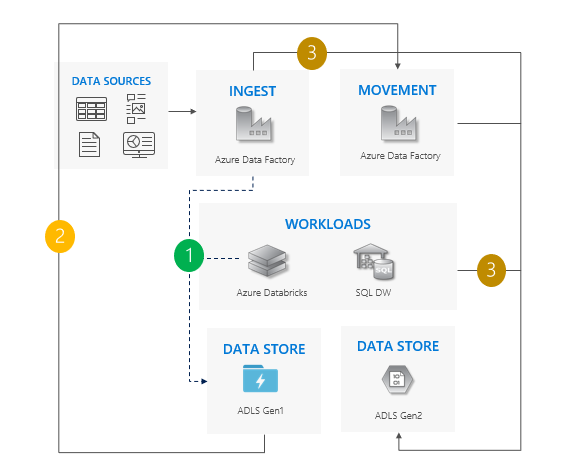
使用直接迁移模式的注意事项
同时将所有工作负载从 Gen1 切换到 Gen2。
预期在迁移和切换期间会停机。
非常适合能够承受停机并且可以一次性升级所有应用的管道。
提示
请考虑使用Azure 门户缩短停机时间,并减少完成迁移所需的步骤数。
增量复制模式
开始将数据从 Gen1 移动到 Gen2。 建议使用 Azure 数据工厂。 ACL 随数据一起复制。
以增量方式复制 Gen1 中的新数据。
复制所有数据后,停止对 Gen1 的所有写入操作,并将工作负载指向 Gen2。
停用 Gen1。
请查看增量复制迁移示例中的增量复制模式示例代码。
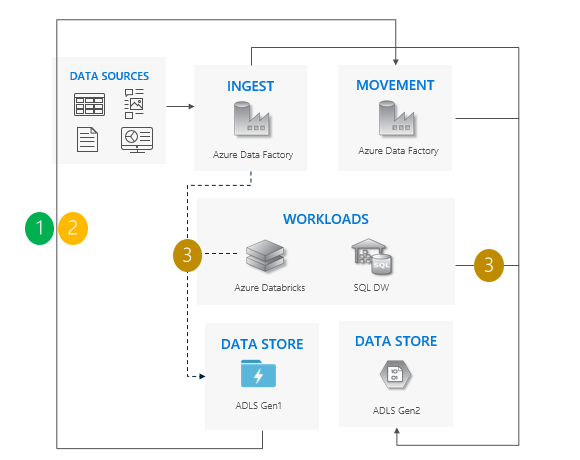
使用增量复制模式时的注意事项:
同时将所有工作负载从 Gen1 切换到 Gen2。
预期只会在切换期间停机。
非常适合可一次性升级所有应用,但数据复制需要更多时间的管道。
双管道模式
将数据从 Gen1 移动到 Gen2。 建议使用 Azure 数据工厂。 ACL 随数据一起复制。
将新数据引入 Gen1 和 Gen2。
将工作负载指向 Gen2。
停止对 Gen1 的所有写入操作,并停用 Gen1。
请查看双管道迁移示例中双管道模式的示例代码。
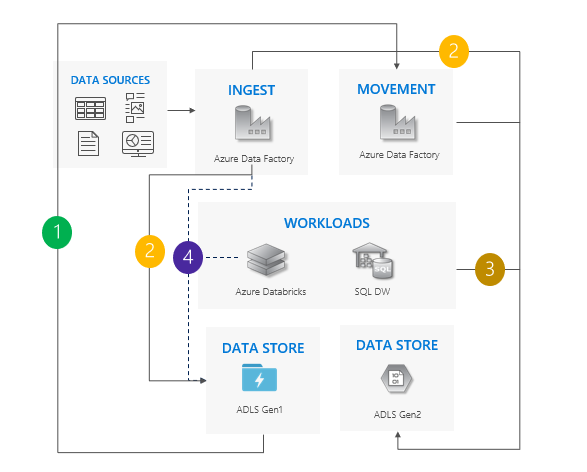
使用双管道模式时的注意事项:
Gen1 和 Gen2 管道并行运行。
支持零停机时间。
当工作负载和应用程序无法承受任何停机,并且你可以引入两个存储帐户时,这是理想选择。
双向同步模式
在 Gen1 和 Gen2 之间设置双向复制。 建议使用 WanDisco。 它为现有数据提供了修复功能。
完成所有移动后,停止对 Gen1 的所有写入操作并关闭双向复制。
停用 Gen1。
请查看双向同步迁移示例中双向同步模式的示例代码。
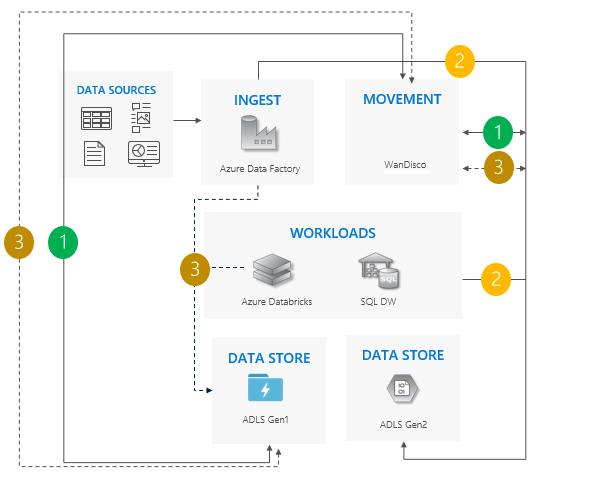
使用双向同步模式时的注意事项:
非常适用于涉及大量管道和依赖项的复杂方案,其中分阶段方法可能更有意义。
迁移工作量很大,但它为 Gen1 和 Gen2 提供并行支持。
后续步骤
- 了解为存储帐户设置安全性的各个部分。 有关详细信息,请参阅 Azure 存储安全指南。
- 优化 Data Lake Store 的性能。 请参阅优化 Azure Data Lake Storage Gen2 性能。
- 查看管理 Data Lake Store 的最佳做法。 请参阅使用 Azure Data Lake Storage Gen2 的最佳做法