在 Azure Kubernetes 服务 (AKS) 上的 Azure HDInsight 中使用 Delta Lake 搭配 Apache Spark™ 群集(预览版)
重要
AKS 上的 Azure HDInsight 已于 2025 年 1 月 31 日停用。 了解此公告的详细信息。
需要将工作负荷迁移到 Microsoft Fabric 或等效的 Azure 产品,以避免工作负荷突然终止。
重要
此功能目前以预览版提供。 Microsoft Azure 预览版补充使用条款 包括适用于处于测试版、预览版或尚未正式上市的 Azure 功能的更多法律条款。 有关此特定预览版的信息,请参阅 AKS 预览版信息中的 Azure HDInsight。 有关问题或功能建议,请在 AskHDInsight 上提交请求,附上详细信息,并关注我们以获取 Azure HDInsight 社区 的更多更新。
AKS 上的 Azure HDInsight 是一种基于云的托管服务,用于大数据分析,可帮助组织处理大量数据。 本教程演示如何在 Azure Kubernetes 服务 (AKS) 上的 Azure HDInsight 中使用 Delta Lake 和 Apache Spark™ 群集。
先决条件
在 AKS 上的 Azure HDInsight 中创建 Apache Spark™ 群集
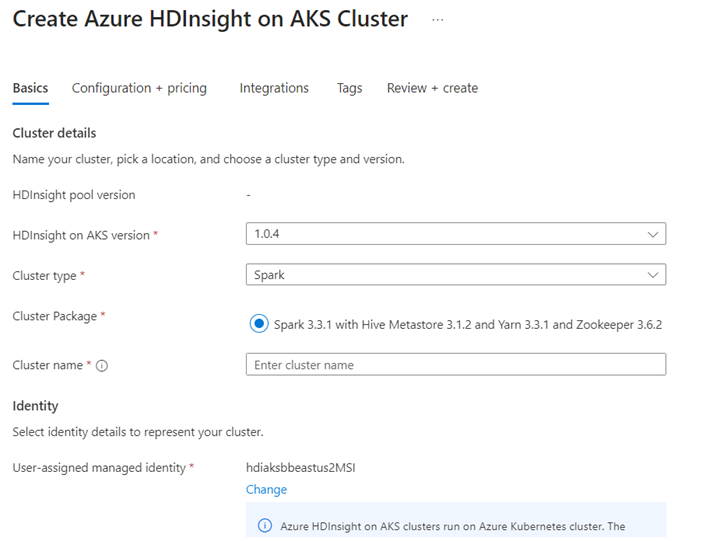
在 Jupyter Notebook 中运行 Delta Lake 方案。 创建 Jupyter 笔记本并在创建笔记本时选择“Spark”,因为以下示例位于 Scala 中。
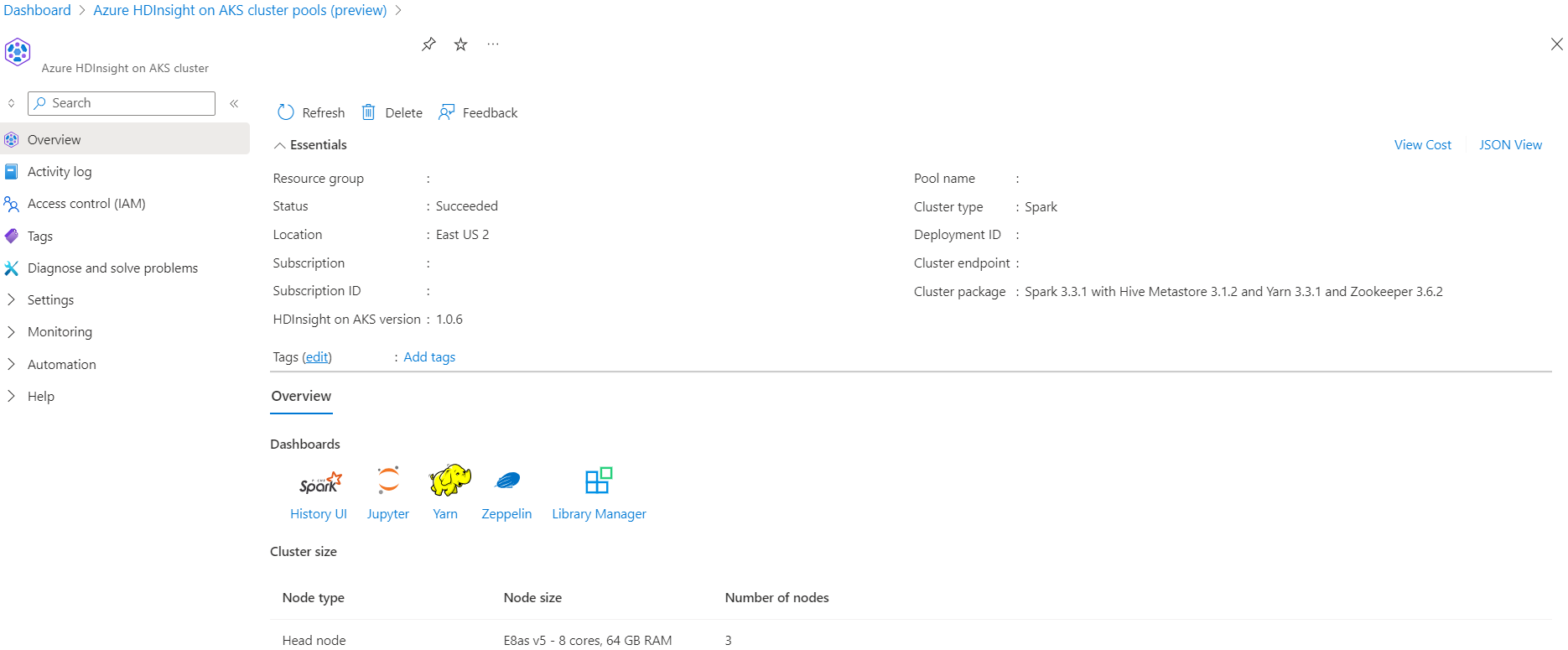


场景
- 读取 NYC 出租车 Parquet 数据格式 - 从 纽约市出租车 & 豪华轿车委员会提供 Parquet 文件 URL 列表。
- 对于每个 URL(文件),执行一些转换,并采用 Delta 格式存储。
- 使用增量负载计算 Delta 表的平均距离、每英里的平均成本和平均费用。
- 将步骤 3 中的计算值以增量格式存储在 KPI 输出文件夹中。
- 在 Delta 格式输出文件夹中创建 Delta 表(自动刷新)。
- KPI 输出文件夹具有多个版本的平均距离和行程每英里的平均成本。
提供 Delta Lake 的所需配置
具有 Apache Spark 兼容性矩阵的 Delta Lake - Delta Lake,基于 Apache Spark 版本更改 Delta Lake 版本。
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}
显示 delta lake 配置的 
列出数据文件
注意
这些文件链接来自 纽约市出租车和豪华轿车管理委员会 &。
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

创建输出目录
要创建增量格式输出的位置,根据需要更改 transformDeltaOutputPath 和 avgDeltaOutputKPIPath 变量,
-
avgDeltaOutputKPIPath- 以增量格式存储平均 KPI -
transformDeltaOutputPath- 以增量格式存储转换的输出
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

将 Parquet 格式的数据转换为 Delta 格式数据
输入数据来自
listOfDataFile,数据是从 https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page 下载的。若要演示时间旅行和版本,请单独加载数据
在增量负载上执行转换和计算以下业务 KPI:
- 平均距离
- 每英里的平均成本
- 平均成本
以增量格式保存转换的和 KPI 数据
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
使用 Delta 表读取 Delta 格式
- 读取转换的数据
- 读取 KPI 数据
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)显示读取 KPI 数据的

打印架构
- 打印已转换的增量表架构和平均 KPI 数据 1。
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema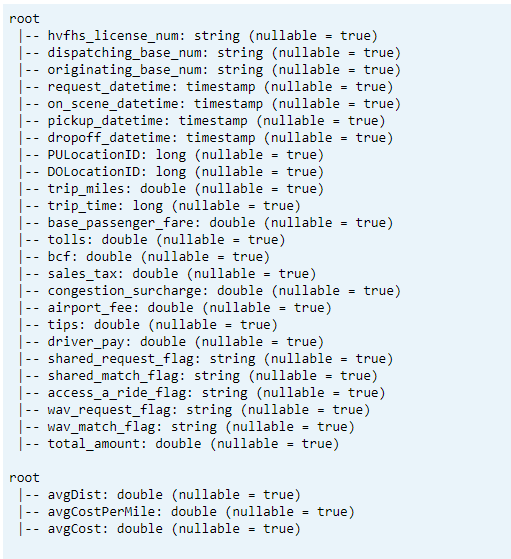
显示数据表中最近计算的KPI
dtAvgKpi.toDF.show(false)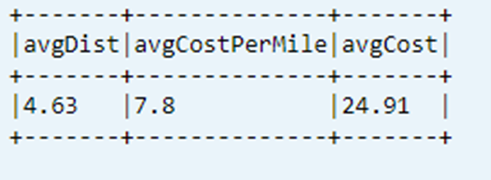


显示计算 KPI 历史记录
此步骤将显示 _delta_log 的 KPI 事务表历史记录
dtAvgKpi.history().show(false)

在每个数据加载后显示 KPI 数据
- 使用时间旅行,可以在每次加载后查看 KPI 更改
- 可以在
avgMoMKPIChangePath存储 CSV 格式的所有版本更改,以便 Power BI 可以读取这些更改
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

参考
- Apache、Apache Spark、Spark 和关联的开源项目名称 Apache Software Foundation(ASF) 的商标。