什么是 AKS 上的 Azure HDInsight 中的 Apache Flink®? (预览版)
重要
AKS 上的 Azure HDInsight 已于 2025 年 1 月 31 日停用。 了解此公告的详细信息。
需要将工作负荷迁移到 Microsoft Fabric 或等效的 Azure 产品,以避免工作负荷突然终止。
重要
此功能目前以预览版提供。 Microsoft Azure 预览版补充使用条款 包括更多适用于测试版、预览版或暂未正式发布的 Azure 功能的法律条款。 有关此特定预览版的信息,请参阅 Azure HDInsight 在 AKS 上的预览信息。 有关问题或功能建议,请在 AskHDInsight 上提交请求,并提供详细信息。请关注我们以获取 Azure HDInsight 社区 的更多更新。
Apache Flink 是一个框架和分布式处理引擎,用于通过无限和有限数据流进行有状态计算。 Flink 已被设计用于在所有常见的集群环境中运行,以内存速度和任意规模执行计算和有状态流应用程序。 应用程序并行化为可能成千上万的任务,这些任务在群集中分发和并发执行。 因此,应用程序可以使用无限数量的 vCPU、主内存、磁盘和网络 IO。 此外,Flink 可以轻松维护大型应用程序状态。 其异步和增量检查点算法可确保对处理延迟的影响最小,同时保证一旦状态一致性。
Apache Flink 是一个大规模可缩放的分析引擎,用于流处理。
Flink 提供的一些主要功能包括:
- 对有限流和无限流的操作
- 内存性能表现
- 支持流式和批处理计算的能力
- 低延迟、高吞吐量操作
- 精确一次处理
- 高可用性
- 状态和容错
- 与 Hadoop 生态系统完全兼容
- 流和批处理的统一 SQL API
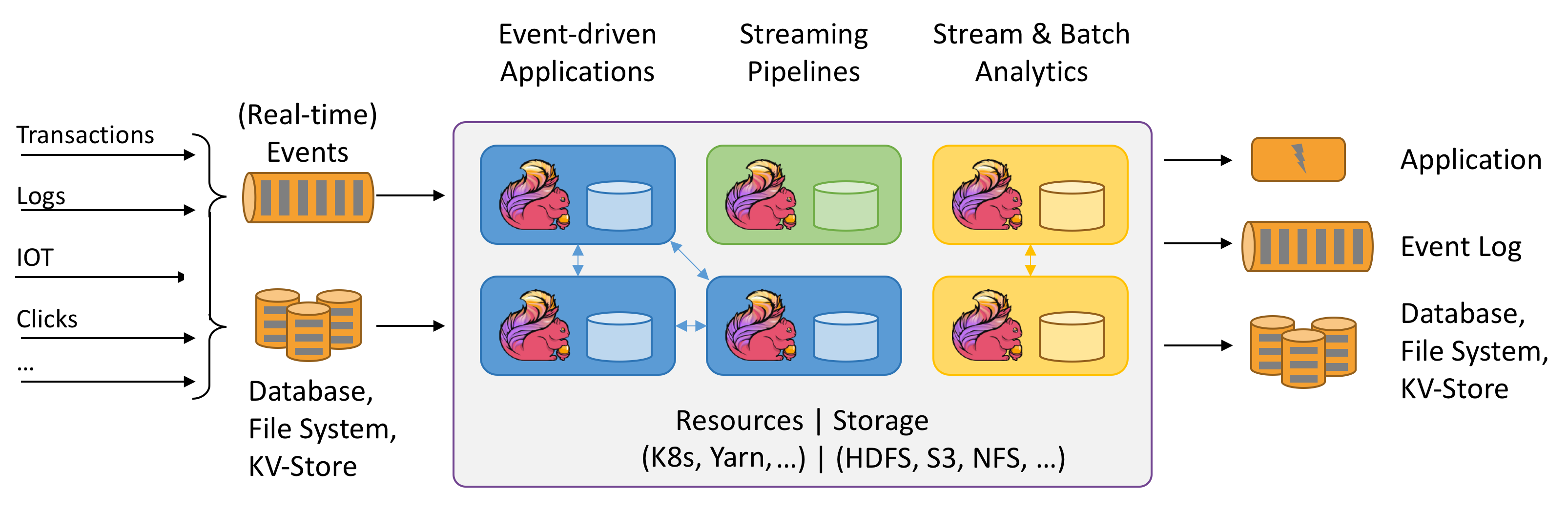
为什么使用 Apache Flink?
Apache Flink 是开发和运行许多不同类型的应用程序的绝佳选择,因为它具有广泛的功能集。 Flink 的功能包括支持流和批处理、复杂的状态管理、事件时间处理语义,以及一次性的状态保证。 Flink 没有单一故障点。 Flink 已被证明是扩展到数千个核心和 TB 的应用程序状态,提供高吞吐量和低延迟,并为世界上一些最苛刻的流处理应用程序提供支持。
- 欺诈检测:Flink 可用于实时检测欺诈交易或活动,方法是对流式处理数据应用复杂的规则和机器学习模型。
- 异常情况检测:Flink 可用于识别流数据中的离群值或异常模式,例如传感器读数、网络流量或用户行为。
- 基于规则的警报:Flink 可用于根据预定义条件或流式处理数据的阈值(如温度、压力或股票价格)触发警报或通知。
- 业务流程监视:Flink 可用于实时跟踪和分析业务流程或工作流的状态和性能,例如订单履行、交付或客户服务。
- Web 应用程序(社交网络):Flink 可用于为需要实时处理用户生成的数据的 Web 应用程序提供支持,例如消息、赞、注释或建议。
详细了解有关 Apache Flink 用例 的常见用例
在 AKS 上的 HDInsight 中,Apache Flink 群集是一个完全托管的服务。 此处列出了在 AKS 上的 HDInsight 中创建 Flink 群集的好处。
| 特性 | 描述 |
|---|---|
| 轻松创建 | 可以使用 Azure 门户、Azure PowerShell 或 SDK 在 HDInsight 中几分钟内创建新的 Flink 群集。 请参阅 AKS上的 HDInsight 中的 Apache Flink 群集入门。 |
| 易于使用 | AKS 上的 HDInsight 中的 Flink 群集包括基于门户的配置管理以及缩放功能。 除了使用作业管理 API 以外,还可以使用 REST API 或 Azure 门户进行作业管理。 |
| REST API | AKS 上的 HDInsight 中的 Flink 群集包括 作业管理 API,这是一种基于 REST API 的 Flink 作业提交方法,用于在 Azure 门户中远程提交和监视作业。 |
| 部署类型 | Flink 可以在会话模式或应用程序模式下执行应用程序。 目前,AKS 上的 HDInsight 仅支持会话群集。 可以在会话群集上运行多个 Flink 作业。 AKS 群集上的 HDInsight 已经在路线图中加入了应用模式 |
| 对元存储的支持 | AKS 上的 HDInsight 中的 Flink 群集可以支持具有 不同开放文件格式的 hive 元存储 的目录,这些目录采用远程检查点到 Azure Data Lake Storage Gen2。 |
| 对 Azure 存储的支持 | HDInsight 中的 Flink 群集可以使用 Azure Data Lake Storage Gen2 作为文件接收器。 有关 Data Lake Storage Gen2 的详细信息,请参阅 Azure Data Lake Storage Gen2。 |
| 与 Azure 服务集成 | AKS 上的 HDInsight 中的 Flink 群集与 Kafka 集成,以及 Azure 事件中心 和 Azure HDInsight。 可以使用事件中心或 HDInsight 构建流式处理应用程序。 |
| 适应性 | 借助 AKS 上的 HDInsight,您可以利用自动缩放功能根据计划来缩放 Flink 群集节点。 请参阅 在 AKS 集群上自动扩展 Azure HDInsight。 |
| 后端状态管理 | AKS 上的 HDInsight 使用 RocksDB 作为默认 StateBackend。 RocksDB 是一种可嵌入的持久键值存储,用于快速存储。 |
| 检查站 | 默认情况下,HDInsight 在 AKS 集群中启用了检查点功能。 AKS 上的 HDInsight 上的默认设置维护持久存储中的最后五个检查点。 如果作业失败,可以从最新的检查点重启作业。 |
| 增量检查点 | RocksDB 支持增量检查点。 我们建议将增量检查点用于大型状态,需要手动启用此功能。 在 flink-conf.yaml: state.backend.incremental: true 中设置默认值会启动增量检查点,除非应用程序在代码中重写此设置。 默认情况下,此语句为真。 也可以直接在代码(替代配置默认值)EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); 中配置此值。 默认情况下,我们会在配置的检查点 dir 中保留最后五个检查点。 可以通过更改配置管理部分中的配置 state.checkpoints.num-retained: 5 更改此值 |
AKS 上的 HDInsight 中的 Apache Flink 群集包括以下组件,它们默认在群集上可用。
请参阅 路线图,了解即将到来的内容!
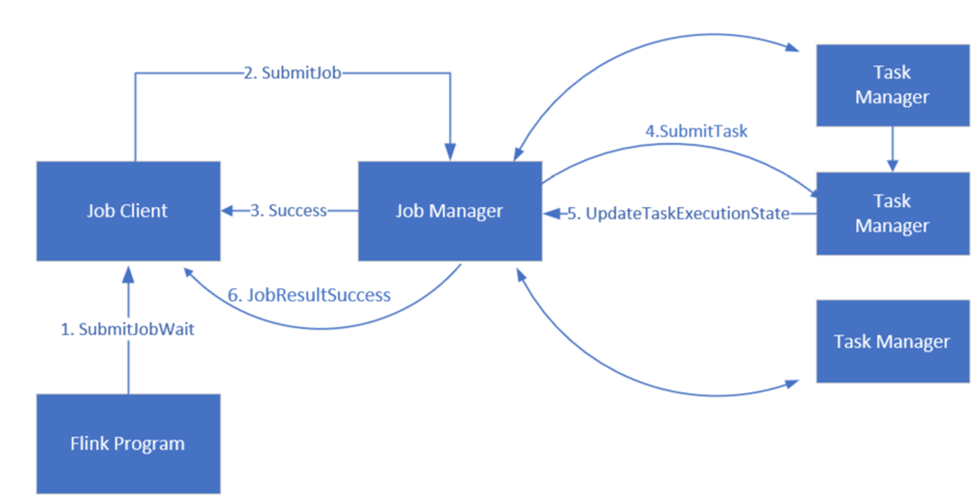
Apache Flink 作业管理
Flink 使用三个分布式组件(作业管理器、任务管理器和作业客户端)计划作业,这些组件以 Leader-Follower 模式设置。
Flink 作业:一个 Flink 作业或程序由多个任务组成。 任务是 Flink 中执行的基本单元。 每个 Flink 任务具有多个实例,具体取决于并行度级别,每个实例在 TaskManager 上执行。
作业管理器:作业管理器作为一个调度程序,在任务管理器上调度任务。
任务管理器:任务管理器配备一个或多个插槽用于并行执行任务。
作业客户端:作业客户端与作业管理器通信以提交 Flink 作业
Flink Web UI:Flink 具有一个 Web UI,用于检查、监控和调试正在运行的应用程序。
参考
- Apache Flink 网站
- Apache、Apache Kafka、Kafka、Apache Flink、Flink 和关联的开源项目名称是 Apache 软件基金会 (ASF) 的商标。