使用 针对 Visual Studio 的 Azure Data Lake 工具 解决 Azure Data Lake Analytics中的数据倾斜问题
重要
Azure Data Lake Analytics已于 2024 年 2 月 29 日停用。 通过此公告了解更多信息。
对于数据分析,你的组织可以使用 Azure Synapse Analytics 或 Microsoft Fabric。
什么是数据倾斜?
简而言之,数据倾斜就是某个值的数据分布不均衡。 假设你已分配了 50 名税务检查员来审核纳税申报,每个州都有一名审查员。 怀俄明州的考官,因为那里的人口很少,没有什么可做的。 然而,在加利福尼亚州,由于该州人口众多,检查员一直很忙。

在上面的情形中,数据在所有税务检查员之间的分配并不均衡,也就是说,某些检查员的工作量超出其他检查员。 在自己的作业中,会经常遇到类似此处例举的税务检查员的情形。 用更技术化的术语来说,数据倾斜是指一个顶点获得的数据量远远超出其对等项,导致该顶点的工作量超出其他顶点,最终延缓了整个作业的完成速度。 更糟的是,作业可能会失败,因为顶点可能存在限制,例如 5 小时的运行时限制和 6 GB 的内存限制。
解决数据倾斜问题
针对 Visual Studio 的 Azure Data Lake 工具和Visual Studio Code可帮助检测作业是否存在数据倾斜问题。
如果存在问题,可以尝试用本部分的解决方案来解决。
解决方法 1:改善表分区
选项 1:提前筛选偏斜的键值
如果它不会影响业务逻辑,可以提前筛选更高频率的值。 例如,如果列 GUID 中有许多 000-000-000,则可能不希望聚合该值。 在聚合之前,可以编写“WHERE GUID != “000-000-000””来筛选高频值。
选项 2:选择不同的分区或分布键
在前面的示例中,如果只想检查整个国家/地区的税务/审计工作负荷,则可选择 ID 号作为键来改进数据分布。 有时,选择不同的分区或分布键可以更均衡地分配数据,但需确保该选择不会影响业务逻辑。 例如,若要计算每个州的税收总额,则可能需指定 State 作为分区键。 如果仍遇到此问题,请尝试使用选项 3。
选项 3:添加更多的分区键或分布键
可以使用多个键进行分区,而不是仅使用 State 作为分区键。 例如,考虑将 邮政编码 添加为另一个分区键,以减少数据分区大小并更均匀地分布数据。
选项 4:使用轮循机制分布
如果找不到分区和分布的相应键,可以尝试使用轮循机制分布。 轮循机制分布可以均匀处理所有行,并将其随机放入相应的桶中。 数据将均匀分布,但会丢失位置信息,因此也会在某些操作中降低作业性能,这是其缺点。 此外,如果仍要对倾斜键执行聚合,则数据倾斜问题将持续存在。 若要详细了解轮循机制分布,请参阅 CREATE TABLE (U-SQL) :使用架构创建表中的 U-SQL 表分布部分。
解决方案 2:改进查询计划
选项 1:使用 CREATE STATISTICS 语句
U-SQL 提供针对表的 CREATE STATISTICS 语句。 此语句向查询优化器提供有关数据特征 (的详细信息,例如存储在表中的值分布) 。 对于大多数查询,查询优化器已生成高质量查询计划所必需的统计信息。 有时,可能需要通过使用 CREATE STATISTICS 创建更多统计信息或修改查询设计来提高查询性能。 有关详细信息,请参阅 CREATE STATISTICS (U-SQL) 页。
代码示例:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
注意
统计信息不会自动更新。 如果在不重新创建统计信息的情况下更新表中的数据,查询性能可能会降低。
选项 2:使用 SKEWFACTOR
如果需要对每个州的税收数据进行汇总,则必须使用“GROUP BY state”方法,但此方法无法避免数据倾斜问题。 但是,可以在查询中提供数据提示来识别键中的数据倾斜,以便优化器准备执行计划。
通常,可以将参数设置为 0.5 和 1,其中 0.5 表示不太多倾斜,1 表示严重倾斜。 由于提示会影响当前语句以及所有下游语句的执行计划优化,因此请确保在执行可能有倾斜的键范围聚合之前添加提示。
SKEWFACTOR (columns) = x
提示给定列的倾斜因子 x 从 0 到 0 (无倾斜) 到 1 (严重倾斜) 。
代码示例:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
选项 3:使用 ROWCOUNT
如果知道其他联接的行集较小,则除了添加适用于特定倾斜键联接案例的 SKEWFACTOR,还可以在 U-SQL 语句中将 ROWCOUNT 提示添加到 JOIN 之前,以便告知优化器这一点。 这样一来,优化器就可以选择广播联接策略,以便改进性能。 请注意,ROWCOUNT 无法解决数据倾斜问题,但它可以提供一些额外的帮助。
OPTION(ROWCOUNT = n)
通过提供一个估计的整数行数,在 JOIN 之前标识一个小行集。
代码示例:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
解决方案 3:改进用户定义的化简器和组合器
有时,可以编写用户定义的运算符来处理复杂的过程逻辑,精心编写的化简器和组合器在某些情况下可以缓解数据倾斜问题。
选项 1:在可能的情况下使用递归化简器
默认情况下,用户定义的化简器在非递归模式下运行,这意味着键的化简工作将分布到单个顶点中。 但如果数据倾斜,则巨型数据集可能会在单个顶点中处理并长时间运行。
若要提高性能,可在代码中添加属性,以便定义在递归模式下运行的化简器。 然后,可将巨型数据集分配到多个顶点并以并行方式运行,加快作业速度。
若要将非递归化简器更改为递归,需要确保算法是关联算法。 例如,总和是关联性的,而中值不是。 此外,需确保化简器的输入和输出保持相同的架构。
递归化简器的属性:
[SqlUserDefinedReducer(IsRecursive = true)]
代码示例:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
选项 2:在可能的情况下使用行级组合器模式
类似于特定倾斜键联接案例中的 ROWCOUNT 提示,组合器模式会尝试将巨型倾斜键值集分配到多个顶点,使工作可以并发执行。 组合器模式无法解决数据倾斜问题,但它可以为巨大的倾斜键值集提供一些额外的帮助。
默认情况下,合并器模式为“完整”,这意味着左行集和右行集不能分开。 将模式设置为“Left/Right/Inner”可以启用行级联接。 系统会分隔相应的行集,并将它们分配到多个并行运行的顶点中。 但是,在配置组合器模式之前需谨慎行事,确保相应的行集可以分隔。
以下示例显示了一个分隔的左行集。 每个输出行依赖于左侧的单个输入行,并可能依赖于右侧包含相同键值的所有行。 如果将组合器模式设置为 Left,系统会将巨型左行集分隔成小型行集,并将其分配到多个顶点。
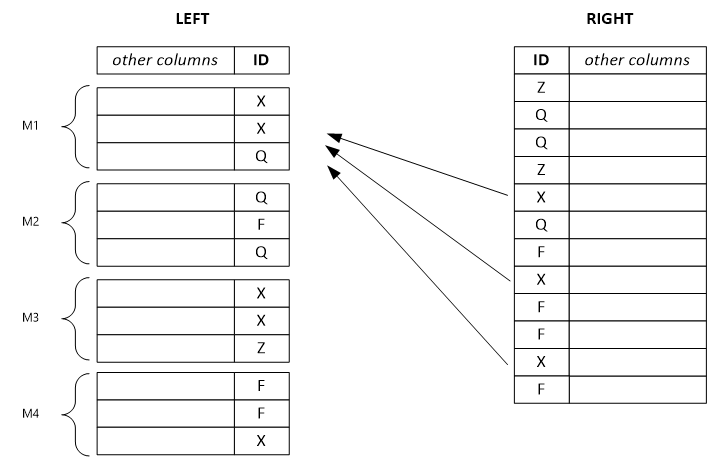
注意
如果设置了错误的组合器模式,则组合效率较低,而且结果可能错误。
组合器模式的属性:
SqlUserDefinedCombiner(Mode=CombinerMode.Full):每个输出行可能依赖于左侧和右侧具有相同键值的所有输入行。
SqlUserDefinedCombiner(Mode=CombinerMode.Left):每个输出行依赖于左侧的单个输入行(还可能依赖于右侧包含相同键值的所有行)。
qlUserDefinedCombiner(Mode=CombinerMode.Right):每个输出行依赖于右侧的单个输入行(还可能依赖于左侧包含相同键值的所有行)。
SqlUserDefinedCombiner(Mode=CombinerMode.Inner):每个输出行依赖于左侧和右侧包含相同值的单个输入行。
代码示例:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}