数据隐私防火墙的幕后
注意
隐私级别当前在 Power Platform 数据流中不可用,但产品团队正在努力启用此功能。
如果您使用 Power Query 已有一段时间,那么您可能已经体验过了。 当突然出现一个错误,再多的在线搜索、查询调整或键盘敲击都无法纠正时,您就可以查询了。 像这样的错误:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
或者:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
这些Formula.Firewall错误是 Power Query 的数据隐私防火墙(也称为“防火墙”)造成的,有时它的存在似乎只是为了让全世界的数据分析师感到沮丧。 不管您信不信,防火墙有着重要的作用。 在本文中,我们将深入探讨它的工作原理。 有了更深入的了解,您将有望在将来更好地诊断和修复防火墙错误。
这是什么?
数据隐私防火墙的目的很简单:它的存在是为了防止 Power Query 无意中在源之间泄露数据。
为什么需要这样安排? 我的意思是,您当然可以编写一些 M,将 SQL 值传递给 OData 提要。 但这将成为有意的数据泄露。 mashup 作者知道(或者至少应该知道)他们在做这件事。 那么,为什么要防止无意数据泄露?
答案是什么? 折叠。
折叠?
折叠 是一个术语,指的是将 M(例如筛选器、重命名、联接等)中的表达式转换为针对原始数据源(例如 SQL、OData 等)的操作。 Power Query 的强大功能很大一部分来自于这样一个事实:即 PQ 可以将用户通过其用户界面执行的操作转换为复杂的 SQL 或其他后端数据源语言,而无需用户了解所述语言。 用户可以从本机数据源操作中获得性能优势,因为用户界面易于使用,所有数据源都可以使用一组通用命令进行转换。
作为折叠的一部分,PQ 有时可能会确定执行给定 mashup 的最有效方法是从一个源获取数据并将其传递给另一个源。 例如,如果要将小型 CSV 文件联接到大型 SQL 表,您可能不希望 PQ 读取 CSV 文件,读取整个 SQL 表,然后在本地计算机上将它们联接在一起。 您可能希望 PQ 将 CSV 数据内联到 SQL 语句中,并要求 SQL 数据库执行联接。
这就是无意数据泄露可能发生的原因。
想象一下,如果您正在将包含员工社会安全号码的 SQL 数据与外部 OData 提要的结果连接起来,却突然发现 SQL 中的社会保障号码被发送到 OData 服务。 坏消息,对吧?
这就是防火墙要防止的情况。
工作原理
防火墙的存在是为了防止来自一个源的数据被无意地发送到另一个源。 足够简单。
那么,它是如何完成这项任务的呢?
它通过将 M 查询划分为称为分区的内容,然后强制实施以下规则来完成:
- 一个分区可以访问兼容的数据源,也可以引用其他分区,但不能同时访问两者。
简单,但令人困惑。 什么是分区? 是什么使两个数据源“兼容”? 为什么防火墙应该关心分区是否想要访问数据源并引用分区?
让我们逐一分析上述规则。
什么是分区?
在最基本的级别上,分区只是一个或多个查询步骤的集合。 最精细的分区(至少在当前实现中)是一个步骤。 最大的分区有时可以包含多个查询。 (稍后详述。)
如果您不熟悉这些步骤,可以在已应用步骤窗格中选择查询后,在 Power Query 编辑器窗口的右侧查看这些步骤。 步骤可跟踪将数据转换为最终形状所做的一切工作。
引用其他分区的分区
在防火墙打开的情况下评估查询时,防火墙会将查询及其所有依赖项划分为多个分区(即多组步骤)。 每当一个分区引用另一个分区中的内容时,防火墙会将引用替换为对称为Value.Firewall的特殊函数的调用。 换句话说,防火墙不允许分区之间直接访问。 所有引用都经过修改以通过防火墙。 将防火墙视为守门员。 引用另一分区的分区必须获取防火墙执行此操作的权限,防火墙控制是否允许引用的数据进入分区。
这一切可能看起来很抽象,那么让我们来看一个示例。
假设您有一个名为 Employees 的查询,该查询从 SQL 数据库拉取某些数据。 假设您还有另一个查询(EmployeesReference),它引用 Employees。
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
这些查询最终分为两个分区:一个用于 Employees 查询,一个用于 EmployeesReference 查询(该查询将引用 Employees 分区)。 在防火墙打开的情况下进行评估时,这些查询将被重写如下:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
请注意:对 Employees 查询的简单引用已被对Value.Firewall的调用替换,该调用提供了 Employees 查询的全名。
评估 EmployeesReference 后,防火墙将截获对Value.Firewall("Section1/Employees")的调用,该调用现在有机会控制所请求的数据是否流入 EmployeesReference 分区。 它可以执行任意数量的操作:拒绝请求、缓冲请求的数据(这可以防止对其原始数据源的任何进一步折叠),等等。
这就是防火墙对分区之间的数据流进行控制的方式。
直接访问数据源的分区
假设使用一个步骤定义查询 Query1(请注意:此单一步骤查询对应于一个防火墙分区),并且此单一步骤访问两个数据源:一个 SQL 数据库表和一个 CSV 文件。 由于没有分区引用,因此没有对Value.Firewall进行拦截的调用,那么防火墙如何处理这个问题? 让我们回顾前面所述的规则:
- 一个分区可以访问兼容的数据源,也可以引用其他分区,但不能同时访问两者。
为了使允许单分区但两个数据源查询运行,其两个数据源必须“兼容”。 换句话说,数据需要在它们之间双向共享。 这意味着,两个源的隐私级别都必须是“公开”,或者两者都是“组织”级别,因为只有这两种组合才能实现双向共享。 如果两个源都标记为“专用”;或者一个标记为“公共”,另一个标记为“组织”;或者使用其他一些隐私级别组合进行标记,则不允许双向共享,因此在同一个分区中对它们进行评估是不安全的。 这样做意味着可能会发生不安全的数据泄露(由于折叠),而防火墙却无法阻止。
如果尝试访问同一分区中的不兼容数据源,会发生什么情况?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
希望您现在能够更好地理解本文开头列出的其中一条错误消息。
请注意:此兼容性要求仅适用于给定分区。 如果分区引用其他分区,则引用的分区中的数据源不必彼此兼容。 这是因为防火墙可以缓冲数据,这会阻止对原始数据源进行进一步折叠。 数据将加载到内存中,并被视为来自其他位置。
为什么不同时这样做?
假设您用一个步骤定义一个查询(这又对应于一个分区),该步骤访问另外两个查询(即另外两个分区)。 如果想要在同一步骤中直接访问 SQL 数据库,该怎么办? 为什么分区不能引用其他分区并直接访问兼容的数据源?
如前所述,当一个分区引用另一个分区时,防火墙充当流入分区的所有数据的守门员。 为此,它必须能够控制允许的数据。 如果分区内有数据源被访问,并且数据从其他分区流入,则它将失去作为守门员的能力,因为流入的数据可能会在不知情的情况下泄露给内部访问的某个数据源。 因此,防火墙防止访问其他分区的分区被允许直接访问任何数据源。
那么,如果分区尝试引用其他分区并直接访问数据源,会发生什么情况?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
现在,希望您能更好地理解本文开头列出的其他错误消息。
深入了解分区
正如您可能从上面的信息中猜到的那样,如何对查询进行分区最终变得极其重要。 如果您有一些引用其他查询的步骤,以及访问数据源的其他步骤,那么您现在应该认识到,在某些地方绘制分区边界将导致防火墙错误,而在其他位置绘制分区边界将允许查询运行正常。
那么,如何对查询进行分区?
本节可能是了解防火墙错误的原因以及如何解决这些错误(在可能的情况下)的最重要部分。
以下是分区逻辑的高级摘要。
- 初始分区
- 为每个查询中的每个步骤创建一个分区
- 静态阶段
- 此阶段不依赖于评估结果。 相反,它依赖于查询的结构。
- 参数调整
- 调整参数式分区,即以下任一分区:
- 不引用任何其他分区
- 不包含任何函数调用
- 不是循环的(也就是说,它不指代自己)
- 请注意:“删除”分区可有效地将其包含在引用它的任何其他分区中。
- 调整参数分区允许数据源函数调用(例如
Web.Contents(myUrl))中使用的参数引用正常工作,而不是引发“分区不能引用数据源和其他步骤”错误。
- 调整参数式分区,即以下任一分区:
- 分组(静态)
- 分区按自下而上的依赖项顺序合并。 在生成的合并分区中,以下项将会分开:
- 不同查询中的分区
- 不引用其他分区(并因此被允许访问数据源)的分区
- 不引用其他分区(并因此被禁止访问数据源)的分区
- 分区按自下而上的依赖项顺序合并。 在生成的合并分区中,以下项将会分开:
- 参数调整
- 此阶段不依赖于评估结果。 相反,它依赖于查询的结构。
- 动态阶段
- 此阶段取决于评估结果,包括关于各个分区访问的数据源的信息。
- 调整
- 调整符合以下所有要求的分区:
- 无法访问任何数据源
- 不引用访问数据源的任何分区
- 不是循环的
- 调整符合以下所有要求的分区:
- 分组(动态)
- 现在已调整不必要的分区,请尝试创建尽可能大的源分区。 这是通过使用上面静态分组阶段中所述的相同规则合并分区来实现的。
这一切意味着什么?
让我们演练一个示例,说明上述复杂逻辑的工作原理。
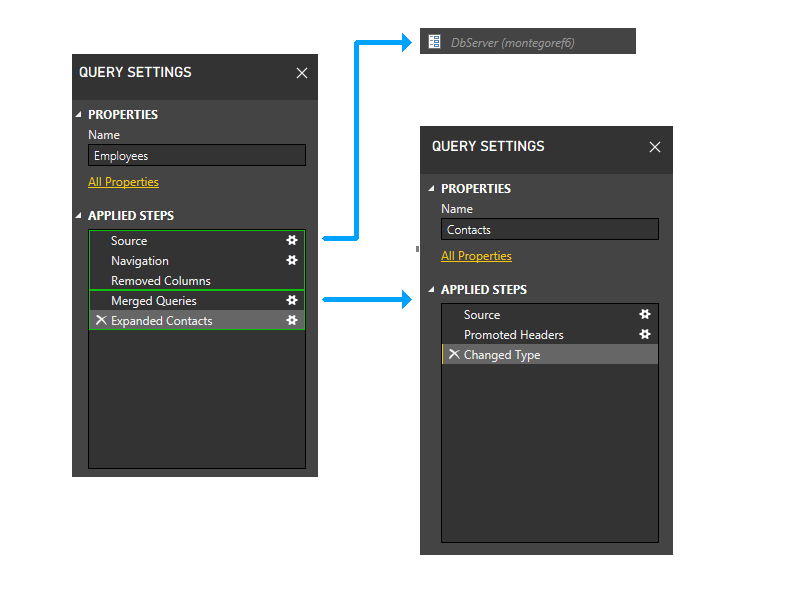
下面是一个示例方案。 这是一个文本文件 (Contacts) 与 SQL 数据库 (Employees) 相当简单的合并,其中 SQL Server 是参数 (DbServer)。
三个查询
以下是本例中使用的三个查询的 M 代码。
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents("C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"ContactID", Int64.Type}, {"NameStyle", type logical}, {"Title", type text}, {"FirstName", type text}, {"MiddleName", type text}, {"LastName", type text}, {"Suffix", type text}, {"EmailAddress", type text}, {"EmailPromotion", Int64.Type}, {"Phone", type text}, {"PasswordHash", type text}, {"PasswordSalt", type text}, {"AdditionalContactInfo", type text}, {"rowguid", type text}, {"ModifiedDate", type datetime}})
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(HumanResources_Employee,{"HumanResources.Employee(EmployeeID)", "HumanResources.Employee(ManagerID)", "HumanResources.EmployeeAddress", "HumanResources.EmployeeDepartmentHistory", "HumanResources.EmployeePayHistory", "HumanResources.JobCandidate", "Person.Contact", "Purchasing.PurchaseOrderHeader", "Sales.SalesPerson"}),
#"Merged Queries" = Table.NestedJoin(#"Removed Columns",{"ContactID"},Contacts,{"ContactID"},"Contacts",JoinKind.LeftOuter),
#"Expanded Contacts" = Table.ExpandTableColumn(#"Merged Queries", "Contacts", {"EmailAddress"}, {"EmailAddress"})
in
#"Expanded Contacts";
下面是一个更高级别的视图,其中显示了依赖关系。
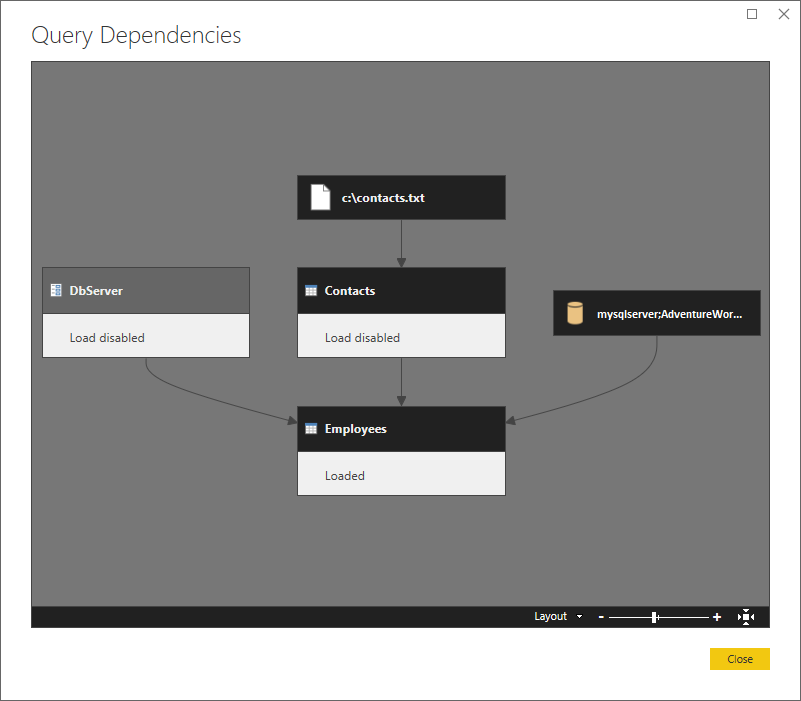
让我们分区
让我们仔细分析,包括图片中的步骤,然后开始浏览分区逻辑。 下面是三个查询的示意图,其中以绿色显示初始防火墙分区。 请注意:每个步骤都在其自己的分区中启动。
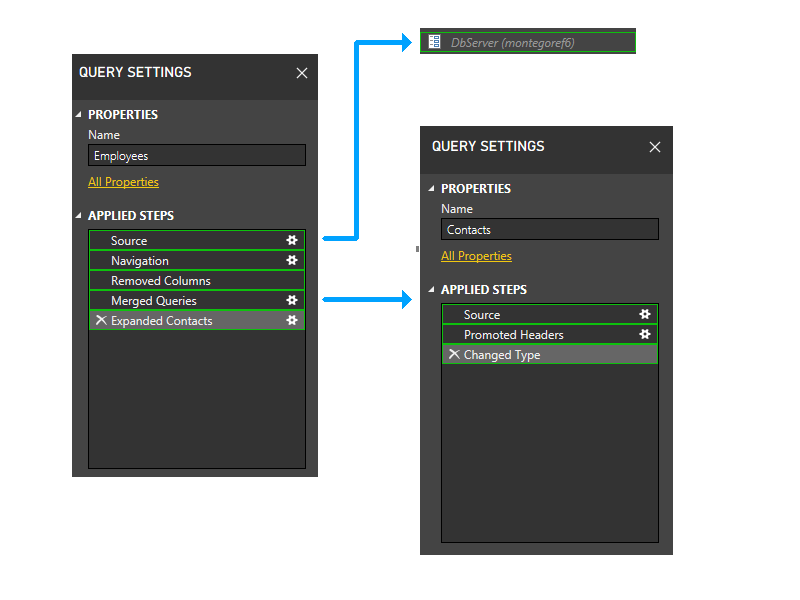
接下来,我们将调整参数分区。 因此,DbServer 将隐式包含在源分区中。
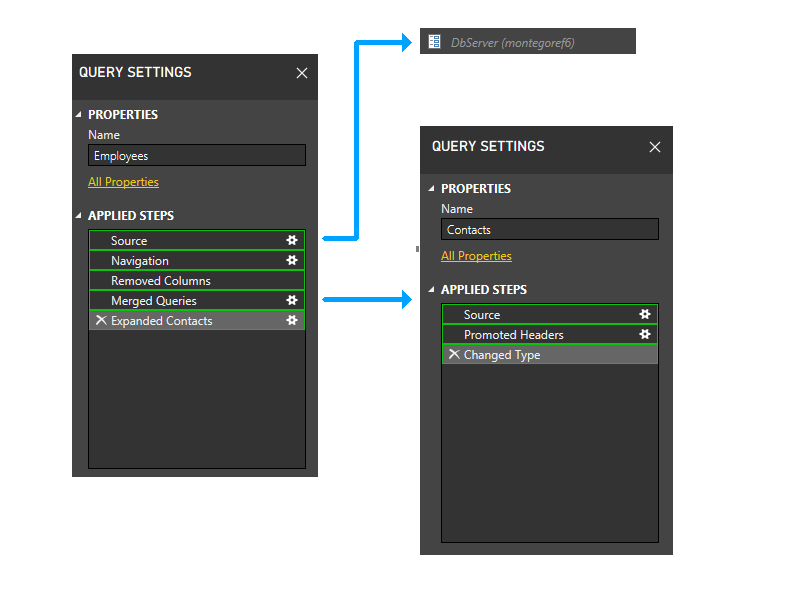
现在,我们执行静态分组。 这在单独的查询中保持了分区之间的分隔(例如,请注意:Employees 的最后两个步骤不会与 Contacts 的步骤分组),以及引用其他分区的分区(例如 Employee 的最后两个步骤)和不引用其他分区(例如 Employees 的前三个步骤)的分区之间的分离。
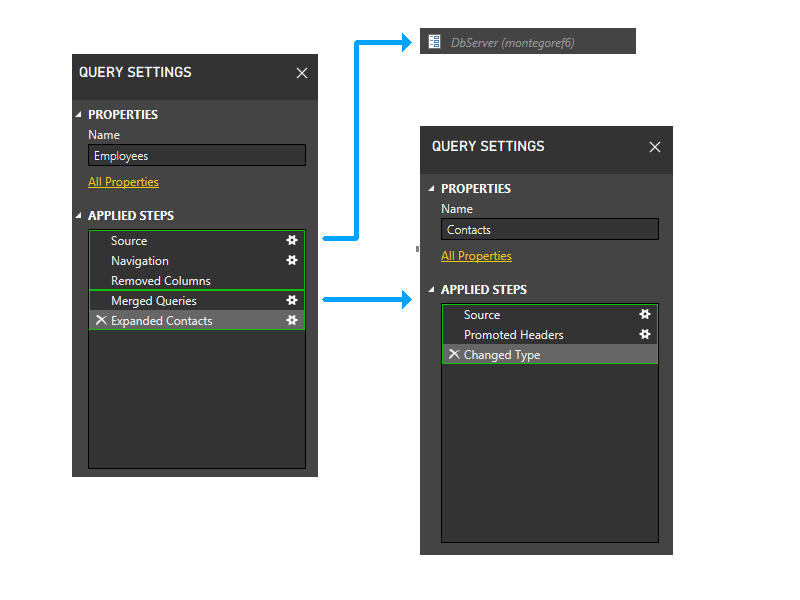
现在,我们进入动态阶段。 在此阶段中,将评估上述静态分区。 调整不访问任何数据源的分区。 然后对分区进行分组,以创建尽可能大的源分区。 然而,在这个示例场景中,所有剩余的分区都访问数据源,并且不能进行任何进一步的分组。 因此,我们示例中的分区在此阶段不会改变。
假设
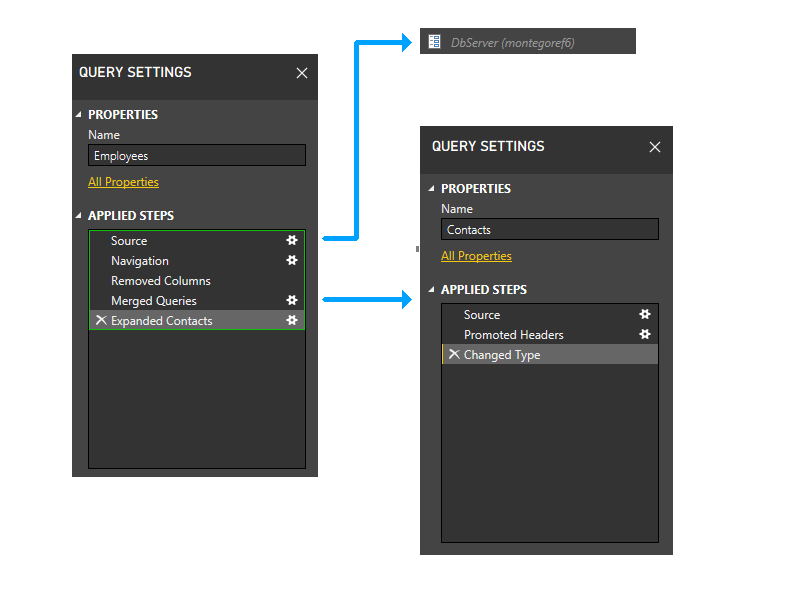
不过,为了便于说明,让我们看看如果 Contacts 查询不是来自文本文件,而是用 M 硬编码会发生什么(也许可以通过输入数据对话框)。
在本例中,Contacts 查询不会访问任何数据源。 因此,它将在动态阶段的第一部分被调整。
删除 Contacts 分区后,Employees 的最后两个步骤将不再引用任何分区,但包含 Employee 前三个步骤的分区除外。 因此,这两个分区将被分组。
生成的分区如下所示。
示例:将数据从一个数据源传递到另一个数据源
好了,抽象的解释说得够多了。 让我们来看一个常见的场景,在这个场景中您可能会遇到防火墙错误,以及解决这个错误的步骤。
想象一下,您想从 Northwind OData service 服务中查找一个公司名称,然后使用该公司名称执行必应搜索。
首先,创建 Company 查询以检索公司名称。
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
接下来,创建一个 Search 查询,该查询引用 Company,并将其传递给必应。
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
此时,您遇到了麻烦。 评估 Search 产生防火墙错误。
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
这是因为 Search 的源步骤引用数据源 (bing.com),还引用另一个查询/分区 (Company)。 这违反了上面提到的规则(“一个分区可以访问兼容的数据源,也可以引用其他分区,但不能同时访问两者”)。
怎么办? 一个选项是完全禁用防火墙(通过标记为忽略隐私级别并可能提高性能的隐私选项)。 但是,如果想让防火墙保持启用状态,该怎么办?
若要在不禁用防火墙的情况下解决此错误,您可以将 Company 和 Search 合并为单个查询,如下所示:
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
现在一切都发生在单个分区内。 假设这两个数据源的隐私级别是兼容的,那么防火墙现在就可以正常工作了,您将不会再收到错误。
完成
虽然关于这个主题还有很多可说的,但这篇介绍性文章已经足够长了。 希望文章能让您更好地理解防火墙,并在您将来遇到防火墙错误时帮助您理解和修复错误。