使用数据流创建维度模型的最佳做法
设计维度模型是可以使用数据流执行的最常见任务之一。 本文重点介绍了使用数据流创建维度模型的一些最佳做法。
临时数据流
任何数据集成系统中的一个关键点是减少源操作系统的读取次数。 在传统的数据集成体系结构中,通过创建名为 暂存数据库的新数据库来完成此缩减。 暂存数据库的目的是定期将数据从数据源 as-is 加载到临时数据库中。
然后,其余的数据集成将使用暂存数据库作为进一步转换的源,并将其转换为维度模型结构。
我们建议您使用数据流来遵循相同的方法。 创建一组数据流,负责仅从源系统加载数据 as-is(仅针对所需的表)。 然后,结果存储在数据流的存储结构中(Azure Data Lake Storage 或 Dataverse)。 此次更改确保了源系统的读取操作降至最低。
接下来,可以创建其他数据流,这些数据流从临时数据流中获取数据。 此方法的优点包括:
- 减少源系统中的读取操作数,并因此减少源系统上的负载。
- 如果使用本地数据源,则减少数据网关上的负载。
- 在源系统数据可能发生更改的情况下,保留一个中间副本用于数据校对。
- 使转换数据流与源无关。
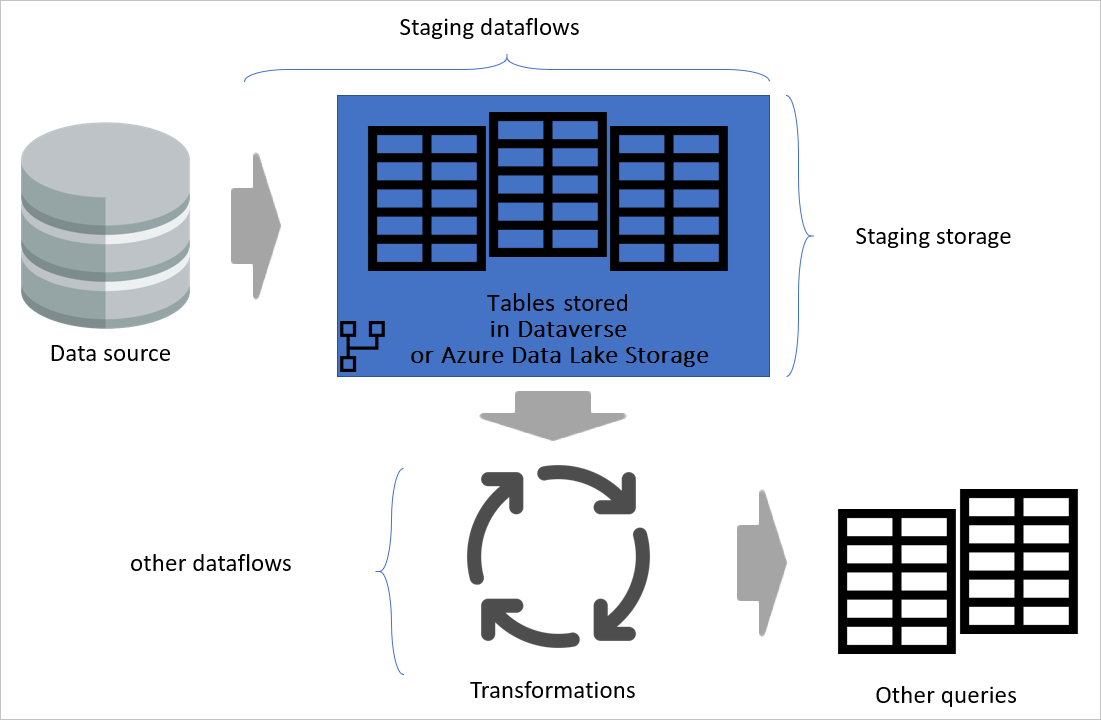
突出显示了临时数据流和临时存储,并显示如何通过临时数据流从数据源访问数据,以及这些表如何被存储在 Cadavers 或 Azure Data Lake Storage 中的图像。 随后,这些表将与其他数据流一起被转换,最终作为查询发送出去。
转换数据流
将转换数据流与暂存数据流分离后,转换将独立于源。 如果将源系统迁移到新系统,这种分离将有所帮助。 在这种情况下,只需更改过渡数据流。 由于转换数据流的数据完全来自临时数据流,因此转换过程中不太容易出现错误。
这种分离也有助于应对源系统连接速度缓慢的情况。 转换数据流无需等待很长时间,即可从源系统通过慢速连接获取记录。 过渡数据流已完成该部分,数据将准备好用于转换层。
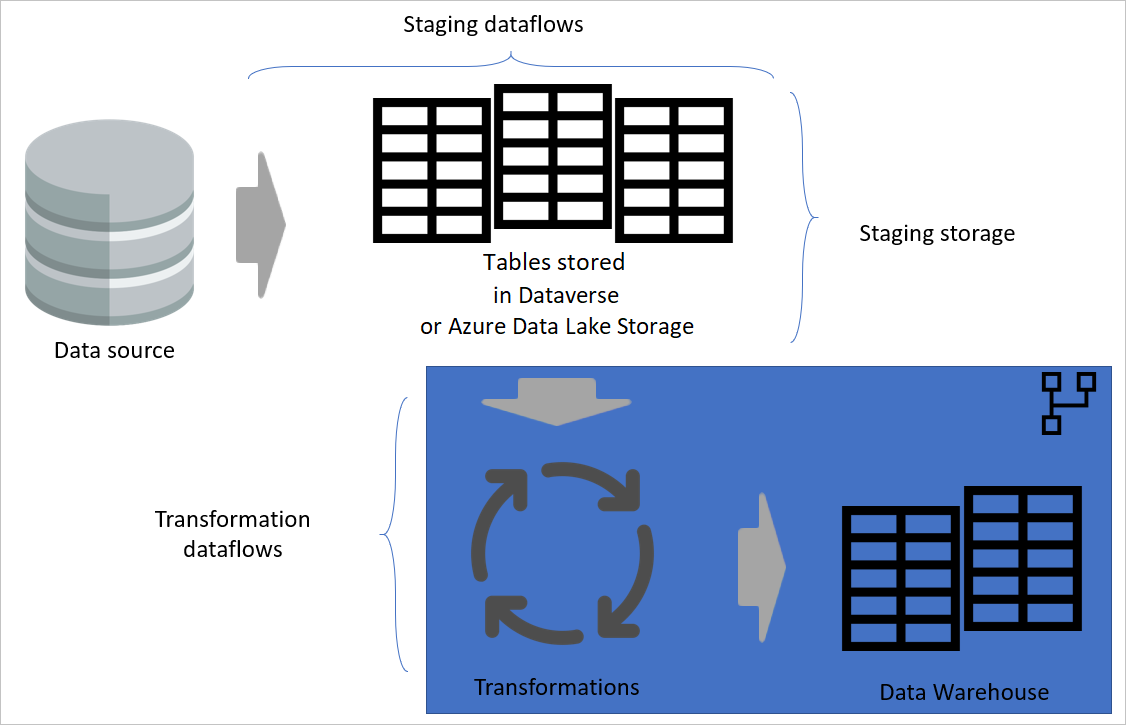
分层体系结构
分层体系结构是在单独的层中执行操作的体系结构。 过渡和转换数据流可以是多层数据流体系结构的两层。 尝试在多个层级中执行操作可确保所需的最低维护。 如果要更改某些内容,只需在位于它的层中对其进行更改。 其他所有层都应继续良好运作。
下图显示了数据流的多层体系结构,其中表随后在 Power BI 语义模型中使用。
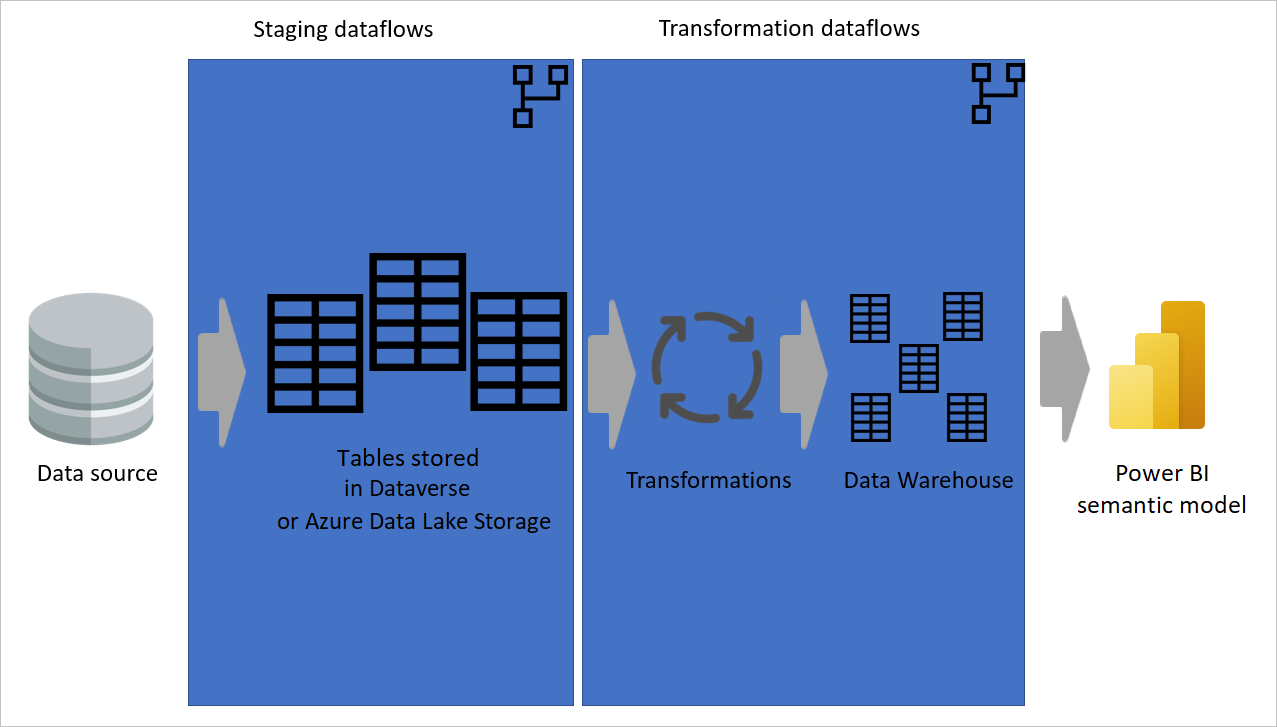
尽可能多地使用计算表
在另一个数据流中使用数据流的结果时,将使用计算表的概念,这意味着从“已处理和存储的”表获取数据。 数据流中可能发生同样的事情。 当需要从一个表中引用另一个表的数据时,可以使用计算表。 当你需要对多个表执行一组转换操作(被称为“常见转换”)时,使用计算表会非常有用。
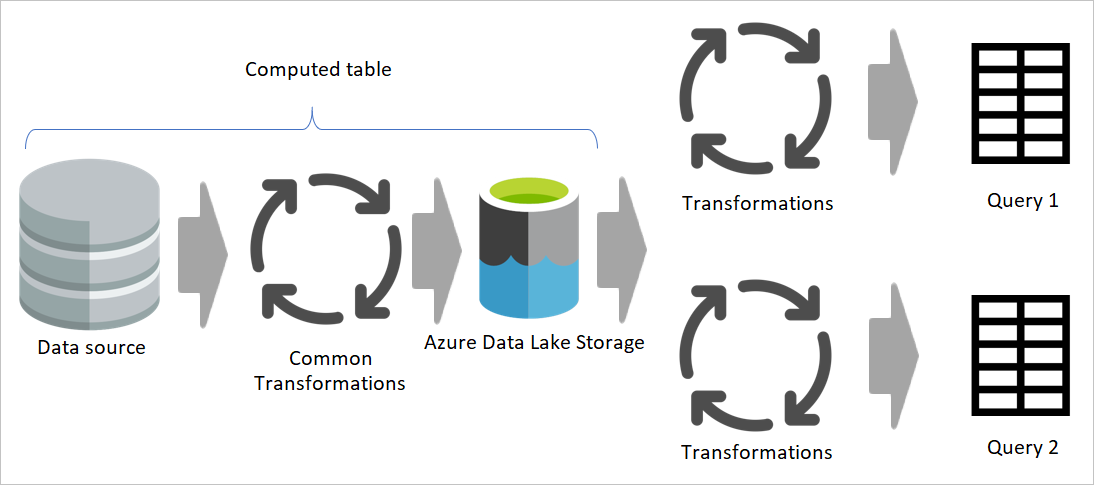
在上图中,计算表直接从源获取数据。 但是,在临时数据流和转换数据流的体系结构中,计算表的数据很可能来源于临时数据流。
生成星型架构
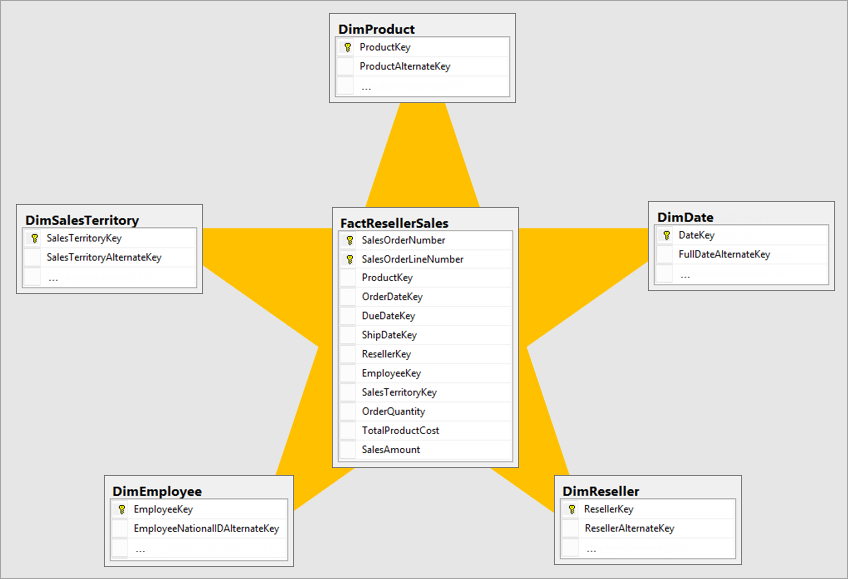
最佳维度模型是一种星型架构模型,它设计了维度和事实数据表,以最大程度地减少从模型查询数据的时间量,并使数据可视化工具易于理解。
将操作系统的相同布局中的数据引入 BI 系统并不理想。 应重新建模数据表。 某些表应采用维度表的形式,该表保留描述性信息。 某些表应采用事实数据表的形式,以保留可聚合数据。 构建事实表和维度表的最佳布局是星型模式。 详细信息:了解星型架构及其对 Power BI 的重要性
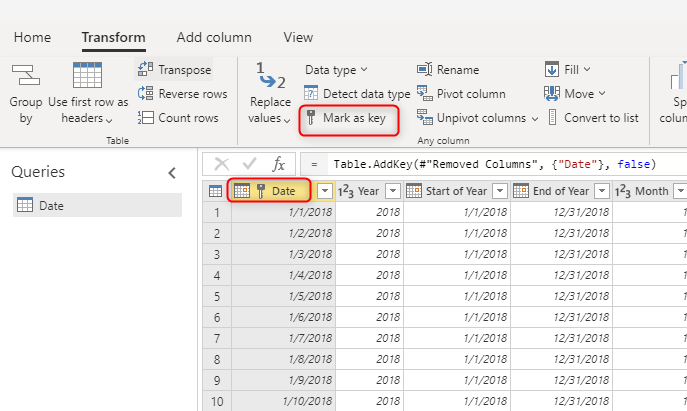
对维度使用唯一键值
生成维度表时,请确保为每个维度表都设置一个键。 此键可确保维度之间没有多对多(或换句话说为“弱”)关系。 可以通过应用某些转换来创建键,以确保列或列的组合在维度中返回唯一的行。 然后,可以将列组合标记为数据流中表中的键。
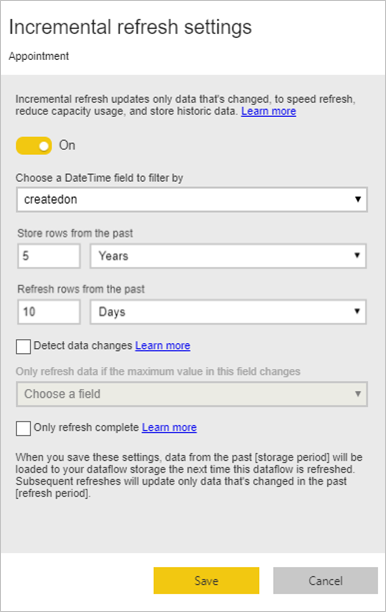
对大型事实数据表执行增量刷新
事实数据表始终是维度模型中的最大表。 建议减少这些表的传输行数。 如果你有非常大的事实数据表,请确保对该表使用增量刷新。 可以在 Power BI 语义模型中以及数据流表中完成增量刷新。
可以使用增量刷新来仅刷新部分数据(已更改的部分)。 有多种选项可用于选择要刷新的数据部分以及要保留哪些部分。 详细信息:使用 Power BI 数据流中的增量刷新
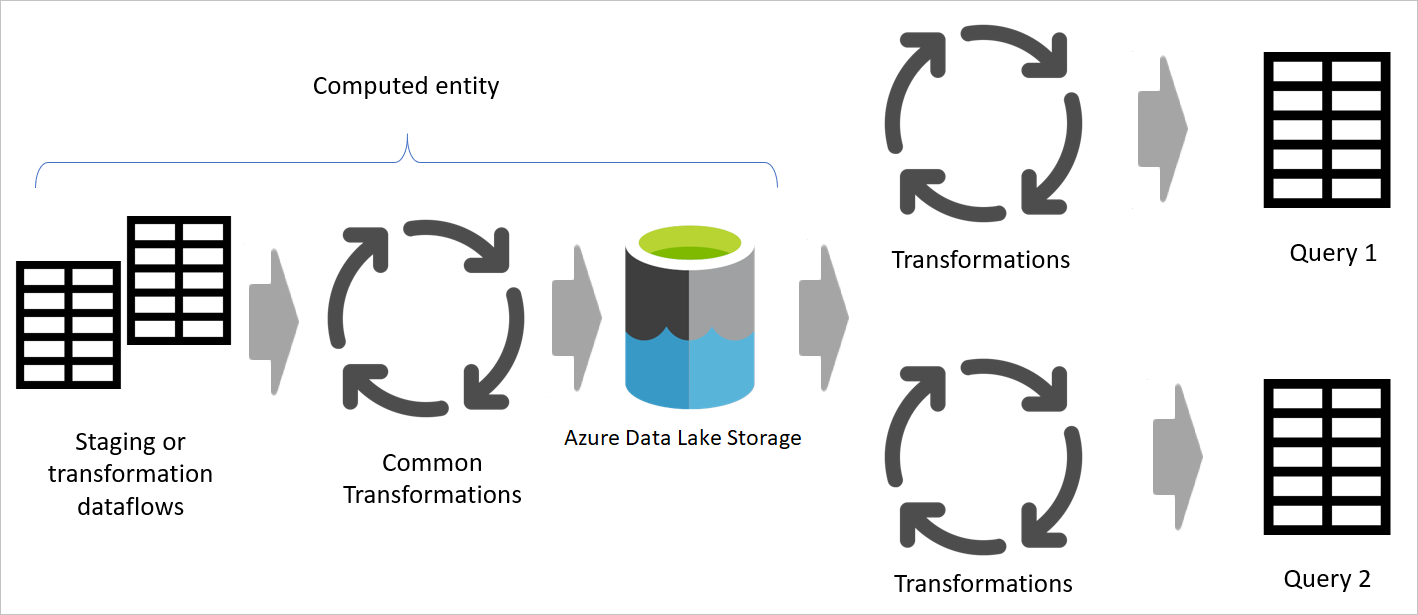
引用以创建维度表和事实数据表
在源系统中,通常有一个表,用于在数据仓库中生成事实数据表和维度表。 这些表是计算表的理想选择,并且也非常适合用于中间数据流。 该过程的常见部分(例如数据清理和删除额外的行和列)可以执行一次。 通过使用这些操作输出中的引用,您可以生成维度表和事实表。 此方法将使用计算表进行常见转换。