设计和开发复杂数据流的最佳做法
如果正在开发的数据流越来越大、越来越复杂,则可以执行以下操作来改进原始设计。
将其分解为多个数据流
不要在一个数据流中执行所有操作。 单个复杂的数据流不仅使数据转换过程更长,也使得理解和重用数据流更加困难。 通过分离不同数据流中的表,甚至将一个表拆分为多个数据流,即可将数据流分解为多个数据流。 可以使用计算表或链接表的概念在一个数据流中生成转换的一部分,并在其他数据流中重复使用它。
将数据转换数据流与暂存/提取数据流分开
让某些数据流仅用于提取数据(即暂存数据流),而让其他数据流仅用于转换数据,这不仅有助于创建多层体系结构,还有助于降低数据流的复杂性。 某些步骤只从数据源中提取数据,例如获取数据、导航和数据类型更改。 通过将暂存数据流和转换数据流分开,可以简化数据流的开发。
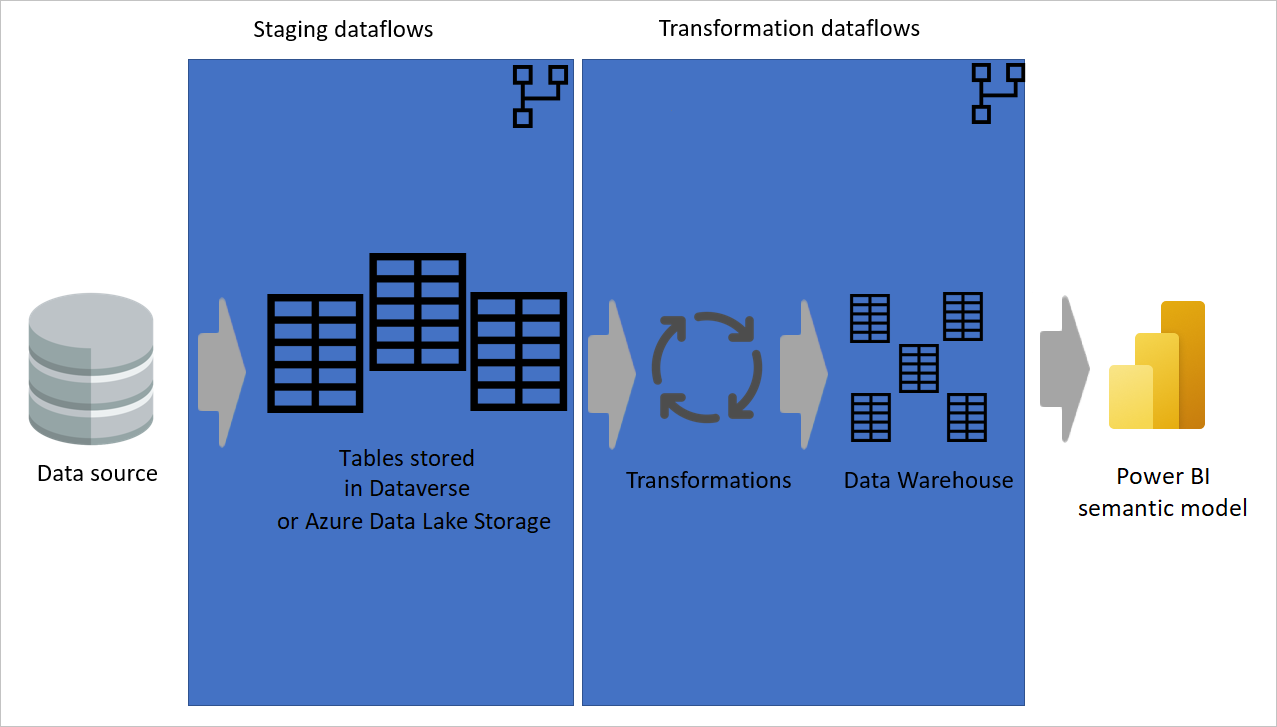
图像中显示的数据从数据源提取到暂存数据流,其中表存储在 Dataverse 或 Azure Data Lake 存储中。 然后,数据移动到转换数据流,其中数据进行转换并转换为数据仓库结构。 然后,数据将移动至语义模型。
使用自定义函数
在必须对来自不同源的多个查询执行一定数量的步骤的情况下,自定义函数非常有用。 可以通过 Power Query 编辑器中的图形界面或使用 M 脚本开发自定义函数。 可以根据需要在数据流中重复使用函数。
只有一个源代码版本的自定义函数有助于执行自定义函数,因此无需复制代码。 因此,维护 Power Query 转换逻辑和整个数据流要容易得多。 有关详细信息,请转到以下博客文章:自定义函数在 Power BI Desktop 中的变得简单。
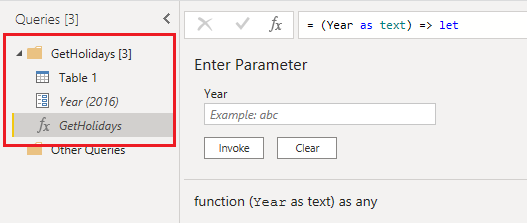
注意
有时你可能会收到一条通知,告知使用自定义函数刷新数据流需要高级容量。 你可以忽略此消息并重新打开数据流编辑器。 这通常可以解决问题,除非函数引用“已启用负载”查询。
将查询放入文件夹中
将文件夹用于查询有助于将相关查询组合在一起。 开发数据流时,请多花点时间在文件夹中排列有意义的查询。 将来,你可以使用此方法更轻松地查找查询,并且维护代码非常简单。
使用计算表
计算表不仅使数据流更易于理解,而且还可提高性能。 在使用计算表时,从中引用的其他表将从“已处理和存储的”表中获取数据。 转换更简单、更快。
利用增强型计算引擎
对于在 Power BI 管理门户中开发的数据流,在执行其他类型的转换之前,先在计算表中执行联接和筛选转换,确保使用增强型计算引擎。
将多个步骤分解成多个查询
很难跟踪一个表中的大量步骤。 相反,应将大量步骤分解成多个表。 你可以对其他查询使用启用加载并禁用它们(如果它们是中间查询),并且仅通过数据流加载最终表。 如果有多个查询且每个查询中的步骤较小,则使用依赖项关系图并跟踪每个查询进行进一步调查(而不是在一个查询中探究数百个步骤)会更容易。
添加查询和步骤的属性
文档是获得轻松维护的代码的关键。 在 Power Query 中,你可以将属性添加到表以及步骤中。 将鼠标悬停在该查询或步骤上时,在属性中添加的文本会显示为工具提示。 将来,本文档可帮助你维护模型。 通过一目了然地查看表或步骤,你可以了解那里发生的事情,而不是重新思考和记住你在该步骤中所做的操作。
确保容量位于同一区域
数据流目前不支持多个国家或地区。 高级容量必须与 Power BI 租户位于同一区域。
将本地源与云源分开
建议为每种源类型创建单独的数据流,例如本地、云、SQL Server、Spark 和 Dynamics 365。 按源类型分隔数据流有助于快速进行故障排除,并在刷新数据流时避免内部限制。
根据表所需的计划刷新来分隔数据流
如果某个销售交易表每小时在源系统中更新一次,并且每周更新一个产品映射表,请使用不同的数据刷新计划将这两个表分成两个数据流。
避免为同一工作区中的链接表计划刷新
如果经常被锁定在包含链接表的数据流之外,则可能是由数据流刷新期间锁定的同一工作区中的相应依赖数据流引起的。 此类锁定提供事务准确性,并确保两个数据流都成功刷新,但可能会阻止你进行编辑。
如果为链接的数据流设置了单独的计划,则可以不必刷新数据流,并且可能会阻止你编辑数据流。 解决此问题有两种建议:
- 不要在与源数据流相同的工作区中为链接数据流设置刷新计划。
- 如果要单独配置刷新计划并想要避免锁定行为,请将数据流移到单独的工作区中。