Power Query 查询参考
本文面向使用 Power BI Desktop 的数据建模者。 在定义引用其他查询的 Power Query 查询时,可以参考本文提供的指南。
我们来具体了解一下它的含义:当一个查询引用第二个查询时,就好像第二个查询中的步骤与第一个查询中的步骤组合在一起并在第一个查询中的步骤之前运行。
场景
来看看几个查询:Query1 从 Web 服务获取数据,并且被禁止加载。 Query2、Query3 和 Query4 均引用 Query1,并将它们的输出加载到数据模型中。
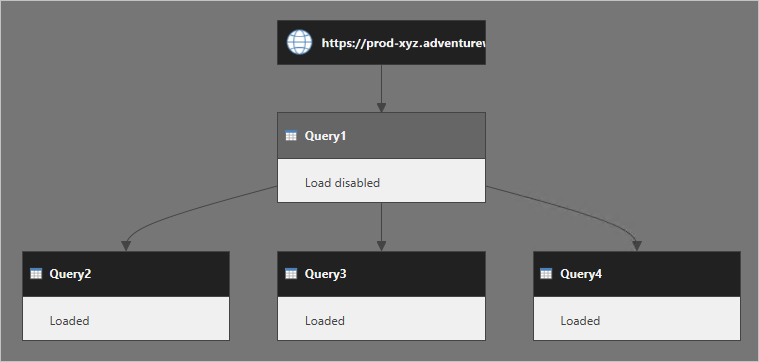
刷新数据模型时,通常会假定 Power Query 检索 Query1 结果,并将重用于引用的查询。 这种思维是不正确的。 事实上,Power Query 分别执行 Query2、Query3 和 Query4。
可以认为 Query2 中嵌入了 Query1 的步骤。 Query3 和 Query4 也是如此。 下图更清楚地说明了如何执行查询。
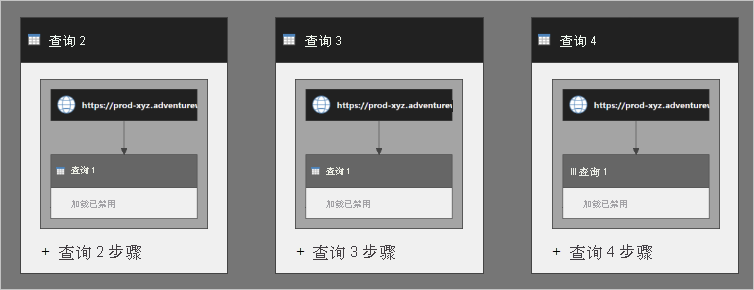
Query1 执行了三次。 多次执行可能会导致数据刷新速度变慢,并对数据源产生负面影响。
在 Query1 中使用 Table.Buffer 函数时,不会消除额外的数据检索。 此函数会将表缓冲到内存中,并且缓冲表只能在同一查询执行中使用。 因此,在此示例中,如果在执行 Query2 时缓冲 Query1,则在执行 Query3 和 Query4 时,将无法使用缓冲的数据。 它们会自行将数据缓冲两次。 (实际上,这种结果可能会使性能降低,因为每个引用查询都会缓冲该表。)
注意
Power Query 缓存体系结构很复杂,本文不作重点介绍。 Power Query 可以缓存从数据源检索的数据。 但是,当它执行查询时,它可能会多次从数据源检索数据。
建议
通常建议引用查询,以避免查询中逻辑的重复。 但是,如本文所述,这种设计方法可能会导致数据刷新速度变慢以及数据源过载。
建议改为创建数据流。 使用数据流可以缩短数据刷新时间,并减小对数据源的影响。
可以设计数据流来封装源数据和转换。 由于数据流是 Power BI 服务中的持久数据存储,因此数据检索速度很快。 因此,即使引用查询导致数据流的多个请求,也可以缩短数据刷新时间。
在此示例中,如果将 Query1 重新设计为数据流实体,那么 Query2、Query3 和 Query4 可以将其用作数据源。 通过这种设计,由 Query1 派生的实体将仅被评估一次。
相关内容
有关本文的详细信息,请参阅以下资源: