配置自动聚合
配置自动聚合时,需要为支持的 DirectQuery 语义模型启用训练功能,并配置一次或多次计划刷新。 在运行训练和刷新操作的多次迭代后,可返回到语义模型设置,对使用内存中聚合缓存的报表查询的百分比进行微调。 在完成这些步骤之前,请确保完全了解自动聚合中所述的功能和限制。
启用
必须具有语义模型所有者权限才能启用自动聚合。 工作区管理员可以接管模型所有者权限。
在语义模型设置中,展开“计划刷新和性能优化”。
将“自动聚合训练”切换为“开”。 如果切换开关灰显,请确保数据源凭据已配置且已登录。

在“刷新计划”中,指定刷新频率和时区。 如果“刷新计划”控件已禁用,请验证数据源配置,包括网关连接(若需要)和数据源凭据。
选择“添加其他时间”,然后指定一次或多次刷新。
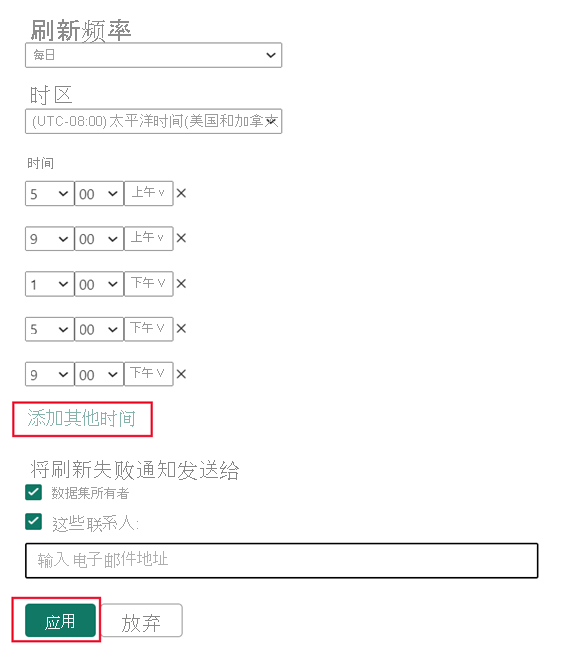
必须计划至少一次刷新。 所选频率的第一次刷新将包括训练操作和刷新操作,刷新会将新的和更新的聚合加载到内存中缓存。 计划更多刷新,确保命中聚合缓存的报表查询获得与后端数据源最同步的结果。 有关详细信息,请参阅刷新操作。
选择“应用”。
按需训练和刷新
所选频率的第一次计划刷新操作包括训练操作。 如果该训练操作未在 60 分钟的时间限制内完成,后续刷新操作将不会加载或更新缓存中的聚合。 完成所选频率的第一次刷新操作后,下一次训练操作才会运行。
在这种情况下,可以手动运行一个或多个按需训练和刷新操作,才能彻底完成缓存中的训练和加载或刷新聚合。 例如,检查刷新历史记录时,如果某天(频率)的第一次计划训练和刷新操作未在时间限制内完成,并且你不想等待第二天的计划刷新(包括要运行的训练操作),可以运行一个或多个按需训练和刷新操作,来完全处理数据查询日志(训练)并将聚合加载到缓存(刷新)。
若要运行按需训练和刷新操作,请选择“立即训练和刷新”。 请务必关注刷新历史记录,确保按需训练操作成功完成。 如果没有,请在训练成功完成之前运行其他训练和刷新操作,并在缓存中加载或刷新聚合。
对于微调报表查询(将使用内存中缓存中的聚合)百分比,运行“立即训练和刷新”很有用。 通过运行按需立即训练和刷新操作,可以更快地确定新的百分比设置是否允许训练操作在时间限制内完成。
记住,无论是计划还是按需,对于数据源和 Power BI 来说,训练和刷新操作都会使用大量进程和资源。 请选择资源受影响最小的时间。
微调
用户定义的聚合表和系统生成的聚合表都是模型的一部分,会影响模型大小,并受现有 Power BI 模型大小限制的约束。 聚合处理还会消耗资源并影响模型刷新持续时间。 最佳配置是达到一种平衡,既为最常用的报表查询提供来自内存中聚合缓存的预聚合结果,同时允许离群值查询和即席查询更慢得出结果来换取更快的训练和刷新时间,并减轻系统资源的负担。
调整百分比
默认情况下,用于确定将使用内存中缓存聚合的报表查询百分比的聚合缓存设置为 75%。 增加百分比意味着更多的报表查询排名更靠前,因此,这些查询的聚合包含在内存中聚合缓存内。 虽然更高的百分比可能意味着通过内存中缓存应答的查询更多,但也可能意味着训练和刷新时间更长。 另一方面,将百分比调低可能意味着训练和刷新时间更短,资源利用率较低,但报表可视化效果性能可能会降低,因为这些报表查询此时必须往返数据源,内存中聚合缓存应答的查询更少。
系统必须先知道最常用的报表查询模式,才能确定在缓存中要包含的最佳聚合。 在调整将使用聚合缓存的查询百分比之前,请确保能够完成训练/刷新操作的多次迭代。 这使训练算法有时间在更大的时间范围内分析报表查询并相应地进行自我调整。 例如,如果已计划每日频率的刷新,可能需要等待一整周。 一周中某几天的用户报告模式可以与其他日期不同。
调整百分比
在语义模型设置中,展开“计划刷新和性能优化”。
在“查询覆盖率”中,使用“调整将使用聚合缓存的查询百分比”滑块,将百分比增加或减小到所需的值。 调整百分比时,“查询性能影响”提升图提供估计的查询响应时间。
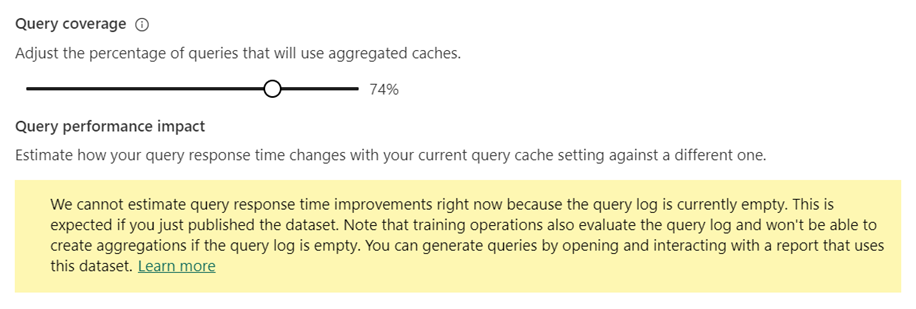
选择“立即训练和刷新”或“应用”。
估计查询性能影响
“查询性能影响”提升图以将使用缓存聚合的查询百分比的函数形式提供估计的报表查询运行时间。 此图中的所有指标最初显示为 0.0,至少执行了一个训练/刷新操作后才会发生变化。 在初始训练/刷新操作之后,此图可以帮助确定调整使用内存中聚合缓存的查询百分比是否可进一步改善查询响应。
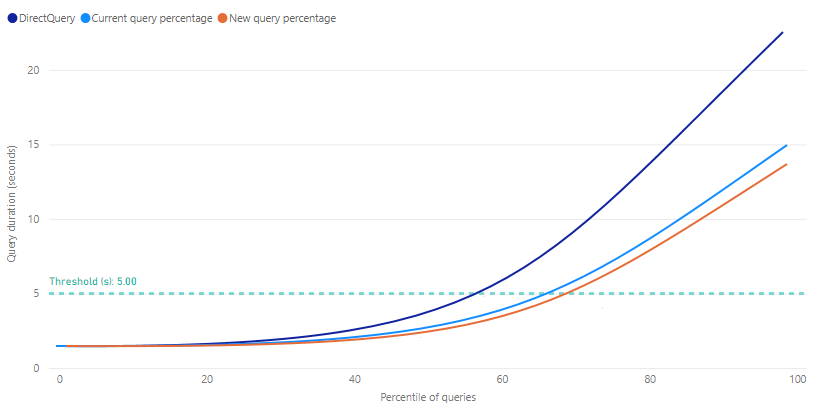
阈值在提升图上显示为一条标记线,指示报表的目标查询响应时间。 然后,可微调将使用聚合缓存的查询百分比,以确定满足所需阈值的新的查询百分比。
指标
DirectQuery - 使用 DirectQuery 向数据源发送并从其返回的报表查询的估计持续时间(以秒为单位)。 内存中聚合缓存无法应答的查询通常在此估计范围内。
当前查询百分比 - 根据最新训练/刷新操作的百分比设置,从内存中聚合缓存应答的报表查询的估计持续时间(以秒为单位)。
新查询百分比 - 从内存中聚合缓存应答新选定百分比的报表查询的估计持续时间(以秒为单位)。 移动百分比滑块时,此指标反映可能的变化。
禁用
必须具有模型所有者权限才能禁用自动聚合。 工作区管理员可以接管模型所有者权限。
若要禁用,请将“自动聚合训练”切换为“关”。
当你禁用训练时,系统会显示删除自动聚合表的选项。
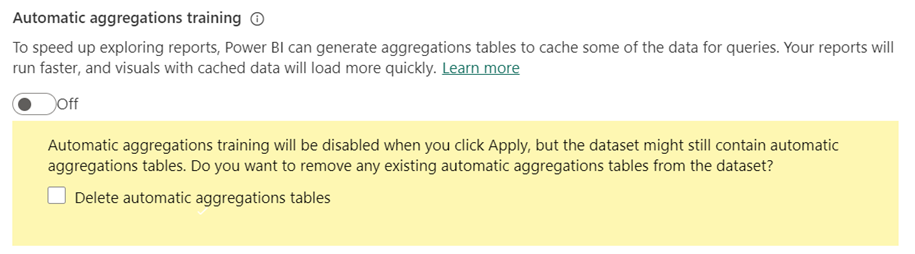
如果选择“不”删除现有的自动聚合表,表将保留在模型中,并继续刷新。 但由于训练已禁用,不会向其添加新聚合。 如果可能,Power BI 将继续使用现有表来获取聚合的查询结果。
如果选择删除表,模型会还原到其原始状态,没有任何自动聚合。
选择“应用”。