使用和监视指标
报表作者和数据科学家可以使用这些指标的方法。 它们的方法可确保创建者一致地在其组织中使用最准确且受信任的 KPI,旨在重复使用和广泛分发。 基于这些指标生成的报表受益于更高的数据质量,因为它们使用标准化和验证的 KPI。 数据科学家现在可以将这些可靠的指标直接合并到复杂的模型中,而无需反向工程数据。 通过 Sempy 集成,可以轻松访问和重用 Power BI 语义模型中定义的指标。
本文介绍如何在报表和笔记本中使用指标。 此外,如何确保组织中使用准确且受信任的 KPI 提高数据质量并简化集成到复杂模型中。
先决条件
若要创建和管理指标集,必须:
- 拥有 Power BI 按用户付费(PPU)/高级版许可证,用于在标准工作区中创作和共享指标。
- 在 Fabric 容量中工作。
- 至少位于工作区的“参与者”角色中。 详细了解工作区中的角色。
- 具有语义模型的生成权限。
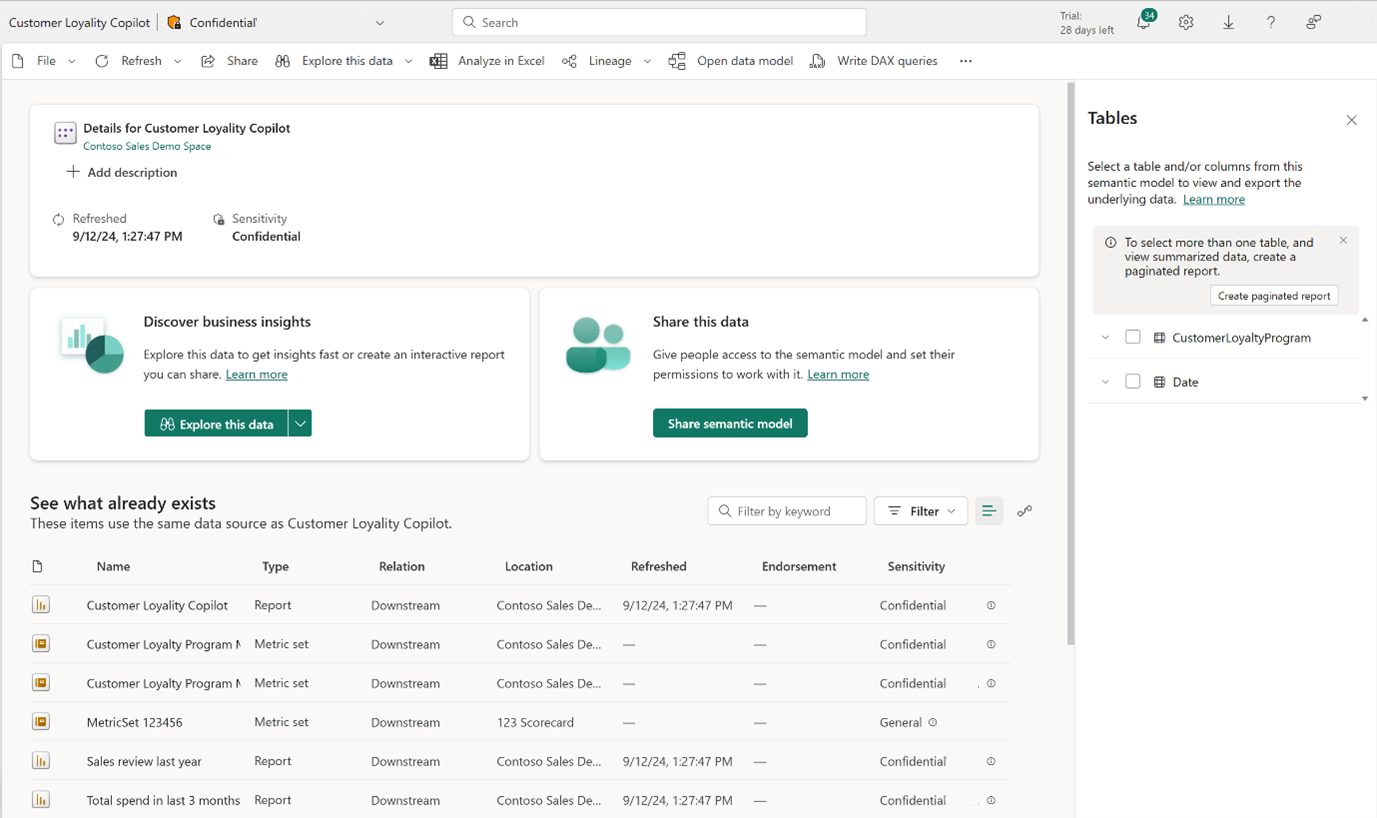
在报表中使用
若要在报表中使用,请执行以下操作:
选择 “使用指标 ”下拉列表
选择 在报表中使用
添加数据源并生成报表解决方案
注意
对于所有报表创作方案,连接到指标当前会将整个语义模型引入数据窗格。 将来,数据窗格将仅显示指标及其相关维度。
在笔记本中使用
在 Power BI 外部使用数据是指标层的强大体验。 使用指标通过 SemPy + 语义链接生成代码片段。 使用此代码片段可以在 Notebooks 或其他 Python 环境中使用该指标。
- 选择 “使用指标”下拉列表。
- 选择 将代码复制到笔记本。
- 复制提供的代码片段。
- 导航到新的或现有的笔记本。
- 将代码片段粘贴到单元格中。
- 包括包含特定维度的 groupby 新增功能(可选步骤)。
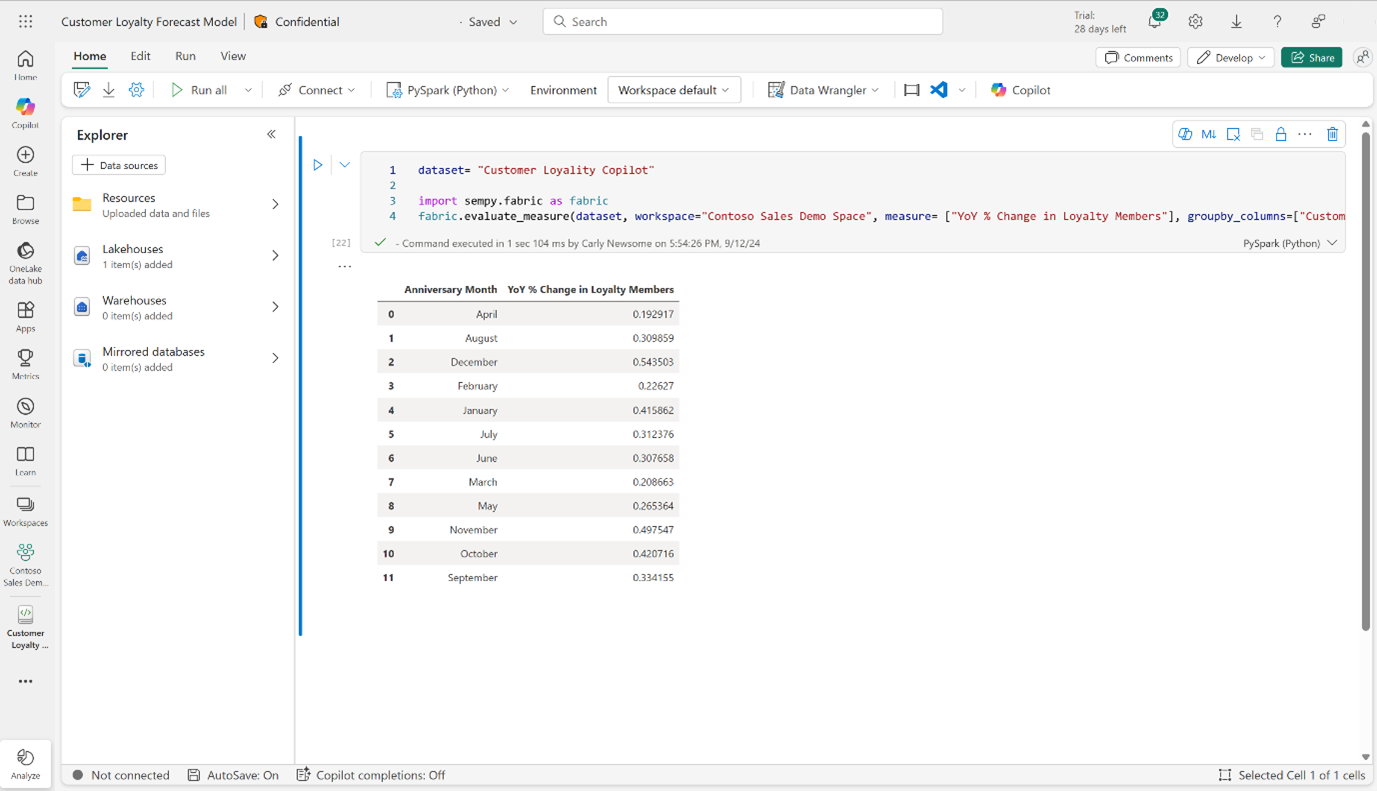
- 运行单元格并生成数据帧。
可以将这些数据保存回 Lakehouse,以便数据在 Power BI 外部可访问。
与 API 一起使用
指标集是 Fabric 项目,因此可以使用 Fabric 项目的公共 API。 API 使用指标集元数据。 但是,指标集由单个指标组成,这些指标不能通过公共构造 API 进行访问。 有关详细信息,请阅读 Microsoft Fabric REST API 参考。
若要通过 API 使用指标数据,可以使用语义链接并使用 SemPy,后者是简化语义数据的 Python 库。 可以使用使用 API 元素的 SemPy 连接到支持指标的 Power BI 度量值。 可以在指标详细信息页的笔记本部分中访问预生成的代码片段。 有关详细信息,请参阅 “在笔记本 中使用”了解详细信息。
了解世系
在 Power BI 中,世系视图对于创建者至关重要。 世系视图提供数据流的可见性、支持影响分析、帮助进行故障排除、强制实施数据管理、优化性能、增强协作并提供文档。 这种全面理解对于维护数据驱动项目的准确性、效率和有效性至关重要。
指标集显示在工作区世系视图和数据世系视图中:
- 工作区世系视图:重点介绍特定 Power BI 工作区中的项之间的关系,帮助用户了解不同组件之间的互连方式。
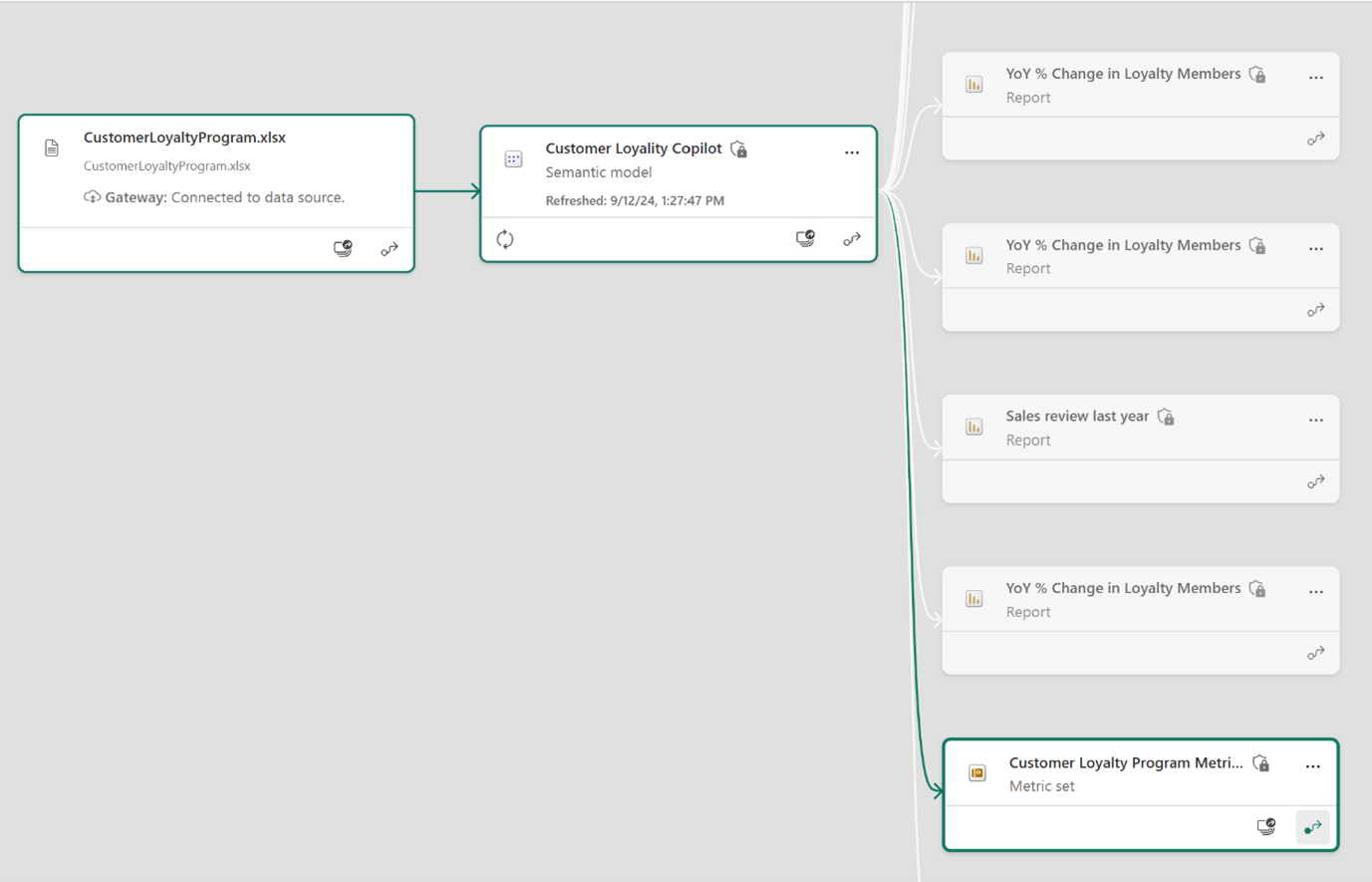
- 数据世系视图:提供一个端到端视图,说明如何在报表和仪表板中生成、转换和使用数据,涵盖整个数据生命周期。
创建者可以通过几种其他方法了解指标的世系和使用情况:
- 使用情况部分:用户还可以利用指标页的“使用情况”部分,该部分链接到详细信息区域中的“使用”部分。 本部分显示指标的特定下游应用程序。 例如,如果指标(或其基础度量值)用于 10 个报表,则所有 10 个报表都将显示在此表中。

- 语义模型的详细信息页:指标集项目显示在 “查看特定语义模型已存在 的内容”表中(如果指标使用位于该模型中的度量值)。