准备流程和数据
在您可以有效地使用 Power Automate 中的流程挖掘功能之前,您需要了解:
- 数据要求。
- 从您的应用程序的哪个位置获取日志数据。
- 如何连接到数据源。
以下是一个有关如何上传数据以用于流程挖掘功能的简短视频:
数据要求
事件日志和活动日志是存储在您的记录系统中的表,这些表记录了事件或活动发生的时间。 例如,您在客户关系管理 (CRM) 应用中执行的活动在 CRM 应用中保存为事件日志。 要让流程挖掘分析事件日志,需要下列字段:
案例 ID
案例 ID 应该代表您的流程的一个实例,通常是流程所作用的对象。 它可以是用于住院登记流程的“患者 ID”、用于订单提交流程的“订单 ID”或用于审批流程的“请求 ID”。 日志中的所有活动都必须存在此 ID。
活动名称
活动是流程的步骤,活动名称描述每个步骤。 在典型的审批流程中,活动名称可能是“submit request”、“request approved”、“request rejected”和“revise request”。
开始时间戳和结束时间戳
时间戳指示事件或活动发生的确切时间。 事件日志只有一个时间戳。 这指示事件或活动在系统中发生的时间。 活动日志有两个时间戳:开始时间戳和结束时间戳。 这些指示每个事件或活动的开始和结束。
您还可以通过获取可选的属性类型来扩展您的分析:
资源
执行特定事件的人力或技术资源。
事件级别属性
附加分析属性,每个事件具有不同的值,例如,执行活动的部门。
案例级别属性(第一个事件)
案例级属性是一个附加属性,从分析的角度来看,每个案例只有一个值(例如,以美元表示的发票金额)。 但是,要接收的事件日志不一定要符合一致性,因为事件日志中所有事件的特定属性值都相同。 例如,当使用增量数据刷新时,可能无法确保。 Power Automate Process Mining 按原样接收数据,存储事件日志中提供的所有值,但使用所谓的案例级属性解读机制来处理案例级属性。
换言之,每当属性用于需要事件级值(例如,事件级别筛选)的特定功能时,产品都会使用事件级值。 每当需要案例级值时(例如,案例级筛选、根本原因分析),则会使用解读的值,该值取自案例中按时间顺序排列的第一个事件。
案例级别属性(最后一个事件)
与案例级属性(第一个事件)相同,但在案例级解读时,该值取自案例中按时间顺序排列的最后一个事件。
每个事件的财务状况
固定成本/收入/数字值,根据执行的活动而变化,例如,快递服务费用。 财务值计算为每个事件财务值的总和(平均值、最小值、最大值)。
每案例财务(第一个事件)
每案例财务属性是一个附加的数字属性,从分析的角度来看,每个案例只有一个值(例如,以美元表示的发票金额)。 但是,要接收的事件日志不一定要符合一致性,因为事件日志中所有事件的特定属性值都相同。 例如,当使用增量数据刷新时,可能无法确保。 Power Automate Process Mining 按原样接收数据,存储事件日志中提供的所有值。 但是,它使用所谓的案例级属性解读机制来处理案例级属性。
换言之,每当属性用于需要事件级值(例如,事件级别筛选)的特定功能时,产品都会使用事件级值。 每当需要案例级值时(例如,案例级筛选、根本原因分析),则会使用解读的值,该值取自案例中按时间顺序排列的第一个事件。
每案例财务(最后一个事件)
与每案例财务(第一个事件)相同,但在案例级解读时,该值取自案例中按时间顺序排列的最后一个事件。
从您的应用程序的哪个位置获取日志数据
流程挖掘功能需要事件日志数据来执行流程挖掘。 虽然应用程序数据库中存在的很多表都包含数据的当前状态,但它们可能不包含所发生事件的历史记录,这是必需的事件日志格式。 幸运的是,在许多大型应用程序中,这种历史记录或日志通常存储在特定的表中。 例如,很多 Dynamics 应用程序将此记录保留在活动表中。 其他应用程序,如 SAP 或 Salesforce,虽然有类似的概念,但名称可能不同。
在这些记录历史记录的表中,数据结构可能很复杂。 您可能需要将日志表与应用程序数据库中的其他表联接以获取特定的 ID 或名称。 此外,并非您感兴趣的所有事件都会被记录。 您可能需要确定应该保留或过滤掉哪些事件。如果您需要帮助,您应该联系管理此应用程序的 IT 团队以了解更多信息。
连接到数据源
直接连接到数据库的好处是让流程报表与来自数据源的最新数据保持同步。
Power Query 支持多种为流程挖掘功能提供从相应数据源连接和导入数据的方法的连接器。 常见的连接器包括文本/CSV、Microsoft Dataverse 和 SQL Server 数据库。 如果您使用的是 SAP 或 Salesforce 等应用程序,您或许能够直接通过其连接器连接到这些数据源。 有关支持的连接器及其使用方法的信息,请转到 Power Query 中的连接器。
使用文本/CSV 连接器试用流程挖掘功能
不论您的数据源位于何处,使用文本/CSV 连接器试用流程挖掘功能都是一种简单方法。 您可能需要与数据库管理员一起将事件日志的小样本导出为 CSV 文件。 获得 CSV 文件后,您可以在数据源选择屏幕中使用以下步骤将文件导入流程挖掘功能中。
备注
您必须有 OneDrive for Business 才能使用文本/CSV 连接器。 如果您没有 OneDrive for Business,请考虑使用空白表而不是文本/CSV,如下面的步骤 3 所示。 您将无法在空白表中导入同样多的记录。
在流程挖掘主页上,通过选择在此处开始来创建一个流程。
输入流程名称,然后选择创建。
在选择数据源屏幕上,选择所有类别>文本/CSV。
选择浏览 OneDrive。 您可能需要进行身份验证。
选择右上角的上传图标,然后选择文件,上传您的事件日志。
上传您的事件日志,从列表中选择您的文件,然后选择打开使用该文件。
使用 Dataflow 连接器
不支持 Dataflow 连接器 Microsoft Power Platform。 现有数据流不能用作流程挖掘的 Power Automate 数据源。
使用 Dataverse 连接器
Microsoft Power Platform 中不支持 Dataverse 连接器。 您需要使用 OData 连接器进行连接,这需要更多的步骤。
确保您有权访问 Dataverse 环境。
您需要您尝试连接到的 Dataverse 环境的环境 URL。 它通常看起来像这样:
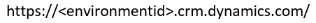
要了解如何查找您的 URL,请转到查找 Dataverse 环境 URL。
在 Power Query - 选择数据源屏幕上,选择 OData。
在 URL 文本框中,在 URL 末尾键入 api/data/v9.2,看起来像这样:
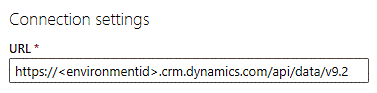
在连接凭据下,在身份验证种类字段中选择组织帐户。
选择登录并输入您的凭据。
选择下一步。
展开 OData 文件夹。 您应该会看到该环境中的所有 Dataverse 表。 例如,活动表称为 activitypointers。
选中要导入的表旁边的复选框,然后选择下一步。