对多语言文档执行 OCR
光学字符识别 (OCR) 使您能够从图像或屏幕中查找和提取文本。
虽然大多数情况要求您采用特定语言处理文本,但存在源是多语言的情况。
若要对这些源执行 OCR,请在相应的 OCR 操作中使用 Tesseract 引擎,然后在引擎设置中启用使用其他语言选项。
启用使用其他语言选项后,该操作将显示两个额外设置:语言缩写和语言数据路径字段。
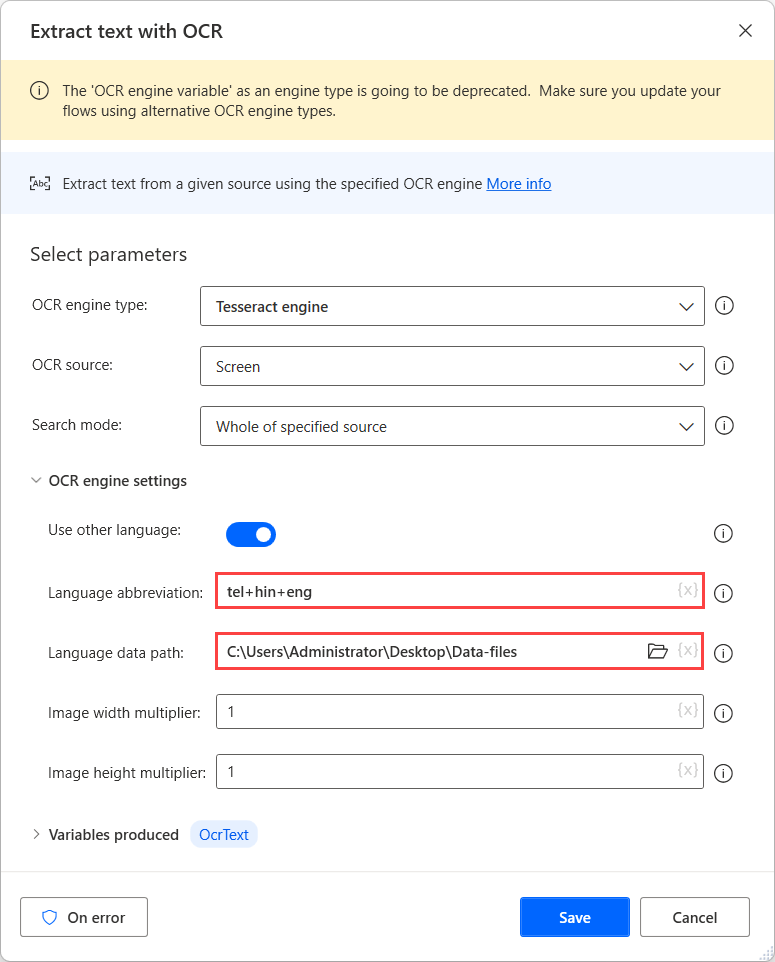
语言缩写字段指示要在 OCR 期间查找的语言的引擎。 语言数据路径字段包含用于训练 OCR 引擎的语言数据文件 (.traineddata)。
在为所需语言下载数据文件后,将其移动到常用文件夹以使其在同一路径下可用。
接下来,在语言数据路径字段中选择创建的文件夹,然后在语言缩写字段中填充相应的语言代码。 若要分隔语言代码,请使用加号字符 (+)。
备注
您可以在语言数据文件的源中查找所有可用的语言代码。 在下面的示例中,使用的代码表示泰卢固语、印地语和英语。