在 Microsoft Syntex 中训练结构化或任意格式的文档处理模型
按照 在 Syntex 中创建模型 中的说明在内容中心创建结构化或任意格式的文档处理模型。 或者,按照 在本地 SharePoint 网站上创建模型 中的说明在本地网站上创建模型。 然后,使用本文训练模型。

若要训练结构化或任意格式的文档处理模型,请执行以下步骤:
步骤 1:添加和分析文档
创建结构化或任意格式文档处理模型后, 将打开“选择要提取的信息 ”页。 此处列出了希望 AI 模型从文档中提取的所有信息,例如 “名称”、“ 地址”或 “金额”。
注意
查找要使用的示例文件时,请参阅 文档处理模型输入文档要求和优化提示。
首先定义要在 选择要提取的信息 页上指导模型进行提取的字段和表。 有关详细步骤,请参阅 定义要提取的字段和表。
可以创建希望模型处理的尽可能多的文档布局集合。 有关详细步骤,请参阅 按集合分组文档。
创建集合并为每个集合添加至少五个示例文件后,Syntex 上的 AI Builder 将检查上传的文档以检测字段和表。 此过程通常需要几秒钟。 分析完成后,可以继续标记文档。
步骤 2:标记字段和表
需要标记文档,以指导模型理解要提取的字段和表数据。 有关详细步骤,请参阅 标记文档。
步骤 3:训练和发布模型
创建和训练模型后,即已准备好发布模型并在 SharePoint 中使用它。 若要发布模型,请选择“ 发布”。 有关详细步骤,请参阅 训练和发布文档处理模型。
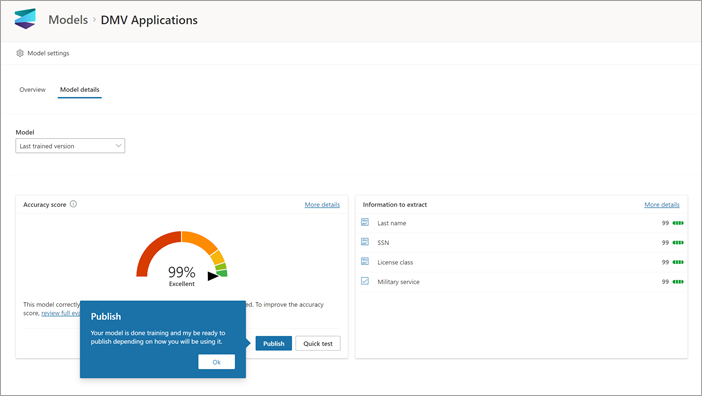
发布模型后,将转到模型主页。 然后,可以选择将模型应用于文档库。
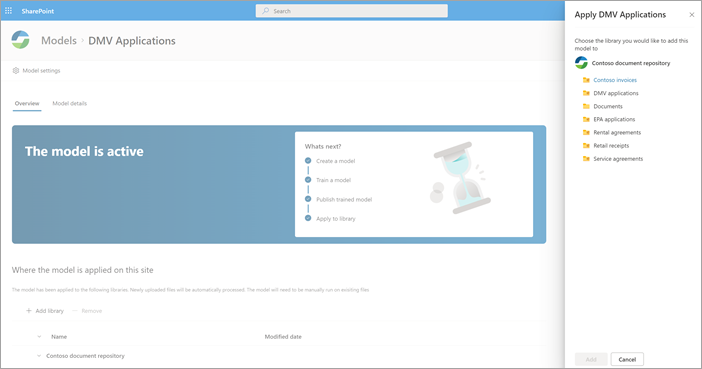
步骤 4:使用模型
在文档库模型视图中,请注意所选字段现在已显示为列。
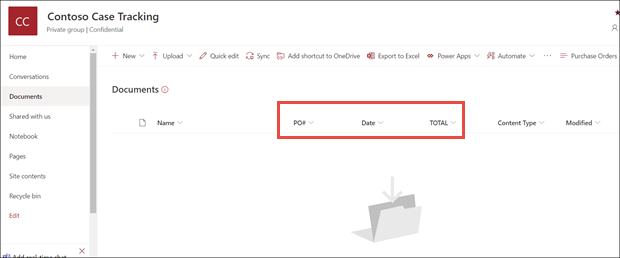
请注意,文档 旁边的信息链接指出表单处理模型已应用于此文档库。
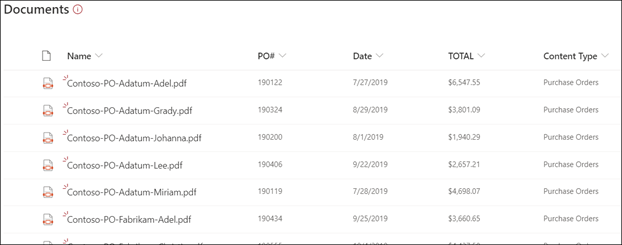
将文件上传到文档库。 任何由模型识别为其内容类型的文件都会在视图中列出文件,并在列中显示提取的数据。
注意
如果结构化或自由格式文档处理模型和非结构化文档处理模型应用于同一库,则使用非结构化文档处理模型和该模型的任何已训练提取程序对文件进行分类。 如果有任何与文档处理模型匹配的空列,则将使用这些提取的值填充这些列。
设置要处理的页面范围
对于此模型,可以指定以处理文件(而不是整个文件)的页面范围。 在“页面范围”设置中的“模型设置”下执行此操作。 默认情况下, “页面范围” 设置为空。 如果未提供页面范围,将处理整个文档。 有关详细信息,请参阅 设置页面范围以从特定页面中提取信息。
“分类日期”域
将任何自定义模型应用于文档库时, “分类日期” 字段将包含在库架构中。 默认情况下,此字段为空。 但是,当文档由模型处理和分类时,此字段将更新为完成日期时间戳。
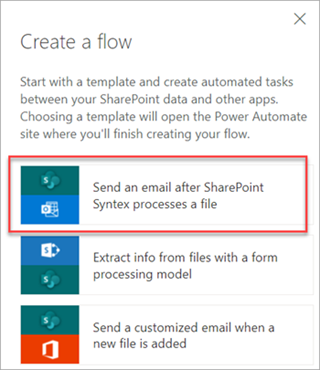
使用 分类日期标记模型时,可以使用 Syntex 处理文件后发送电子邮件 流来通知用户新文件已由 SharePoint 文档库中的模型处理和分类。
运行流:
选择一个文件,然后选择“ 集成>Power Automate>创建流”。
在 “创建流 ”面板中,选择“ Syntex 处理文件后发送电子邮件”。
使用流提取信息
重要
本节中的信息不适用于 Syntex 的最新版本。 它仅保留为在早期版本中创建的表单处理模型的引用。 在最新版本中,不再需要配置流来处理现有文件。
有两个流可用于处理已应用结构化或任意格式文档处理模型的库中的选定文件或文件批。
使用文档处理模型从图像或 PDF 文件中提取信息 - 用于通过运行文档处理模型从所选图像或 PDF 文件中提取文本。 一次支持单个选定文件,并且仅支持 PDF 文件和图像文件 (.png、.jpg 和.jpeg) 。 若要运行流,请选择一个文件,然后选择“ 自动>提取信息”。

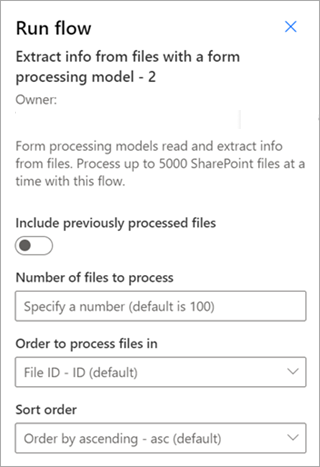
使用文档处理模型从文件中提取信息 - 与文档处理模型配合使用,从一批文件读取和提取信息。 一次最多处理 5,000 个 SharePoint 文件。 运行此流时,可以设置某些参数。 可以执行下列操作:
- 选择是否包括以前处理的文件, (默认值不包括以前处理的文件) 。
- 选择要处理的文件数 (默认值为 100 个文件) 。
- 指定文件处理顺序, (选项按文件 ID、文件名、文件创建时间或上次修改时间) 。
- 指定顺序 (升序或降序) 排序方式。
注意
使用文档处理模型从图像或 PDF 文件中提取信息流自动可用于与文档处理模型关联的库。 “从具有文档处理模型的文件中提取信息”流是必须添加到库(如果需要)的模板。