你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Overview of Responsible AI practices for Azure OpenAI models
Many of the Azure OpenAI models are generative AI models that have demonstrated improvements in advanced capabilities such as content and code generation, summarization, and search. With many of these improvements also come increased responsible AI challenges related to harmful content, manipulation, human-like behavior, privacy, and more. For more information about the capabilities, limitations and appropriate use cases for these models, please review the Transparency Note.
In addition to the Transparency Note, we have created technical recommendations and resources to help customers design, develop, deploy, and use AI systems that implement the Azure OpenAI models responsibly. Our recommendations are grounded in the Microsoft Responsible AI Standard, which sets policy requirements that our own engineering teams follow. Much of the content of the Standard follows a pattern, asking teams to Identify, Measure, and Mitigate potential harms, and plan for how to Operate the AI system as well. In alignment with those practices, these recommendations are organized into four stages:
- Identify : Identify and prioritize potential harms that could result from your AI system through iterative red-teaming, stress-testing, and analysis.
- Measure : Measure the frequency and severity of those harms by establishing clear metrics, creating measurement test sets, and completing iterative, systematic testing (both manual and automated).
- Mitigate : Mitigate harms by implementing tools and strategies such as prompt engineering and using our content filters. Repeat measurement to test effectiveness after implementing mitigations.
- Operate : Define and execute a deployment and operational readiness plan.
In addition to their correspondence to the Microsoft Responsible AI Standard, these stages correspond closely to the functions in the NIST AI Risk Management Framework.
Identify
Identifying potential harms that could occur in or be caused by an AI system is the first stage of the Responsible AI lifecycle. The earlier you begin to identify potential harms, the more effective you can be at mitigating the harms. When assessing potential harms, it is important to develop an understanding of the types of harms that could result from using the Azure OpenAI Service in your specific context(s). In this section, we provide recommendations and resources you can use to identify harms through an impact assessment, iterative red team testing, stress-testing, and analysis. Red teaming and stress-testing are approaches where a group of testers come together and intentionally probe a system to identify its limitations, risk surface, and vulnerabilities.
These steps have the goal of producing a prioritized list of potential harms for each specific scenario.
- Identify harms that are relevant for your specific model, application, and deployment scenario.
- Identify potential harms associated with the model and model capabilities (for example, GPT-3 model vs GPT-4 model) that you're using in your system. This is important to consider because each model has different capabilities, limitations, and risks, as described more fully in the sections above.
- Identify any other harms or increased scope of harm presented by the intended use of the system you're developing. Consider using a Responsible AI Impact Assessment to identify potential harms.
- For example, let's consider an AI system that summarizes text. Some uses of text generation are lower risk than others. For example, if the system is to be used in a healthcare domain for summarizing doctor's notes, the risk of harm arising from inaccuracies is higher than if the system is summarizing online articles.
- Prioritize harms based on elements of risk such as frequency and severity. Assess the level of risk for each harm and the likelihood of each risk occurring in order to prioritize the list of harms you've identified. Consider working with subject matter experts and risk managers within your organization and with relevant external stakeholders when appropriate.
- Conduct red team testing and stress testing starting with the highest priority harms, to develop a better understanding of whether and how the identified harms are actually occurring in your scenario, as well as to identify new harms you didn't initially anticipate.
- Share this information with relevant stakeholders using your organization's internal compliance processes.
At the end of this Identify stage, you should have a documented, prioritized list of harms. When new harms and new instances of harms emerge through further testing and use of the system, you can update and improve this list by following the above process again.
Measure
Once a list of prioritized harms has been identified, the next stage involves developing an approach for systematic measurement of each harm and conducting evaluations of the AI system. There are manual and automated approaches to measurement. We recommend you do both, starting with manual measurement.
Manual measurement is useful for:
- Measuring progress on a small set of priority issues. When mitigating specific harms, it's often most productive to keep manually checking progress against a small dataset until the harm is no longer observed before moving to automated measurement.
- Defining and reporting metrics until automated measurement is reliable enough to use alone.
- Spot-checking periodically to measure the quality of automatic measurement.
Automated measurement is useful for:
- Measuring at a large scale with increased coverage to provide more comprehensive results.
- Ongoing measurement to monitor for any regression as the system, usage, and mitigations evolve.
Below, we provide specific recommendations to measure your AI system for potential harms. We recommend you first complete this process manually and then develop a plan to automate the process:
Create inputs that are likely to produce each prioritized harm: Create measurement set(s) by generating many diverse examples of targeted inputs that are likely to produce each prioritized harm.
Generate System Outputs: Pass in the examples from the measurement sets as inputs to the system to generate system outputs. Document the outputs.
Evaluate System Outputs and Report Results to Relevant Stakeholders
- Define clear metric(s). For each intended use of your system, establish metrics that measure the frequency and degree of severity of each potentially harmful output. Create clear definitions to classify outputs that will be considered harmful or problematic in the context of your system and scenario, for each type of prioritized harm you identified.
- Assess the outputs against the clear metric definitions and record and quantify the occurrences of harmful outputs. Repeat the measurements periodically, to assess mitigations and monitor for any regression.
- Share this information with relevant stakeholders using your organization's internal compliance processes.
At the end of this measurement stage, you should have a defined measurement approach to benchmark how your system performs for each potential harm as well as an initial set of documented results. As you continue implementing and testing mitigations, the metrics and measurement sets should continue to be refined (for example, to add metrics for new harms that were initially unanticipated) and the results updated.
Mitigate
Mitigating harms presented by large language models such as the Azure OpenAI models requires an iterative, layered approach that includes experimentation and continual measurement. We recommend developing a mitigation plan that encompasses four layers of mitigations for the harms identified in the earlier stages of this process:
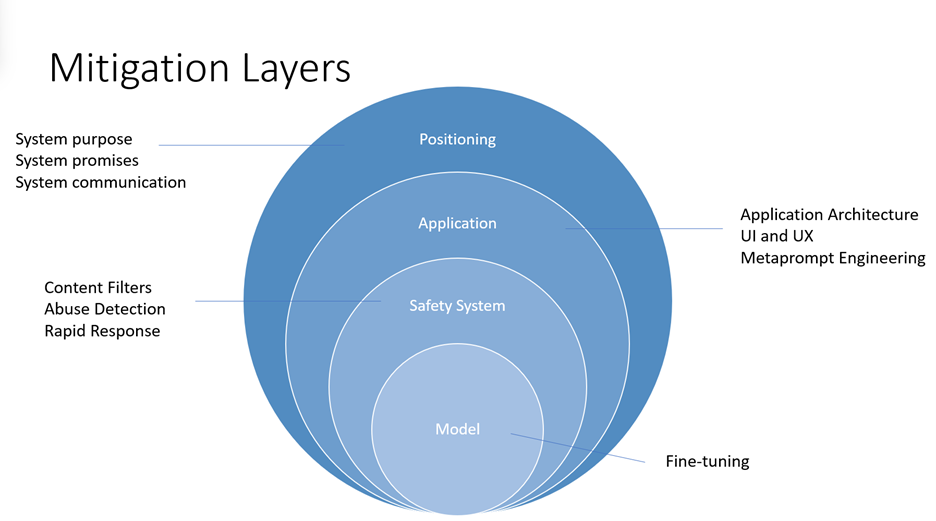
- At the model level, it's important to understand the model(s) you'll be using and what fine-tuning steps may have been taken by the model developers to align the model towards its intended uses and to reduce the risk of potentially harmful uses and outcomes.
- For example, for GPT-4, model developers have been able to use reinforcement learning methods as a responsible AI tool to better align the model towards the designers' intended goals.
- At the safety system level, you should understand the platform level mitigations that have been implemented, such as the Azure OpenAI content filters which help to block the output of harmful content.
- At the application level, application developers can implement metaprompt and user-centered design and user experience mitigations. Metaprompts are instructions provided to the model to guide its behavior; their use can make a critical difference in guiding the system to behave in accordance with your expectations. User-centered design and user experience (UX) interventions are also key mitigation tools to prevent misuse and overreliance on AI.
- At the positioning level, there are many ways to educate the people who will use or be affected by your system about its capabilities and limitations.
Below, we provide specific recommendations to implement mitigations at the different layers. Not all of these mitigations are appropriate for every scenario, and conversely, these mitigations may be insufficient for some scenarios. Give careful consideration to your scenario and the prioritized harms you identified, and as you implement mitigations, develop a process to measure and document their effectiveness for your system and scenario.
Model level Mitigations: Review and identify which Azure OpenAI base model is best suited for the system you're building and educate yourself about its capabilities, limitations, and any measures taken to reduce the risk of the potential harms you've identified. For example, if you're using GPT-4, in addition to reading this Transparency Note, you can review OpenAI's GPT-4 System Card explaining the safety challenges presented by the model and the safety processes that OpenAI adopted to prepare GPT-4 for deployment. It may be worth experimenting with different versions of the model(s) (including through red teaming and measuring) to see how the harms present differently.
Safety System Level Mitigations: Identify and evaluate the effectiveness of platform level solutions such as the Azure OpenAI content filters to help mitigate the potential harms that you have identified.
Application Level Mitigations: Prompt engineering, including metaprompt tuning, can be an effective mitigation for many different types of harm. Review and implement metaprompt (also called the "system message" or "system prompt") guidance and best practices documented here.
We recommend implementing the following user-centered design and user experience (UX) interventions, guidance, and best practices to guide users to use the system as intended and to prevent overreliance on the AI system:
- Review and edit interventions: Design the user experience (UX) to encourage people who use the system to review and edit the AI-generated outputs before accepting them (see HAX G9: Support efficient correction).
- Highlight potential inaccuracies in the AI-generated outputs (see HAX G2: Make clear how well the system can do what it can do), both when users first start using the system and at appropriate times during ongoing use. In the first run experience (FRE), notify users that AI-generated outputs may contain inaccuracies and that they should verify information. Throughout the experience, include reminders to check AI-generated output for potential inaccuracies, both overall and in relation to specific types of content the system may generate incorrectly. For example, if your measurement process has determined that your system has lower accuracy with numbers, mark numbers in generated outputs to alert the user and encourage them to check the numbers or seek external sources for verification.
- User responsibility. Remind people that they are accountable for the final content when they're reviewing AI-generated content. For example, when offering code suggestions, remind the developer to review and test suggestions before accepting.
- Disclose AI's role in the interaction. Make people aware that they are interacting with an AI system (as opposed to another human). Where appropriate, inform content consumers that content has been partly or fully generated by an AI model; such notices may be required by law or applicable best practices, and can reduce inappropriate reliance on AI-generated outputs and can help consumers use their own judgment about how to interpret and act on such content.
- Prevent the system from anthropomorphizing. AI models may output content containing opinions, emotive statements, or other formulations that could imply that they're human-like, that could be mistaken for a human identity, or that could mislead people to think that a system has certain capabilities when it doesn't. Implement mechanisms that reduce the risk of such outputs or incorporate disclosures to help prevent misinterpretation of outputs.
- Cite references and information sources. If your system generates content based on references sent to the model, clearly citing information sources helps people understand where the AI-generated content is coming from.
- Limit the length of inputs and outputs, where appropriate. Restricting input and output length can reduce the likelihood of producing undesirable content, misuse of the system beyond its intended uses, or other harmful or unintended uses.
- Structure inputs and/or system outputs. Use prompt engineering techniques within your application to structure inputs to the system to prevent open-ended responses. You can also limit outputs to be structured in certain formats or patterns. For example, if your system generates dialog for a fictional character in response to queries, limit the inputs so that people can only query for a predetermined set of concepts.
- Prepare pre-determined responses. There are certain queries to which a model may generate offensive, inappropriate, or otherwise harmful responses. When harmful or offensive queries or responses are detected, you can design your system to deliver a predetermined response to the user. Predetermined responses should be crafted thoughtfully. For example, the application can provide prewritten answers to questions such as "who/what are you?" to avoid having the system respond with anthropomorphized responses. You can also use predetermined responses for questions like, "What are your terms of use?" to direct people to the correct policy.
- Restrict automatic posting on social media. Limit how people can automate your product or service. For example, you may choose to prohibit automated posting of AI-generated content to external sites (including social media), or to prohibit the automated execution of generated code.
- Bot detection. Devise and implement a mechanism to prohibit users from building an API on top of your product.
Positioning Level Mitigations:
- Be appropriately transparent. It's important to provide the right level of transparency to people who use the system, so that they can make informed decisions around the use of the system.
- Provide system documentation. Produce and provide educational materials for your system, including explanations of its capabilities and limitations. For example, this could be in the form of a "learn more" page accessible via the system.
- Publish user guidelines and best practices. Help users and stakeholders use the system appropriately by publishing best practices, for example on prompt crafting, reviewing generations before accepting them, etc. Such guidelines can help people understand how the system works. When possible, incorporate the guidelines and best practices directly into the UX.
As you implement mitigations to address potential identified harms, it's important to develop a process for ongoing measurement of the effectiveness of such mitigations, to document measurement results, and to review those measurement results to continually improve the system.
Operate
Once measurement and mitigation systems are in place, we recommend that you define and execute a deployment and operational readiness plan. This stage includes completing appropriate reviews of your system and mitigation plans with relevant stakeholders, establishing pipelines to collect telemetry and feedback, and developing an incident response and rollback plan.
Some recommendations for how to deploy and operate a system that uses the Azure OpenAI service with appropriate, targeted harms mitigations include:
Work with compliance teams within your organization to understand what types of reviews are required for your system and when they are required (for example, legal review, privacy review, security review, accessibility review, etc.).
Develop and implement the following:
- Develop a phased delivery plan. We recommend you launch systems using the Azure OpenAI service gradually using a "phased delivery" approach. This gives a limited set of people the opportunity to try the system, provide feedback, report issues and concerns, and suggest improvements before the system is released more widely. It also helps to manage the risk of unanticipated failure modes, unexpected system behaviors, and unexpected concerns being reported.
- Develop an incident response plan. Develop an incident response plan and evaluate the time needed to respond to an incident.
- Develop a rollback plan Ensure you can roll back the system quickly and efficiently in case an unanticipated incident occurs.
- Prepare for immediate action for unanticipated harms. Build the necessary features and processes to block problematic prompts and responses as they're discovered and as close to real-time as possible. When unanticipated harms do occur, block the problematic prompts and responses as quickly as possible, develop and deploy appropriate mitigations, investigate the incident, and implement a long-term solution.
- Develop a mechanism to block people who are misusing your system. Develop a mechanism to identify users who violate your content policies (for example, by generating hate speech) or are otherwise using your system for unintended or harmful purposes, and take action against further abuse. For example, if a user frequently uses your system to generate content that is blocked or flagged by content safety systems, consider blocking them from further use of your system. Implement an appeal mechanism where appropriate.
- Build effective user feedback channels. Implement feedback channels through which stakeholders (and the general public, if applicable) can submit feedback or report issues with generated content or that otherwise arise during their use of the system. Document how such feedback is processed, considered, and addressed. Evaluate the feedback and work to improve the system based on user feedback. One approach could be to include buttons with generated content that would allow users to identify content as "inaccurate," "harmful" or "incomplete." This could provide a more widely used, structured and feedback signal for analysis.
- Telemetry data. Identify and record (consistent with applicable privacy laws, policies, and commitments) signals that indicate user satisfaction or their ability to use the system as intended. Use telemetry data to identify gaps and improve the system.
This document is not intended to be, and should not be construed as providing, legal advice. The jurisdiction in which you're operating may have various regulatory or legal requirements that apply to your AI system. Consult a legal specialist if you are uncertain about laws or regulations that might apply to your system, especially if you think those might impact these recommendations. Be aware that not all of these recommendations and resources are appropriate for every scenario, and conversely, these recommendations and resources may be insufficient for some scenarios.
Learn more about responsible AI
- Microsoft AI principles
- Microsoft responsible AI resources
- Microsoft Azure Learning courses on responsible AI