你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
summarize 运算符
适用于:✅Microsoft Fabric✅Azure 数据资源管理器Azure Monitor✅Microsoft✅ Sentinel
生成可聚合输入表内容的表。
语法
T | summarize [ SummarizeParameters ] [[Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| 列 | string |
结果列的名称。 默认为派生自表达式的名称。 | |
| 聚合 | string |
✔️ | 对聚合函数(例如 count() 或 avg())的调用,以列名作为参数。 |
| GroupExpression | 标量 (scalar) | ✔️ | 一个可以引用输入数据的标量表达式。 所有组表达式有多少个不同的值,输出就会包含多少个记录。 |
| SummarizeParameters | string |
零个或多个空格分隔 Name = Value 形式的参数,用于控制行为。 请参阅支持的参数。 |
注意
当输入表为空时,输出取决于是否使用了 GroupExpression:
- 如果未提供 GroupExpression,则输出将为单个(空)行。
- 如果提供了 GroupExpression,则输出将不包含任何行。
支持的参数
| 名称 | 描述 |
|---|---|
hint.num_partitions |
指定用于在群集节点上共享查询负载的分区数。 请参阅随机执行查询 |
hint.shufflekey=<key> |
shufflekey 查询使用键将数据分区,在群集节点上共享查询负载。 请参阅 shuffle 查询 |
hint.strategy=shuffle |
shuffle 策略查询会在群集节点上共享查询负载,其中的每个节点将处理一个数据分区。 请参阅 shuffle 查询 |
返回
输入行将排列成与 by 表达式具有相同值的组。 然后,对每个组计算指定的聚合函数,从而为每组生成行。 结果包含 by 列,还至少包含用于每个计算聚合的一列。 (某些聚合函数返回多个列。)
结果有许多行,因为 by 值(可能为零)存在不同的组合。 如果未提供任何组键,则结果将包含单个记录。
若要基于数值范围进行汇总,请使用 bin() 将范围减小为离散值。
注意
- 尽管可为聚合和分组表达式提供任意表达式,但使用简单列名称或将
bin()应用于数值列会更加高效。 - 不再支持自动地每小时对日期/时间列进行分箱。 请改用显式分箱。 例如
summarize by bin(timestamp, 1h)。
聚合的默认值
下表汇总了聚合的默认值:
| 运算符 | 默认值 |
|---|---|
count()、、countif()、dcountif()dcount()、count_distinct()、sum()、sumif()variance()、、varianceif()、、 stdev()stdevif() |
0 |
make_bag()、、make_bag_if()make_list()、make_list_if()、make_set()、make_set_if() |
空的动态数组 ([]) |
| 所有其他 | 空 |
注意
将这些聚合应用于包含 null 值的实体时,将忽略 null 值,并且不会将其纳入计算。 有关示例,请参阅聚合默认值。
示例
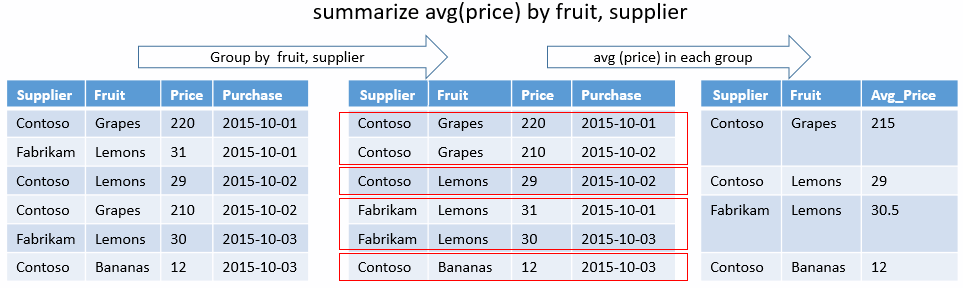
唯一组合
以下查询确定存在哪些造成人员直接受伤的风暴的 State 和 EventType 的唯一组合。 没有聚合函数,只是有分组依据键。 输出将只显示这些结果的列。
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
输出
下表仅显示了前 5 行。 若要查看完整输出,请运行查询。
| 状态 | EventType |
|---|---|
| 德克萨斯 | 雷雨大风 |
| 德克萨斯 | 山洪 |
| 德克萨斯 | 冬季天气 |
| 德克萨斯 | 疾风 |
| 德克萨斯 | 洪水 |
| ... | ... |
最小和最大时间戳
查找夏威夷州的最小和最大暴风雨。 没有 group-by 子句,因此输出中只有一行。
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
输出
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
非重复计数
以下查询会计算每个状态的唯一风暴事件类型数,并按唯一风暴类型数对结果进行排序:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
输出
下表仅显示了前 5 行。 若要查看完整输出,请运行查询。
| 状态 | TypesOfStorms |
|---|---|
| 德克萨斯 | 27 |
| CALIFORNIA | 26 |
| 宾夕法尼亚州 | 25 |
| 佐治亚州 | 24 |
| ILLINOIS | 23 |
| ... | ... |
直方图
以下示例计算持续时间超过 1 天的风暴的直方图风暴事件类型。 由于 Duration 有许多值,因此请使用 bin() 将它的值按 1 天的间隔分组。
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
输出
| EventType | Length | EventCount |
|---|---|---|
| Drought | 30.00:00:00 | 1646 |
| 野火 | 30.00:00:00 | 11 |
| 热 | 30.00:00:00 | 14 |
| 洪水 | 30.00:00:00 | 20 |
| 暴雨 | 29.00:00:00 | 42 |
| ... | ... | ... |
对默认值进行聚合
当 summarize 运算符的输入至少有一个空的分组依据键时,其结果也将为空。
如果 summarize 运算符的输入没有空的分组依据键,则结果将是在 summarize 中使用的聚合的默认值。有关详细信息,请参阅聚合的默认值。
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
输出
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
avg_x(x) 的结果为 NaN,因为被除以 0。
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
输出
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
输出
| set_x | list_x |
|---|---|
| [] | [] |
聚合平均值运算会对所有非 null 值求和,只计算参与计算的那些值(不会将 null 值考虑在内)。
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
输出
| sum_y | avg_y |
|---|---|
| 15 | 5 |
常规计数会将 null 计在内:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
输出
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
输出
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |