你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
What are common scenarios for using table update policies
Applies to: ✅ Microsoft Fabric ✅ Azure Data Explorer
This section describes some well-known scenarios that use update policies. Consider adopting these scenarios when your circumstances are similar.
In this article, you learn about the following common scenarios:
Medallion architecture data enrichment
Update policies on tables provide an efficient way to apply rapid transformations and are compatible with the medallion lakehouse architecture in Fabric.
In the medallion architecture, when raw data lands in a landing table (bronze layer), an update policy can be used to apply initial transformations and save the enriched output to a silver layer table. This process can cascade, where the data from the silver layer table can trigger another update policy to further refine the data and hydrate a gold layer table.
The following diagram illustrates an example of a data enrichment update policy named Get_Values. The enriched data is output to a silver layer table, which includes a calculated timestamp value and lookup values based on the raw data.

Data routing
A special case of data enrichment occurs when a raw data element contains data that must be routed to a different table based on one or more attributes of the data itself.
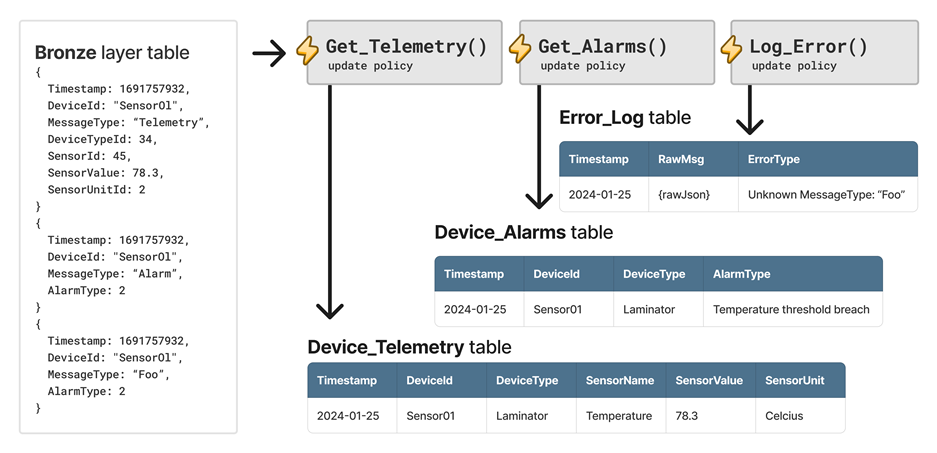
Consider an example that uses the same base data as the previous scenario, but this time there are three messages. The first message is a device telemetry message, the second message is a device alarm message, and the third message is an error.
To handle this scenario, three update policies are used. The Get_Telemetry update policy filters the device telemetry message, enriches the data, and saves it to the Device_Telemetry table. Similarly, the Get_Alarms update policy saves the data to the Device_Alarms table. Lastly, the Log_Error update policy sends unknown messages to the Error_Log table, allowing operators to detect malformed messages or unexpected schema evolution.
The following diagram depicts the example with the three update policies.
Optimize data models
Update policies on tables are built for speed. Tables typically conform to star schema design, which supports the development of data models that are optimized for performance and usability.
Querying tables in a star schema often requires joining tables. However, table joins can lead to performance issues, especially when querying high volumes of data. To improve query performance, you can flatten the model by storing denormalized data at ingestion time.
Joining tables at ingestion time has the added benefit of operating on a small batch of data, resulting in a reduced computational cost of the join. This approach can massively improve the performance of downstream queries.
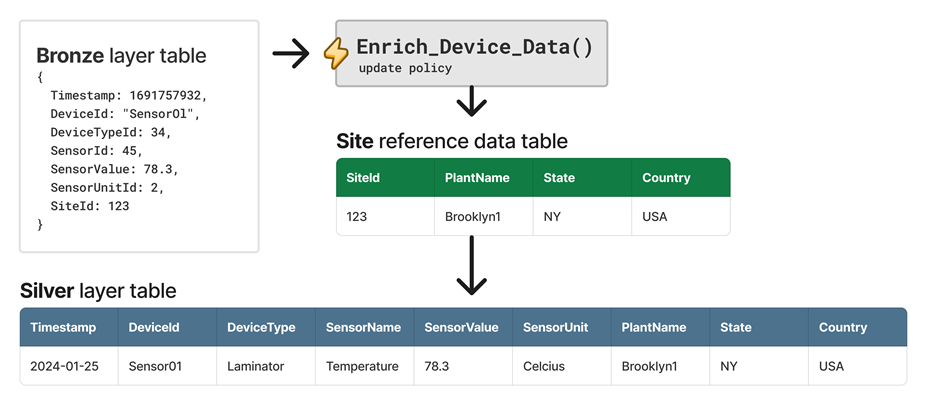
For example, you can enrich raw telemetry data from a device by looking up values from a dimension table. An update policy can perform the lookup at ingestion time and save the output to a denormalized table. Furthermore, you can extend the output with data sourced from a reference data table.
The following diagram depicts the example, which comprises an update policy named Enrich_Device_Data. It extends the output data with data sourced from the Site reference data table.