准备 SDOH 数据集 - 转换(预览版)中的公共数据集
[本文为预发布文档,可能会发生变化。]
SDOH 公共数据集包含由政府机构和其他官方来源(例如大学)发布的已聚合健康的社会决定因素 (SDOH) 数据。 这些数据集在州、县或邮政编码等地理级别整合了各种 SDOH 参数。 通过 SDOH 数据集 - 转换(预览版),您可以采用 CSV(逗号分隔值)或 XLSX(Excel Open XML 电子表格)格式引入这些地理级别的数据集,并将其规范化到自定义数据模型中。
预览版提供了以下 8 个来自各种 SDOH 域的示例 SDOH 数据集,可帮助您运行数据管道并探索通过铜牌、银牌和金牌湖屋层进行的数据转换:
USDA 的食品环境地图集:包括商店/餐厅距离、食物价格、营养援助计划和社区特征等因素。 这些因素会影响食物选择、饮食质量,并最终影响健康状况结果。
USDA 的农村地图集:提供有关社会经济因素的统计信息,例如人员、工作、县分类、收入和退伍军人。
AHRQ 的 SDOH 数据:提供五个关键 SDOH 域的详细信息:
- 社会背景,例如年龄、种族/民族、退伍军人身份。
- 经济背景,例如收入、失业率。
- 教育
- 有形基础设施,例如住房、犯罪、交通。
- 医疗保健背景,例如健康保险。
位置负担能力指数:估计社区层面的家庭住房和交通成本。
环境正义指数:聚合来自多个来源的数据,对每个人口普查区的环境不公正对健康状况的累积影响进行排名。
ACS 教育程度:提供来自正在进行的大型人口统计调查的地理区域的教育见解。
澳大利亚 SEIFA:结合澳大利亚人口普查数据,例如收入、教育、就业和住房,以汇总一个区域的社会经济特征。
英国贫困指数:英国境内广泛使用的社会经济衡量标准,用于评估较小区域的贫困情况,涵盖各个维度。
其中:
- USDA:美国农业部
- AHRQ:医疗保健研究与质量局
- ACS:美国社区调查
- SEIFA:地区社会经济指数
重要提示
这些数据集不仅仅是样本,而是由各组织发布的完整、真实的数据集。 它们提供了其地理区域的 SDOH 概况的准确表示。 修改时要小心,因为它们是联邦机构的官方出版物。
文件夹结构
SDOH 数据集 - 转换(预览版)的登陆区域由三个文件夹组成:Ingest、Process 和 Failed。 若要了解有关这些文件夹的详细信息,请参阅统一文件夹结构。
在引入之前准备 SDOH 数据集
在引入 SDOH 公共数据集之前,请确保它们已准备好成功引入。 以下部分概述了两个应用场景:
- 使用您自己的数据集
- 使用示例数据集
使用您自己的数据集
SDOH 公共数据集在格式、数量和结构方面因发布组织而异。 它们缺乏收集和交换捕获信息的既定标准。 因此,在数据模型中表示数据集之前,将它们统一为一个通用形状至关重要。
若要引入和转换所选的 SDOH 公共数据集,请向其中添加以下三个关键信息:
Layout:由于缺乏用于捕获 SDOH 数据的标准代码集,因此理解每个字段的含义具有挑战性。 若要解决此问题,请通过添加名为 Layout 的新工作表(如果您的数据集采用 XLSX 格式)来为数据集创建数据字典,或者使用以下示例中显示的列创建新的 CSV 文件(如果您的数据集采用 CSV 格式):
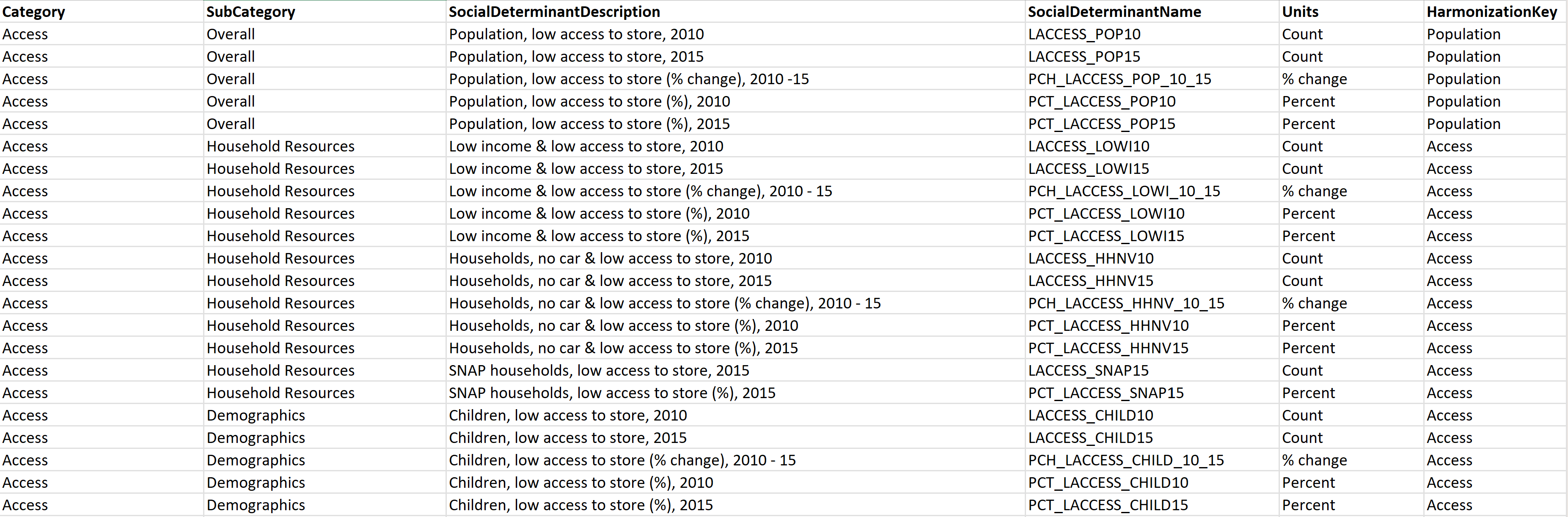
DataSetMetadata:由于 SDOH 数据集来自不同的发布者,因此记录有关数据集的关键详细信息至关重要。 添加名为 DataSetMetadata 的新工作表(如果您的数据集采用 XLSX 格式),或者使用以下示例中显示的列创建新的 CSV 文件(如果您的数据集采用 CSV 格式):

LocationConfiguration:不同的地理位置以不同的方式定义和组织位置数据。 为了帮助 SDOH 管道了解数据集的地理结构,请添加名为 LocationConfiguration 的新工作表(如果您的数据集采用 XLSX 格式),或者使用以下示例中显示的列创建新的 CSV 文件(如果您的数据集采用 CSV 格式):
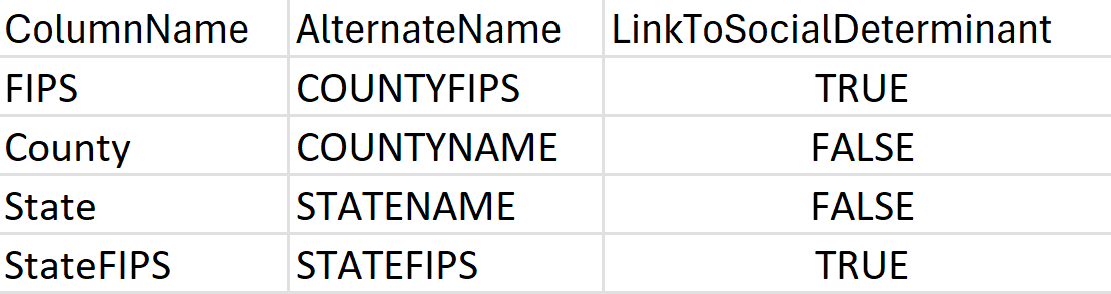



另外:
- 您可以参考示例 SDOH 数据集的结构来填充必要的信息,例如社会决定因素类别、元数据和协调键。
- 如果您不想从原始数据集中引入某些字段,请将其从数据表中删除,或在布局表中将其详细信息保留为空。 在这两种情况下,它们都不包括在银牌数据模型中。
- 具有相同名称、发布日期和发布者的数据集将被视为重复项。
使用示例数据集
医疗保健数据解决方案提供的示例 SDOH 数据集预填充了所有先决条件信息,可在您的 OneLake 中使用。 您可以在本地提取它们。
将数据集上传到 Fabric 工作区
在数据集准备就绪后,选择以下两个选项之一进行上传。 仅当使用 SDOH 数据集 - 转换(预览版)提供的示例数据集时,才使用选项 2。
- 选项 1:手动上传数据集。
- 选项 2:使用脚本上传数据集。
手动上传数据集
在您的医疗保健数据解决方案环境中,选择 healthcare#_msft_bronze 湖屋。
打开 Ingest 文件夹。 若要了解详细信息,请参阅文件夹说明。
选择文件夹名称旁边的省略号 (...),然后选择上传文件夹。
从本地系统上传数据集。 使用 OneLake 文件资源管理器在以下路径中查找数据集:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset。刷新 Ingest 文件夹。 现在,您应该在 SDOH 子文件夹中看到数据集文件。
使用脚本上传数据集
重要提示
仅当使用提供的示例数据集时,才使用此选项。
转到您的医疗保健数据解决方案 Fabric 工作区。
选择 + 新建项目。
在新建项目窗格中,搜索并选择笔记本。
将以下代码片段复制到笔记本中:
workspace_name = '<workspace_name>' # workspace name one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint solution_name = "<solution_name>" # solution name bronze_lakehouse_name = "<bronze_lakehouse_name>" # bronze lakehouse name def copy_source_files_and_folders(source_path, destination_path): source_contents = mssparkutils.fs.ls(source_path) # list the source directory contents # list the destination directory contents try: if mssparkutils.fs.exists(destination_path): destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} else: print(f"Destination path {destination_path} does not exist.") destination_files = {} except Exception as e: print(f" Error: {str(e)}") destination_files = {} # copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" # recursively copy the contents of the directory if item.isDir: copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_name}@{one_lake_endpoint}/{solution_name}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/XLSX" # copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)运行笔记本。 示例 SDOH 数据集现在移动到 Ingest 文件夹中的指定位置。
SDOH 数据集现在已准备好进行引入。